Poniedziałek, 8 kwietnia 2013 r.
Dodanie linku rel=canonical na stronie wskazuje wyszukiwarkom, która wersja ma być preferowana podczas indeksowania powielonych stron w internecie.
Atrybut ten jest obsługiwany przez kilka wyszukiwarek, między innymi Yahoo!,
Bing i Google. Link rel=canonical łączy właściwości indeksowania duplikatów, np. ich linki przychodzące, a także określa, który adres URL ma być wyświetlany w wynikach wyszukiwania. Atrybut rel=canonical może jednak być nieco kłopotliwy, ponieważ nie jest zbyt oczywiste, kiedy występuje błędna konfiguracja.
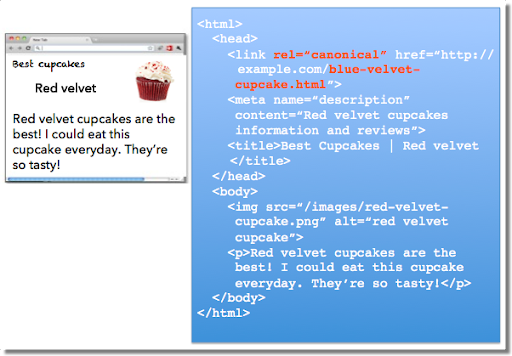
Po lewej stronie w przeglądarce webmaster widzi stronę „czerwone aksamitne”, ale wyszukiwarki zauważają niezamierzony przez webmastera atrybut rel=canonical „niebieskie aksamitne” po prawej stronie. Zalecamy stosowanie tych sprawdzonych metod korzystania z atrybutu rel=canonical:
- W wersji kanonicznej powinna znajdować się duża część treści powielonej strony.
-
Dokładnie sprawdź, czy element docelowy atrybutu
rel=canonicalistnieje (nie jest to błąd ani „soft 404”). -
Sprawdź, czy element docelowy atrybutu
rel=canonicalnie zawiera tagu noindex robotsmeta. -
Zadbaj, aby w wynikach wyszukiwania pojawiał się adres URL z atrybutem
rel=canonical(a nie duplikat adresu URL). -
Umieść link
rel=canonicalw sekcji<head>strony lub w nagłówku HTTP. -
Określ nie więcej niż 1 atrybut
rel=canonicaldla strony. Jeśli określisz ich więcej, wszystkie linkirel=canonicalzostaną zignorowane.
Błąd 1. Atrybut rel=canonical wskazuje na pierwszą stronę serii podzielonej na strony
Załóżmy, że masz artykuł składający się z kilku stron:
- example.com/article?story=cupcake-news&page=1
- example.com/article?story=cupcake-news&page=2
- i tak dalej
Określenie atrybutu rel=canonical ze strony 2 (lub dowolnej z następnych) do strony 1 nie jest prawidłowym sposobem użycia tagu rel=canonical, ponieważ nie są to powielone strony. Użycie w tym przypadku atrybutu rel=canonical spowoduje, że treści na stronach 2 i kolejnych w ogóle nie zostaną zindeksowane.

rel=canonical ze stron składowych na pierwszą stronę serii, nastąpi utrata wartościowych treści (np. „ciastka odżywiają lepiej” i „niż warzywa”).

rel=canonical ze stron składowych na stronę z całą zawartością
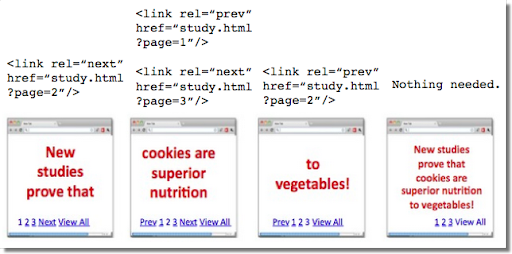
rel=canonical na stronę z całą zawartością nie jest określony, w treści podzielonej na strony można użyć znaczników rel="prev" i rel="next".
Błąd 2. Bezwzględne adresy URL przez pomyłkę zapisane jako względne

Tag <link>, podobnie jak wiele tagów HTML, akceptuje zarówno względne, jak i bezwzględne adresy URL. Względne adresy URL obejmują ścieżkę „względną” do bieżącej strony. Na przykład images/cupcake.png oznacza „z bieżącego katalogu przejdź do podkatalogu images, a następnie do cupcake.png”. Bezwzględne adresy URL określają pełną ścieżkę, łącznie ze schematem takim jak https://.
Określenie <link rel=canonical href="example.com/cupcake.html" /> (jest to względny adres URL, ponieważ nie ma parametru https://) oznacza, że żądanym kanonicznym adresem URL jest https://example.com/example.com/cupcake.html, chociaż prawie na pewno nie o to chodziło. W takich przypadkach nasze algorytmy mogą ignorować podany atrybut rel=canonical. Ogólnie oznacza to, że Twoje oczekiwania co do tego atrybutu rel=canonical nie przyniosą efektu.
Błąd 3. Niezamierzone lub wielokrotne deklaracje atrybutu rel=canonical
Od czasu do czasu widzimy oznaczenia rel=canonical, które naszym zdaniem są niezamierzone. W bardzo rzadkich przypadkach widzimy proste literówki, ale zwykle właściciel witryny kopiuje szablon strony bez zastanowienia się nad zmianą elementu docelowego atrybutu rel=canonical. Teraz strony właściciela witryny określają atrybut rel=canonical prowadzący do witryny autora szablonu.
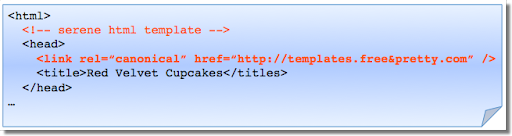
Jeśli używasz szablonu, sprawdź, czy nie została skopiowana też specyfikacja rel=canonical.
Innym problemem jest sytuacja, gdy strony zawierają kilka linków rel=canonical do różnych adresów URL. Zdarza się to często w połączeniu z wtyczkami SEO, które nierzadko wstawiają domyślny link rel=canonical prawdopodobnie bez wiedzy webmastera, który zainstalował wtyczkę.
W przypadku większej liczby deklaracji rel=canonical Google prawdopodobnie zignoruje wszystkie wskazówki rel=canonical. Utracisz wszelkie korzyści z użycia prawidłowego atrybutu rel=canonical.
W obu tych przypadkach dokładne sprawdzenie kodu źródłowego strony powinno rozwiązać problem.
Sprawdź całą sekcję <head>, bo linki rel=canonical mogą znajdować się w różnych miejscach.
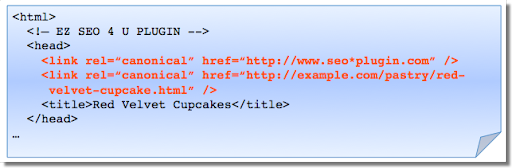
Działanie wtyczek możesz sprawdzić w kodzie źródłowym strony.
Błąd 4. Kategoria lub strona docelowa określa atrybut rel=canonical, który odnosi się do polecanego artykułu
Załóżmy, że prowadzisz witrynę na temat deserów. Twoja witryna z deserami ma przydatne strony kategorii, np. „ciastka” i „lody”. Każdego dnia na stronach kategorii pojawia się niepowtarzalny artykuł. Na przykład na Twojej stronie docelowej z ciastkami mogą znaleźć się „czerwone aksamitne babeczki”. Zawartość strony kategorii „ciastka” jest prawie taka sama jak strony „czerwone aksamitne babeczki”, dlatego musisz dodać atrybut rel=canonical ze strony kategorii odnoszący się do polecanego konkretnego artykułu.
Gdybyśmy przyjęli ten atrybut rel=canonical, strona kategorii ciastek nie pojawiłaby się w wynikach wyszukiwania. Wynika to z tego, że rel=canonical wskazuje, że wyszukiwarki powinny wyświetlać kanoniczny URL w miejsce duplikatu. Jeśli jednak chcesz, aby użytkownicy mogli znaleźć zarówno stronę kategorii, jak i polecany artykuł, najlepiej jest umieścić na stronie kategorii tylko odsyłający do siebie atrybut rel=canonical lub nie umieszczać żadnego atrybutu.
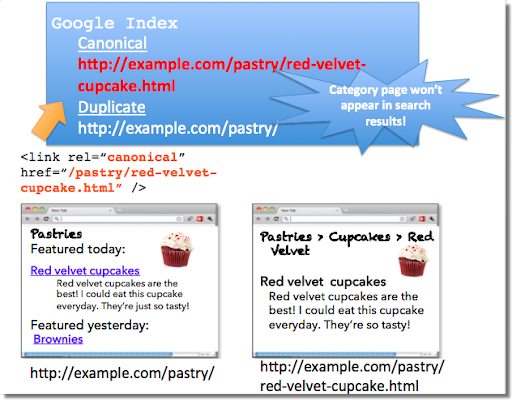
Pamiętaj, że oznaczenie strony kanonicznej również oznacza preferowany wyświetlany adres URL. Nie dodawaj atrybutu rel=canonical z kategorii lub strony docelowej do polecanego artykułu.
Błąd 5. Atrybut rel=canonical w tagu <body>
Tag linku rel=canonical powinien występować tylko w sekcji <head> dokumentu HTML. Aby uniknąć problemów z analizą kodu HTML, warto uwzględnić w elemencie <head> atrybut rel=canonical jak najbliżej początku. Jeśli w elemencie <body> napotkamy oznaczenie rel=canonical, zostanie ono zignorowane.
Ten błąd można łatwo poprawić. Sprawdź, czy linki rel=canonical znajdują się zawsze w sekcji <head> na Twojej stronie jak najbliżej początku.
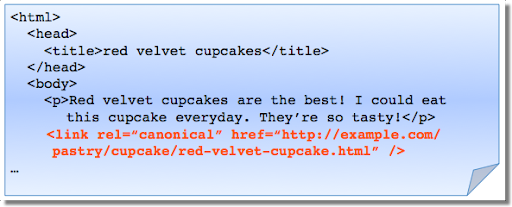
Przetwarzane są oznaczenia rel=canonical w sekcji <head>, a nie <body>.
Podsumowanie
Aby utworzyć wartościowe oznaczenia rel=canonical:
- Sprawdź, czy większość głównej treści tekstowej zduplikowanej strony znajduje się również na stronie kanonicznej.
-
Sprawdź, czy atrybut
rel=canonicalzostał określony tylko raz (jeśli w ogóle) i czy znajduje się w elemencie<head>strony. -
Sprawdź, czy
rel=canonicalwskazuje istniejący adres URL z wartościową treścią (czyli nie404ani, co gorsza,soft 404). -
Nie określaj parametru
rel=canonicalze stron docelowych lub stron kategorii do polecanych artykułów, ponieważ sprawi to, że polecany artykuł będzie preferowanym adresem URL w wynikach wyszukiwania.
Jak zwykle zachęcamy do zadawania pytań na naszym forum pomocy dla webmasterów.