Wednesday, October 07, 2009
Today we're excited to propose a new standard for making AJAX-based websites crawlable. This will benefit webmasters and users by making content from rich and interactive AJAX-based websites universally accessible through search results on any search engine that chooses to take part. We believe that making this content available for crawling and indexing could significantly improve the web.
While AJAX-based websites are popular with users, search engines traditionally are not able to access any of the content on them. The last time we checked, almost 70% of the websites we know about use JavaScript in some form or another. Of course, most of that JavaScript is not AJAX, but the better that search engines could crawl and index AJAX, the more that developers could add richer features to their websites and still show up in search engines.
Some of the goals that we wanted to achieve with this proposal were:
- Minimal changes are required as the website grows
- Users and search engines see the same content (no cloaking)
- Search engines can send users directly to the AJAX URL (not to a static copy)
- Site owners have a way of verifying that their AJAX website is rendered correctly and thus that the crawler has access to all the content
Here's how search engines would crawl and index AJAX in our initial proposal:
-
Slightly modify the URL fragments for stateful AJAX pages
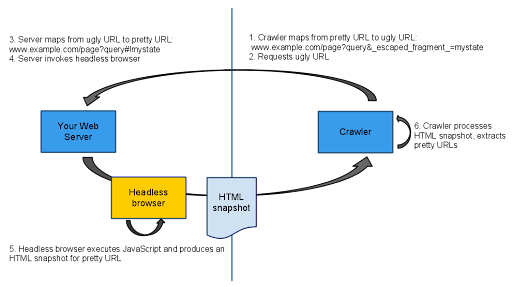
Stateful AJAX pages display the same content whenever accessed directly. These are pages that could be referred to in search results. Instead of a URL likehttps://example.com/page?query#statewe would like to propose adding a token to make it possible to recognize these URLs:https://example.com/page?query#[FRAGMENTTOKEN]state. Based on a review of current URLs on the web, we propose using "!" (an exclamation point) as the token for this. The proposed URL that could be shown in search results would then be:https://example.com/page?query#!state. -
Use a headless browser that outputs an HTML snapshot on your web server
The headless browser is used to access the AJAX page and generates HTML code based on the final state in the browser. Only specially tagged URLs are passed to the headless browser for processing. By doing this on the server side, the website owner is in control of the HTML code that is generated and can easily verify that all JavaScript is executed correctly. An example of such a browser is HtmlUnit, an open-sourced "GUI-less browser for Java programs. -
Allow search engine crawlers to access these URLs by escaping the state
As URL fragments are never sent with requests to servers, it's necessary to slightly modify the URL used to access the page. At the same time, this tells the server to use the headless browser to generate HTML code instead of returning a page with JavaScript. Other, existing URLs - such as those used by the user - would be processed normally, bypassing the headless browser. We propose escaping the state information and adding it to the query parameters with a token. Using the previous example, one such URL would behttps://example.com/page?query&[QUERYTOKEN]=state. Based on our analysis of current URLs on the web, we propose using_escaped_fragment_as the token. The proposed URL would then becomehttps://example.com/page?query&_escaped_fragment_=state. -
Show the original URL to users in the search results
To improve the user experience, it makes sense to refer users directly to the AJAX-based pages. This can be achieved by showing the original URL (such ashttps://example.com/page?query#!statefrom our example above) in the search results. Search engines can check that the indexable text returned to Googlebot is the same or a subset of the text that is returned to users.
In summary, starting with a stateful URL such as
https://example.com/dictionary.html#AJAX, it could be available to both crawlers and
users as https://example.com/dictionary.html#!AJAX which could be crawled as
https://example.com/dictionary.html?_escaped_fragment_=AJAX which in turn would be
shown to users and accessed as https://example.com/dictionary.html#!AJAX
We're currently working on a proposal and a prototype implementation. Feedback is very welcome—please add your comments below or in our Webmaster Help Forum. Thank you for your interest in making the AJAX-based web accessible and useful through search engines!