Mittwoch, 10. April 2013
Mit dem
rel=canonical-Tag
in einem Link könnt ihr eure Inhalte als bevorzugt gegenüber anderen indexierten
duplizierten Inhalten
hervorheben. Diese Funktion wird von mehreren Suchmaschinen inklusive
Yahoo!
,
Bing
, und Google unterstützt. Die rel=canonical-Angabe hilft dabei, bestimmte Eigenschaften von Duplikaten zusammenzuführen, z. B. die eingehenden Links und bestimmt darüber hinaus, welche URL-Version in den Suchergebnissen bevorzugt gezeigt werden soll. Jedoch kann die Verwendung des rel=canonical Tags auch knifflig sein, vor allem wenn es nicht besonders offensichtlich ist, ob ggf. eine falsche Einbindung vorliegt.

Wir empfehlen die folgenden Praxis-Tipps für die Verwendung von rel=canonical:
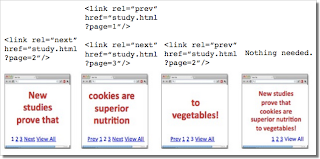
1. Fehler: rel=canonical auf die erste Seite einer nummerierten Reihe an Seiten angewandt
Beispielsweise könnte eure Webseite folgende Seitenstruktur verwenden:

Für eine Abfolge an Seiten oder nummerierte Webseiten empfehlen wir entweder ein rel=canonical von den Serienseiten zu einer einseitigen Version aller Inhalte oder Seitennummerierung mit rel="prev" und rel="next" .

2. Fehler: Absolute URLs als relative URLs verwendet
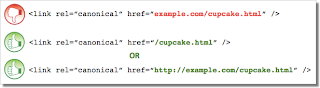
Das <link>-Tag erlaubt wie die meisten HTML-Tags absolute sowie relative URLs. Der Pfad von relativen URLs bezieht sich auf einen Pfad von der aktuellen Webseite ausgehend. Zum Beispiel “images/cupcake.png” gibt an vom aktuellen Pfad in den "images" Ordner zu gehen und dann zu "cupcake.png". Absolute URLs beschreiben den gesamten Pfad inklusive "https://".
Das folgende Tag <link rel=canonical href=“example.com/cupcake.html” /> (ein relativer URL-Pfad, da kein "https://") geht von https:// example.com/example.com /cupcake.html als gewünschter kanonischer URL aus, obwohl dies sicherlich nicht beabsichtigt wäre. In solchen Fällen können unsere Algorithmen das rel=canonical ggf. ignorieren. Dies bedeutet, dass der Webmaster seine Absicht nicht erfolgreich umsetzen konnte.
3. Fehler: Unbeabsichtigte oder mehrfache Verwendung von rel=canonical
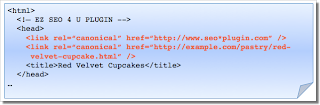
Gelegentlich begegnen wir rel=canonical Zielseiten, welche mit hoher Wahrscheinlichkeit unbeabsichtigt sind. In sehr seltenen Fällen ist dies bedingt durch Rechtschreibfehler. Häufig kopiert einer der beschäftigten Webmaster eine Seite ohne die Zielseite des rel=canonical-Tags anzugleichen. Die Webseite des Webmasters verwendet dann rel=canonical für das Website-Template zum Beispiel.
Ein weiteres Problem besteht, wenn mehrere Seiten rel=canonical Links zu verschiedenen URLs enthalten. Dies geschieht häufig in Verbindung mit SEO Plugins, die oft standardmäßig und möglicherweise vom Webmaster unbemerkt, einen rel=canonical Link mit der Installation einfügen. Bei mehreren rel=canonical-Tags auf einer Seite wird Google wahrscheinlich alle rel=canonical-Tags ignorieren. Somit wäre eine legitime rel=canonical-Einbindung leider nicht erreicht.
In beiden Fällen hilft es, den Quelltext der Webseite zu überprüfen und gegebenfalls zu korrigieren. Es ist ratsam, Inhalte im gesamten <head> zu überprüfen, da die rel=canonical-Links verteilt sein können.
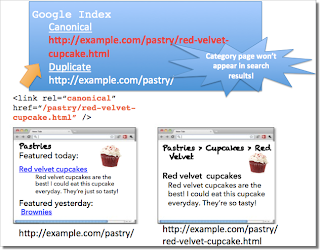
4. Fehler: Kategorien-Seite linkt mit rel=canonical zu Kategorien-Unterseite
Angenommen, Ihr betreibt eine Webseite über Desserts. Die Webseite verfügt über nützliche Kategorien wie "Gebäck" und "Eis". Die Kategorien-Seiten bieten täglich einzigartige Artikel an. Zum Beispiel werden auf eurer Webseite unter Gebäck "Red Velvet Cupcakes" angeboten. Da die Gebäck-Unterseite fast den gleichen Inhalt wie die "Red Velvet Cupcake"-Seite hat, fügt ihr ein rel=canonical von der Kategorien-Seite zu der Einzelseite mit dem vorgestellten Artikel hinzu.
Dies würde darin resultieren, dass die Gebäck Kategorien-Seite nicht in den Suchergebnissen angezeigt würde. Dies passiert, weil das rel=canonical den Suchmaschinen signalisiert, lieber die kanonische URL anzuzeigen anstelle der duplizierten. Sofern beide Webseiten auffindbar sein sollen, ist es am besten, nur ein selbstverweisendes rel=canonical auf der Kategorien-Seite anzuwenden oder auch gar keines.
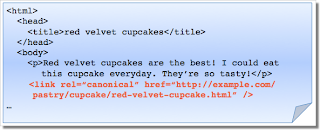
5. Fehler: rel=canonical im <body>
Das rel=canonical-Link-Element sollte nur im <head> eines HTML-Dokuments erscheinen. Um HTML-Parsing-Probleme zu vermeiden, ist es ebenfalls gut, wenn das rel=canonical so früh wie möglich im <head> steht. Wenn wir einem rel=canonical im <body> begegnen, wird es nicht berücksichtigt.
Dieser potentielle Fehler is einfach zu korrigieren. Überprüft einfach, ob sich die rel=canonical-Links im <head> befinden und ob sie so früh wie möglich auftauchen.
Zusammenfassung
Um das rel=canonical effizient anzuwenden:
Post von Allan Scott, Software Engineer, Indexing Team (Übersetzung von Johannes Mehlem , Search Quality Team)
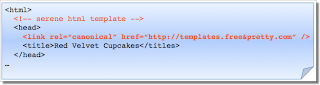
Während der Webmaster links die "red velvet" Seite im Browser sieht, bemerken Suchmaschinen das unbeabsichtigte "blue velvet" rel=canonical, wie rechts dargestellt.
Wir empfehlen die folgenden Praxis-Tipps für die Verwendung von rel=canonical:
-
Die Mehrheit der Inhalte auf der duplizierten Webseite sollte auch auf der kanonischen Version vorhanden sein.
Ein "Test" kann hier sein, wenn ihr euch vorstellt, die Sprache des Inhalts nicht zu verstehen: Wenn ihr das Duplikat direkt mit der kanonischen Version vergleicht, taucht dann ein Großer Prozentsatz der Worte des Duplikats auch auf der kanonischen Version auf? Wenn ihr die Fremdsprache beherrschen müsstet, um eine Ähnlichkeit festzustellen, da das Thema sich zwar ähnelt aber die Wortwahl sich nicht gleicht, könnte das rel=canonical-Tag unter Umständen nicht von Suchmaschinen interpretiert werden. - Vergewissert euch, dass die rel=canonical Zielseite auch wirklich existiert (dies bedeutet weder ein Fehlerstatus noch "falsche" 404-Fehler )
- Überprüft ob die rel=canonical Zielseite eventuell fälschlicherweise ein noindex Robots-Meta-Tag enthält
- Gewährleistet, dass ihr tatsächlich die URL mit rel=canonical in den Suchergebnissen sehen wollt (und nicht das Duplikat)
- Fügt den rel=canonical-Link entweder im <head>-Bereich der Seite oder im HTTP-Header ein
- Verwendet nicht mehr als ein rel=canonical pro Seite, da bei mehreren Tags alle verwendeten rel=canonical auf einer Seite ignoriert werden
1. Fehler: rel=canonical auf die erste Seite einer nummerierten Reihe an Seiten angewandt
Beispielsweise könnte eure Webseite folgende Seitenstruktur verwenden:
- example.com/article?story=cupcake-news&seite=1
- example.com/article?story=cupcake-news&seite=2
- und so weiter
Gute Inhalte (z.B. "cookies are superior nutrition" and "to vegetables") gehen verloren, wenn rel=canonical von einer der Folgeseiten auf die erste Seite der Reihe linkt.
Für eine Abfolge an Seiten oder nummerierte Webseiten empfehlen wir entweder ein rel=canonical von den Serienseiten zu einer einseitigen Version aller Inhalte oder Seitennummerierung mit rel="prev" und rel="next" .
rel=canonical von Seiten einer Reihe zur Gesamtansicht
Sofern rel=canonical nicht zur Gesamtansicht verlinkt, können rel="prev" und rel="next"-Tags für nummerierte Webseiten verwendet werden.
2. Fehler: Absolute URLs als relative URLs verwendet
Das <link>-Tag erlaubt wie die meisten HTML-Tags absolute sowie relative URLs. Der Pfad von relativen URLs bezieht sich auf einen Pfad von der aktuellen Webseite ausgehend. Zum Beispiel “images/cupcake.png” gibt an vom aktuellen Pfad in den "images" Ordner zu gehen und dann zu "cupcake.png". Absolute URLs beschreiben den gesamten Pfad inklusive "https://".
Das folgende Tag <link rel=canonical href=“example.com/cupcake.html” /> (ein relativer URL-Pfad, da kein "https://") geht von https:// example.com/example.com /cupcake.html als gewünschter kanonischer URL aus, obwohl dies sicherlich nicht beabsichtigt wäre. In solchen Fällen können unsere Algorithmen das rel=canonical ggf. ignorieren. Dies bedeutet, dass der Webmaster seine Absicht nicht erfolgreich umsetzen konnte.
3. Fehler: Unbeabsichtigte oder mehrfache Verwendung von rel=canonical
Gelegentlich begegnen wir rel=canonical Zielseiten, welche mit hoher Wahrscheinlichkeit unbeabsichtigt sind. In sehr seltenen Fällen ist dies bedingt durch Rechtschreibfehler. Häufig kopiert einer der beschäftigten Webmaster eine Seite ohne die Zielseite des rel=canonical-Tags anzugleichen. Die Webseite des Webmasters verwendet dann rel=canonical für das Website-Template zum Beispiel.
Wenn ihr ein Template verwendet, vergewissert euch, dass das rel=canonical Tag nicht auch kopiert wurde.
Ein weiteres Problem besteht, wenn mehrere Seiten rel=canonical Links zu verschiedenen URLs enthalten. Dies geschieht häufig in Verbindung mit SEO Plugins, die oft standardmäßig und möglicherweise vom Webmaster unbemerkt, einen rel=canonical Link mit der Installation einfügen. Bei mehreren rel=canonical-Tags auf einer Seite wird Google wahrscheinlich alle rel=canonical-Tags ignorieren. Somit wäre eine legitime rel=canonical-Einbindung leider nicht erreicht.
In beiden Fällen hilft es, den Quelltext der Webseite zu überprüfen und gegebenfalls zu korrigieren. Es ist ratsam, Inhalte im gesamten <head> zu überprüfen, da die rel=canonical-Links verteilt sein können.
Überprüft den Quelltext nach Einbindung eines Plug-ins
4. Fehler: Kategorien-Seite linkt mit rel=canonical zu Kategorien-Unterseite
Angenommen, Ihr betreibt eine Webseite über Desserts. Die Webseite verfügt über nützliche Kategorien wie "Gebäck" und "Eis". Die Kategorien-Seiten bieten täglich einzigartige Artikel an. Zum Beispiel werden auf eurer Webseite unter Gebäck "Red Velvet Cupcakes" angeboten. Da die Gebäck-Unterseite fast den gleichen Inhalt wie die "Red Velvet Cupcake"-Seite hat, fügt ihr ein rel=canonical von der Kategorien-Seite zu der Einzelseite mit dem vorgestellten Artikel hinzu.
Dies würde darin resultieren, dass die Gebäck Kategorien-Seite nicht in den Suchergebnissen angezeigt würde. Dies passiert, weil das rel=canonical den Suchmaschinen signalisiert, lieber die kanonische URL anzuzeigen anstelle der duplizierten. Sofern beide Webseiten auffindbar sein sollen, ist es am besten, nur ein selbstverweisendes rel=canonical auf der Kategorien-Seite anzuwenden oder auch gar keines.
Bedenkt, dass die kanonische Webseite auch als bevorzugte URL für die Ansicht in den Suchergebnissen fungiert. Vermeidet rel=canonical Links von einer Kategorien-Seite zu einer Kategorien-Unterseite.
5. Fehler: rel=canonical im <body>
Das rel=canonical-Link-Element sollte nur im <head> eines HTML-Dokuments erscheinen. Um HTML-Parsing-Probleme zu vermeiden, ist es ebenfalls gut, wenn das rel=canonical so früh wie möglich im <head> steht. Wenn wir einem rel=canonical im <body> begegnen, wird es nicht berücksichtigt.
Dieser potentielle Fehler is einfach zu korrigieren. Überprüft einfach, ob sich die rel=canonical-Links im <head> befinden und ob sie so früh wie möglich auftauchen.
Ausschließlich rel=canonical-Tags im <head> haben einen Effekt.
Zusammenfassung
Um das rel=canonical effizient anzuwenden:
- Vergewissert euch, dass der Großteil der Wörter im Duplikat der Seite auch in der kanonischen Seite auftaucht.
- Überprüft, ob das rel=canonical-Tag nur einmal (wenn überhaupt) und nur im <head> der Seite verwandt wird.
- Prüft, ob rel=canonical auf eine vorhandene URL mit guten Inhalten verweist (keine 404, oder sogar eine "falsche" 404-Seite).
- Vermeidet das rel=canonical-Tag von Landingpages oder Kategorien-Seiten zu Kategorien-Unterseite oder beispielsweise Produkt-Unterseiten, da die Unterseite somit in der Ansicht der Suchergebnisse bevorzugt würde.
Post von Allan Scott, Software Engineer, Indexing Team (Übersetzung von Johannes Mehlem , Search Quality Team)