Jeudi 1er septembre 2011
Nous nous sommes fixé comme mission d'organiser les informations du monde pour les rendre universellement accessibles et utiles. Dans le cadre de cette tâche ambitieuse, nous rencontrons parfois des fichiers non-HTML tels que des fichiers PDF, des feuilles de calcul et des présentations. Nos algorithmes ne laissent pas ces différents types de fichiers les ralentir ; nous travaillons dur pour extraire les contenus pertinents et les indexer de manière appropriée pour nos résultats de recherche. Mais comment indexons-nous ces types de fichiers et, puisqu'ils sont souvent très différents des fichiers HTML standards, quelles consignes appliquons-nous pour les traiter ? Que se passe-t-il si un webmaster ne souhaite pas que nous indexions ces fichiers ?
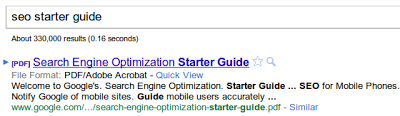
Google a commencé à indexer les fichiers PDF en 2001. Aujourd'hui, ces fichiers PDF indexés se comptent par centaines de millions. Voici les réponses aux questions les plus fréquentes à propos de l'indexation des fichiers PDF :
Q : Google peut-il indexer n'importe quel type de fichier PDF ?
R : En règle générale, nous sommes en mesure d'indexer les contenus textuels (quelle que soit la langue dans laquelle ils ont été écrits) des fichiers PDF qui utilisent différents types d'encodages des caractères, à condition qu'ils ne soient pas protégés par un mot de passe ni chiffrés. Si un texte est intégré sous forme d'images, nous pouvons traiter ces images à l'aide d'algorithmes de reconnaissance optique des caractères pour extraire le texte. En règle générale, si vous pouvez copier et coller le texte d'un document PDF dans un document texte standard, alors nous pouvons indexer ce texte.
Q : Qu'en est-il des images présentes dans les fichiers PDF ?
R : Actuellement, les images ne sont pas indexées. Pour que nous puissions indexer vos images, vous devez les faire figurer sur des pages HTML. Afin d'augmenter les chances qu'elles s'affichent dans nos résultats de recherche, veuillez lire les bonnes pratiques Google Images.
Q : Comment les liens présents dans les documents PDF sont-ils traités ?
R : En règle générale, les liens figurant dans les fichiers PDF sont traités de la même manière que les liens HTML (en renvoyant des signaux PageRank et d'autres signaux d'indexation). Nous pouvons les suivre après avoir exploré le fichier PDF. Il est actuellement impossible d'utiliser des liens nofollow dans un document PDF.
Q : Comment puis-je empêcher mes fichiers PDF d'apparaître dans les résultats de recherche ? S'ils y apparaissent déjà, comment puis-je les supprimer des résultats de recherche ?
R : Le moyen le plus simple d'empêcher l'affichage de documents PDF dans les résultats de recherche consiste à ajouter X-Robots-Tag: noindex dans l'en-tête HTTP utilisé pour diffuser le fichier. S'ils sont déjà indexés, ils seront abandonnés au fil du temps si vous utilisez la commande X-Robot-Tag avec la règle noindex. Pour accélérer leur disparition des résultats de recherche, vous pouvez utiliser l'outil de suppression d'URL disponible dans les outils Google pour les webmasters.
Q : Est-il possible d'améliorer le classement de fichiers PDF dans les résultats de recherche ?
R : Bien sûr ! Ils obéissent aux mêmes mécanismes de classement que les autres pages Web. Par exemple, à l'heure où nous publions cet article, une recherche sur les mots mortgage market review, irs form 2011 ou paracetamol expert report renvoie des documents PDF très bien classés dans nos résultats de recherche, grâce à leur contenu et à la manière dont ils sont intégrés et liés à d'autres pages Web
Q : Si mes pages sont disponibles à la fois au format HTML et au format PDF, risquent-elles d'être considérées comme du contenu dupliqué ?
R : Dans la mesure du possible, nous vous recommandons de diffuser une seule copie de vos contenus. Si cela n'est pas possible, veillez à indiquer la version que vous préférez, par exemple en incluant votre URL préférée dans votre sitemap ou en indiquant la version canonique dans le code HTML ou l'en-tête HTTP de la ressource PDF. Pour obtenir d'autres conseils, consultez l'article consacré au choix de l'URL canonique dans notre centre d'aide.
Q : Comment puis-je influencer le titre indiqué dans les résultats de recherche pour mon document PDF ?
R : Nous utilisons deux éléments principaux pour déterminer le titre affiché : les métadonnées de titre dans le fichier et le texte d'ancrage des liens redirigeant vers le fichier PDF. Pour signaler à nos algorithmes le titre que vous souhaitez qu'ils prennent en compte, nous vous recommandons de mettre à jour ces deux éléments.
Pour en savoir plus, visionnez la vidéo de Matt Cutt sur l'optimisation des fichiers PDF pour les résultats de recherche et découvrez dans notre Centre d'aide les types de contenus que nous pouvons indexer. Si vous avez des commentaires ou des suggestions, n'hésitez pas à nous en faire part dans le Forum d'aide pour les webmasters.