2009年6月24日水曜日
ウェブマスターヘルプフォーラム
に、Googlebot や robots.txt に関する質問が多く寄せられたので、少々古い記事にはなりますが、
2006 年に英語版ウェブマスターセントラルブログに掲載された記事
が、皆様の参考になればと、抄訳して掲載します。
サイトをメンテナンスのために落としています。Googebot に「メンテナンス中」のページをインデックスさせるのではなく、後でクロールに戻って来るよう伝えたいのですが、どうしたらいいですか?
サーバーが、200 (成功)ではなく、503 (ネットワーク利用不可) の HTTP ステータスコード を返すように設定してください。こうすることで、Googlebot はまた別の機会にクロールを試みるようになります。
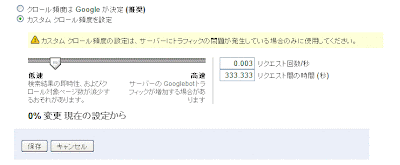
Googlebot がサイトをクロールする負荷が高すぎる場合はどうしたらいいのですか?
ウェブマスターツール内 [サイト設定] の [クロール速度] セクションで、希望のオプションを選択していただくことができます。
Robots メタタグと robots.txt ファイルはどちらを使うのが望ましいのですか?
Googlebot はどちらの指示にも従いますが、robots メタタグはページ毎に記述する必要があります。もしクロールされたくないページが多数ある場合は、robots.txt ファイルを使って一度にそれら複数のページへのアクセスをブロックできるようサイトを構成すると、設定が簡単になります(例えば、それらのページをひとつのディレクトリにまとめるなど)。
Robots.txt に、全ての検索エンジンのボット(クローラ)を対象にした記述と、Googlebot のみを対象にした記述が混在している場合、全ての検索エンジンを対象にした記述を Googlebot はどのように解釈するのですか?
あるサイトの robots.txt に、全てのボット向けの指示と、Googlebot に限定した指示の両方が含まれている場合、Googlebot は後者を優先します。
例えば、次のような記述の robots.txt ファイルがある場合、
次のような記述の robots.txt ファイルがある場合は、
あなたのサイトの robots.txt ファイルを Googlebot がどのように解釈しているかは、ウェブマスターツールの robots.txt のテスト を使って確認することができます。また、robots.txt ファイルに変更を加えた場合、Googlebot がどのように解釈するようになるかについても、このツールで試すことができます。

Googlebot (や Google のその他のクローラ群)がどのように robots.txt を解釈するかについて、より詳しく知りたい方は ヘルプセンター をご参照下さい。
サイトをメンテナンスのために落としています。Googebot に「メンテナンス中」のページをインデックスさせるのではなく、後でクロールに戻って来るよう伝えたいのですが、どうしたらいいですか?
サーバーが、200 (成功)ではなく、503 (ネットワーク利用不可) の HTTP ステータスコード を返すように設定してください。こうすることで、Googlebot はまた別の機会にクロールを試みるようになります。
Googlebot がサイトをクロールする負荷が高すぎる場合はどうしたらいいのですか?
ウェブマスターツール内 [サイト設定] の [クロール速度] セクションで、希望のオプションを選択していただくことができます。
Robots メタタグと robots.txt ファイルはどちらを使うのが望ましいのですか?
Googlebot はどちらの指示にも従いますが、robots メタタグはページ毎に記述する必要があります。もしクロールされたくないページが多数ある場合は、robots.txt ファイルを使って一度にそれら複数のページへのアクセスをブロックできるようサイトを構成すると、設定が簡単になります(例えば、それらのページをひとつのディレクトリにまとめるなど)。
Robots.txt に、全ての検索エンジンのボット(クローラ)を対象にした記述と、Googlebot のみを対象にした記述が混在している場合、全ての検索エンジンを対象にした記述を Googlebot はどのように解釈するのですか?
あるサイトの robots.txt に、全てのボット向けの指示と、Googlebot に限定した指示の両方が含まれている場合、Googlebot は後者を優先します。
例えば、次のような記述の robots.txt ファイルがある場合、
User-agent: *
Disallow: /
User-agent: Googlebot
Disallow: /cgi-bin/
次のような記述の robots.txt ファイルがある場合は、
User-agent: *
Disallow: /
あなたのサイトの robots.txt ファイルを Googlebot がどのように解釈しているかは、ウェブマスターツールの robots.txt のテスト を使って確認することができます。また、robots.txt ファイルに変更を加えた場合、Googlebot がどのように解釈するようになるかについても、このツールで試すことができます。
Googlebot (や Google のその他のクローラ群)がどのように robots.txt を解釈するかについて、より詳しく知りたい方は ヘルプセンター をご参照下さい。