2023 年 6 月 5 日(月曜日)
Search Console の一括データ エクスポートは、ウェブサイトの検索パフォーマンス データを BigQuery に取り込んで、ストレージ、分析、レポートの機能を強化できる優れた手法です。たとえば、データをエクスポートしてから、クエリと URL のクラスタリングの実行、ロングテール検索クエリに対する分析の実行、検索の別のデータソースとの結合を行えます。また、データは任意の期間にわたって保持することができます。
一括データ エクスポートを使用する場合、データ処理とストレージの費用の管理を行う際には情報に基づいた意思決定を行うことが重要です。Search Console でデータをエクスポートすることに関して費用が発生することはありませんが、何に対して料金が発生するのかを BigQuery の料金で事前にご確認ください。この記事では、高額な費用を負担することなく新しいデータを活用するためのヒントを説明します。
一括データ エクスポートをまだ設定していない場合は、Search Console ヘルプセンターの手順ガイドをご覧ください。エクスポートで利用できるデータの概要については、こちらの埋め込み動画をご覧ください。
請求アラートと制限を作成する
費用について検討する際は、どの程度の出費まで許容できるのかをよく考えることをおすすめします。許容額は、ストレージ、分析、モニタリングごとに異なるはずです。たとえば、すべてのデータを保存できるようにするためにはある程度の出費は許容できても、レポート用のプラットフォームの作成には出費を抑えたいと考えることもあるでしょう。検討する際には、検索データに割り振る 1 か月の予算を設定することをおすすめします。
予算額を決めたら、Google Cloud 予算アラートを設定して想定外の請求が発生しないようにすることができます。また、予算額に近づいたときにメール通知をトリガーするしきい値のルールを設定することもできます。
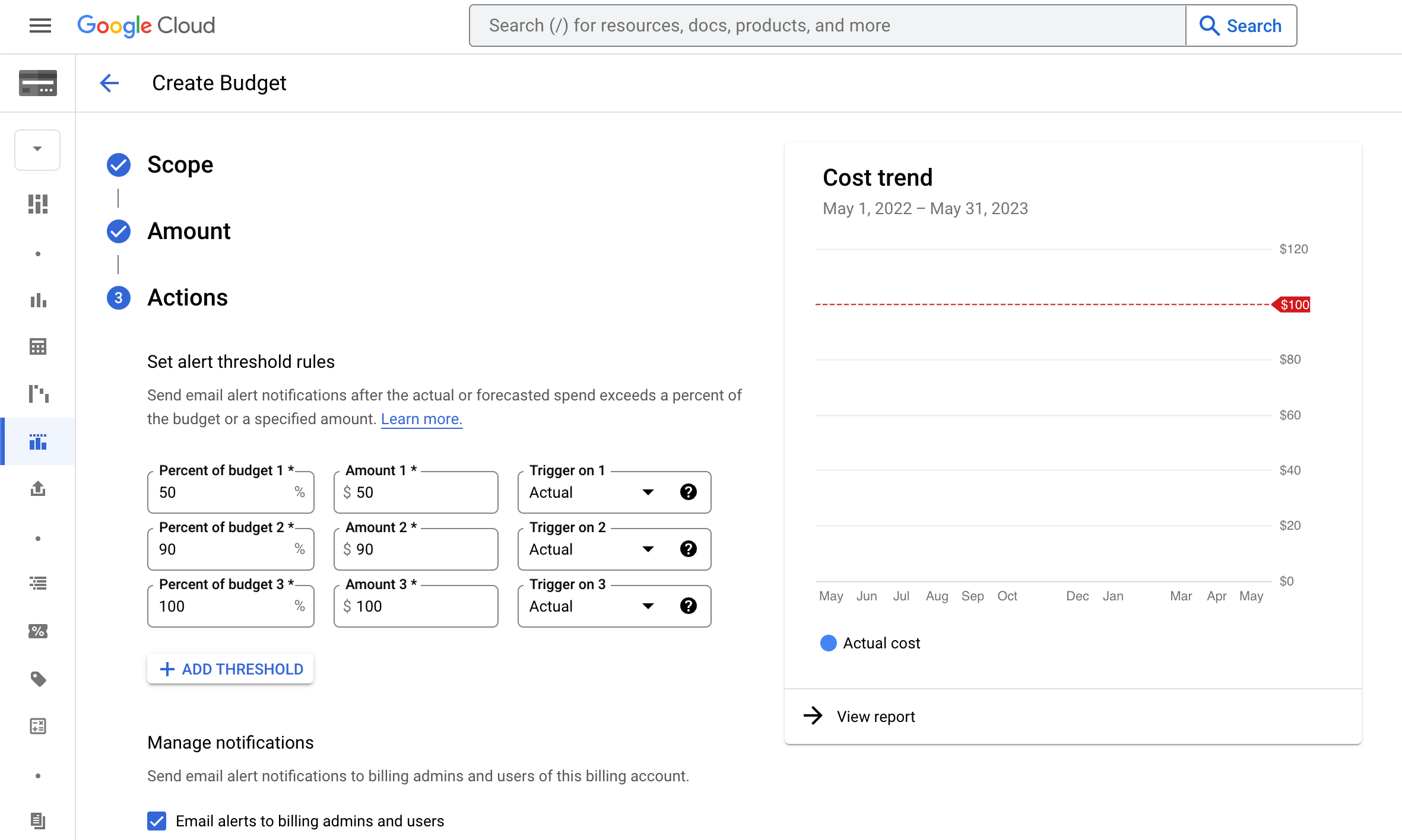
これ以外にも、想定外の請求を回避する手段として、1 つのクエリで請求されるバイト数を制限することもできます。制限を設定すると、クエリの実行前に、そのクエリが読み取るバイト数が見積もられます。見積もられたバイト数が上限を超えている場合、そのクエリは失敗し、料金は発生しません。
元データに直接ダッシュボードを構築しない
BigQuery は高速処理ができるため、ダッシュボードと Search Console のエクスポートされたテーブルを直接リンクしたくなるかもしれません。しかしながら、大規模なサイトの場合、(特に時間のかかるクエリを使う場合で)このデータセットのサイズが非常に大きくなる可能性があります。各ビューの概要情報を再計算するダッシュボードを構築してその情報を会社内で共有する場合、すぐにクエリの費用が高額になってしまいます。
このような費用を避けるために、日ごとのデータを事前に集計して、1 つ以上の概要テーブルをマテリアライズすることをおすすめします。このようにすることで、サイズが大幅に小さい時系列テーブルがダッシュボードでクエリされるようになり、処理にかかる費用が削減されます。
BigQuery のクエリのスケジュール設定機能をご確認ください。自動のソリューションの使用を考えている場合は、BI Engine をおすすめします。
データ ストレージの費用を最適化する
一括データ エクスポートを開始すると、デフォルトではデータが BigQuery データセットに永久に保持されます。ただ、デフォルトのパーティション有効期限を更新して、1 年後、16 か月後など、特定の期日になった後に日付パーティションが自動的に削除されるようにすることもできます。
エクスポートしたデータは有益なものです。ただしサイズが非常に大きくなる可能性があります。ビジネス上の観点を考慮して、詳細な分析を行うために十分な期間保持します。ただし、負担になるほどに長期間保存しないようにします。方法のひとつとして、古いテーブルはサンプル バージョンとして維持して、それ以降の日付のテーブルは全体を維持することがあります。
SQL クエリを最適化する
Search Console のデータをクエリする際、パフォーマンスのためにクエリを最適化する必要があります。BigQuery を初めて利用する場合は、ヘルプセンターのガイドラインとサンプルクエリをご覧ください。次の 3 つの方法をお試しください。
1. 入力スキャンを制限する
まず、SELECT * を使用しないようにします。これは、データをクエリする手段として最も費用のかかる方法で、BigQuery がテーブル内のすべての列のフルスキャンを実行します。LIMIT 句を適用しても、読み取られるデータの量に影響しません。
エクスポートされるデータは日付パーティション分割されているため、入力スキャンを目的の日付に限定できます。これは、データをテストして検討する際には特に有効です。WHERE 句を使用して、日付パーティション分割テーブルの期間を制限すると、クエリ費用が大幅に削減されます。たとえば、次の句を使用して、過去 14 日間のみを参照できます。
WHERE data_date between DATE_SUB(CURRENT_DATE(), INTERVAL 14 day)
作成するすべてのクエリで、既知のフィルタを可能な限り早めに導入して入力スキャンを減らします。たとえば、クエリを分析する場合に、匿名化されたクエリ行をフィルタリングして除外できます。匿名化されたクエリは、テーブルで長さが 0 の文字列として報告されます。これを行うには、以下を追加します。
WHERE query != ''
2. データをサンプリングする
BigQuery にはテーブルのサンプリング機能があり、大規模な BigQuery テーブルからランダムなデータのサブセットをクエリできます。サンプリングではさまざまなレコードを取得でき、それでいてテーブル全体のスキャンと処理にかかる費用を回避できます。これは、クエリの開発時や正確な結果が要求されない場合に特に有効です。
3. 正確な結果が要求されない場合に近似関数を使用する
BigQuery では、推定結果を取得できる数多くの近似集計関数がサポートされており、これを使用することで正確な値を計算する場合よりも費用が大幅に低くなります。たとえば、インプレッションで上位の URL を特定の条件で探す場合に、
SELECT APPROX_TOP_SUM(url, impressions, 10) WHERE datadate=...;
を使用して、以下を使わないようにすることもできます。
SELECT url, SUM(impressions) WHERE datadate=... GROUP BY url ORDER BY 2 DESC LIMIT 10;
参考資料
これらは、費用を抑えるためのヒントの一部にすぎません。詳細については、BigQuery におけるコスト最適化のベスト プラクティスをご覧ください。
ご質問やご不明な点がございましたら、Google 検索セントラル コミュニティまたは Twitter を利用してお問い合わせください。