2011 年 9 月 1 日(木曜日)
Google の使命は、世界中の情報を体系化し、アクセス可能で有益なものにすることです。この壮大な取り組みの中では、PDF、スプレッドシート、プレゼンテーションなど、HTML 以外のファイルを処理しなければならないこともあります。Google のアルゴリズムは、異なるファイル形式でも速度を落とすことはありません。Google は、そのような場合も関連するコンテンツを抽出し、適切にインデックス登録して検索結果に表示するよう努めています。それでは、このようなファイル形式は、実際どのようにインデックス登録されるのでしょうか。また、標準の HTML とは通常大きく異なるファイル形式に対して、どのようなガイドラインが適用されるのでしょうか。さらに、インデックス登録を避けたい場合はどうすればよいのでしょうか。
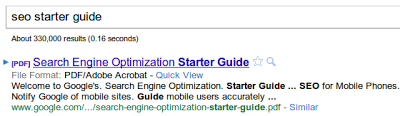
Google が PDF ファイルのインデックス登録を開始したのは 2001 年で、現在は何億という PDF ファイルがインデックス登録されています。以下に、PDF のインデックス登録に関するよくある質問と回答を集めました。
Q: Google はどのような形式の PDF ファイルでもインデックス登録できますか?
A: 基本的に、テキスト コンテンツであれば、言語を問わずさまざまな文字エンコードの PDF ファイルからインデックス登録できます。ただし、パスワードで保護されているものや暗号化されているものは除きます。テキストが画像として埋め込まれている場合、OCR アルゴリズムによる画像処理でテキストを抽出することもあります。目安としては、テキストを PDF ドキュメントからコピーして標準のテキスト ドキュメントに貼り付けられる場合は、インデックス登録できるはずです。
Q: PDF ファイル内の画像についてはどうですか?
A: 現時点では、画像はインデックス登録されません。画像がインデックス登録されるようにするには、画像の HTML ページを作成する必要があります。Google の検索結果に画像が表示される可能性を高めるには、Google 画像検索でのおすすめの方法をご覧ください。
Q: PDF ドキュメント内のリンクはどのように処理されますか?
A: 通常、PDF ファイル内のリンクは HTML 内のリンクと同様に扱われます。つまり、PageRank などのインデックス登録シグナルを渡すことで、また PDF ファイルのクロール後に Google がリンクをたどることがあります。現在のところ、PDF ドキュメント内で nofollow リンクを使用することはできません。
Q: 検索結果に PDF ファイルが表示されないようにするにはどうすればよいですか?また、すでに表示されている場合は、どうすれば削除できますか?
A: 検索結果に PDF ドキュメントが表示されないようにする簡単な方法は、ファイルの提供に使用する HTTP ヘッダーに X-Robots-Tag: noindex を含めることです。すでにインデックス登録されている場合も、X-Robot-Tag に noindex ルールを指定すれば、しばらくして削除されます。より早く削除するには、Google ウェブマスター ツールの URL 削除ツールを使用します。
Q: PDF ファイルでも検索結果の上位にランク付けされることは可能ですか?
A: もちろん可能です。基本的に、PDF ファイルも他のウェブページと同じようにランク付けされます。たとえば、この投稿の時点で「mortgage market review」、「irs form 2011」、「paracetamol expert report」と検索すると、すべて PDF ドキュメントが上位にランク付けされた検索結果が返されます。これは、それぞれのコンテンツと、他のウェブページからの埋め込みやリンクのされ方がそれにふさわしいためです。
Q: ページに HTML 版と PDF 版の両方がある場合、重複コンテンツと見なされますか?
A: 可能な限り、提供するコンテンツの版は 1 つにすることをおすすめします。それが難しい場合は、必ず優先バージョンを指定してください。それには、サイトマップに優先 URL を含める、HTML または PDF リソースの HTTP ヘッダーに正規バージョンを指定するなどの方法があります。その他のヒントについては、正規化に関するヘルプセンターの記事をご覧ください。
Q: 検索結果に表示される PDF ドキュメントのタイトルに影響を与えるにはどうすればよいですか?
表示されるタイトルの決定に使われる主な要素は 2 つあります。ファイル内のタイトル メタデータと、PDF ファイルへのリンクのアンカー テキストです。表示に適したタイトルについて Google のアルゴリズムに強く働きかけるには、この両方を更新するようおすすめします。
詳しくは、Matt Cutt による PDF ファイルの検索最適化に関する動画をご覧ください。また、インデックス登録できるコンテンツ形式については、ヘルプセンターでご確認いただけます。ご意見やご提案がありましたら、ウェブマスター ヘルプ フォーラムまでお寄せください。