
אופטימיזציית הביצועים מתחילה בזיהוי מדדים עיקריים, שקשורים בדרך כלל לזמן אחזור ולתפוקה. הוספת מעקב כדי לתעד את המדדים האלה ולעקוב אחריהם חושפת נקודות חולשה באפליקציה. באמצעות מדדים אפשר לבצע אופטימיזציה כדי לשפר את מדדי הביצועים.
בנוסף, כלי מעקב רבים מאפשרים להגדיר התראות על המדדים, כך שתקבלו התראה כשמגיעים לסף מסוים. לדוגמה, אפשר להגדיר התראה כשאחוז הבקשות שנכשלו גדל ביותר מ-x% מהרמות הרגילות. כלי מעקב יכולים לעזור לכם לזהות ביצועים רגילים ולזהות עליות חריגות בזמן האחזור, כמויות שגיאות ומדדי מפתח אחרים. היכולת לעקוב אחרי המדדים האלה חשובה במיוחד במסגרות זמן קריטיות לעסק, או אחרי שקוד חדש יועבר לסביבת הייצור.
זיהוי ערכים של זמן אחזור
הקפידו שממשק המשתמש שלכם יהיה רספונסיבי ככל האפשר, ושימו לב שהמשתמשים מצפים לסטנדרטים גבוהים עוד יותר מאפליקציות לנייד. צריך למדוד את זמן האחזור בשירותים לקצה העורפי ולעקוב אחריו גם כי הוא עלול להוביל לבעיות בתפוקה אם לא מסמנים אותו.
מדדים מומלצים למעקב כוללים את אלה:
- משך הבקשה
- משך הבקשה ברמת פירוט של מערכת משנה (כמו קריאות ל-API)
- משך המשרה
זיהוי מדדי תפוקה
התפוקה היא מדד של המספר הכולל של הבקשות שהוגשו בפרק זמן נתון. זמן האחזור של מערכות המשנה יכול להשפיע על התפוקה, לכן יכול להיות שתצטרכו לבצע אופטימיזציה של זמן האחזור כדי לשפר את התפוקה.
ריכזנו כאן כמה הצעות למדדים שכדאי לעקוב אחריהם:
- שאילתות לשנייה (QPS)
- גודל הנתונים שהועברו בשנייה
- מספר פעולות קלט/פלט בשנייה
- שימוש במשאבים, כמו מעבד (CPU) או שימוש בזיכרון
- גודל העיכוב בעיבוד, כמו Pub/Sub או מספר השרשורים
לא רק הממוצע
טעות נפוצה במדידת ביצועים היא רק הסתכלות על המקרה הממוצע (הממוצע). אומנם האפשרות הזו שימושית, אבל לא מספקת תובנות לגבי ההתפלגות של זמן האחזור. עדיף לעקוב אחרי מדד הביצועים, למשל האחוזון ה-50/75/90/99 למדד.
באופן כללי, ניתן לבצע אופטימיזציה בשני שלבים. קודם כל, מבצעים אופטימיזציה לזמן אחזור באחוזון ה-90. לאחר מכן נבחן את האחוזון ה-99, שידוע גם כזמן אחזור בזנב, – החלק הקטן של הבקשות שנדרש להן הרבה יותר זמן להשלים.
מעקב בצד השרת לקבלת תוצאות מפורטות
פרופיילינג בצד השרת בדרך כלל מועדף למדדי מעקב. בדרך כלל הרבה יותר קל לבצע אינסטרומנטציה בצד השרת, מאפשר גישה לנתונים מפורטים יותר והוא פחות סובל משיבושים שנובעים מבעיות קישוריות.
מעקב דפדפן אחר חשיפה מקצה לקצה
הפרופיילינג של הדפדפן יכול לספק תובנות נוספות לגבי חוויית משתמש הקצה. הוא יכול להראות לאילו דפים יש בקשות איטיות, שלאחר מכן ניתן להתאים למעקב בצד השרת כדי לבצע ניתוח נוסף.
בדוח תזמוני הדפים, Google Analytics כולל מעקב נפרד אחרי זמני הטעינה של דפים. כך תוכלו לקבל מספר תצוגות שימושיות להבנת חוויית המשתמש באתר, במיוחד:
- זמני טעינה של דפים
- זמני טעינה של הפניות אוטומטיות
- זמני תגובה של השרת
מעקב בענן
יש הרבה כלים שבהם תוכלו להשתמש כדי לתעד את מדדי הביצועים של האפליקציה ולעקוב אחריהם. לדוגמה, אתם יכולים להשתמש ב-Google Cloud Logging כדי לתעד מדדי ביצועים בפרויקט ב-Google Cloud, ואז להגדיר לוחות בקרה ב-Google Cloud Monitoring כדי לעקוב אחרי המדדים הרשומים ולפלח אותם.
במדריך הרישום ביומן תוכלו לראות דוגמה לרישום ביומן ב-Google Cloud Logging ממיירט מותאם אישית בספריית הלקוח של Python. כשהנתונים האלה זמינים ב-Google Cloud, אפשר ליצור מדדים בנוסף לנתונים הרשומים, כדי לקבל הרשאות גישה לאפליקציה באמצעות Google Cloud Monitoring. כדי ליצור מדדים באמצעות היומנים שנשלחו ל-Google Cloud Logging, פועלים לפי המדריך ליצירת מדדים מבוססי-יומן בהגדרת המשתמש.
לחלופין, אפשר להשתמש בספריות הלקוח של Monitoring כדי להגדיר מדדים בקוד ולשלוח אותם ישירות ל-Monitoring, בנפרד מהיומנים.
דוגמה למדדים המבוססים על יומנים
נניח שאתם רוצים לעקוב אחרי הערך is_fault כדי להבין טוב יותר שיעורי שגיאות באפליקציה. אפשר לחלץ את הערך is_fault מהיומנים למדד מונה חדש, ErrorCount.
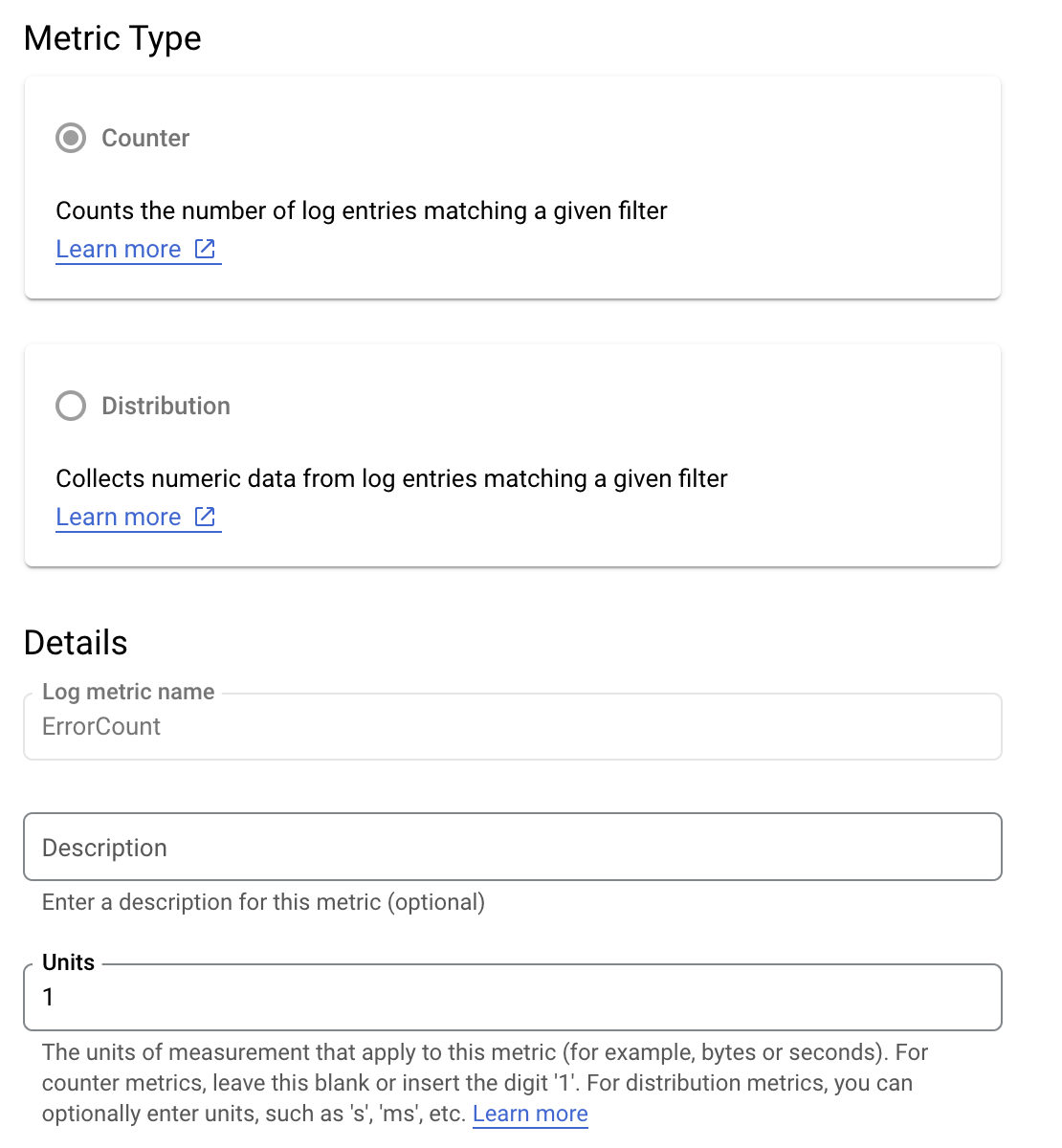
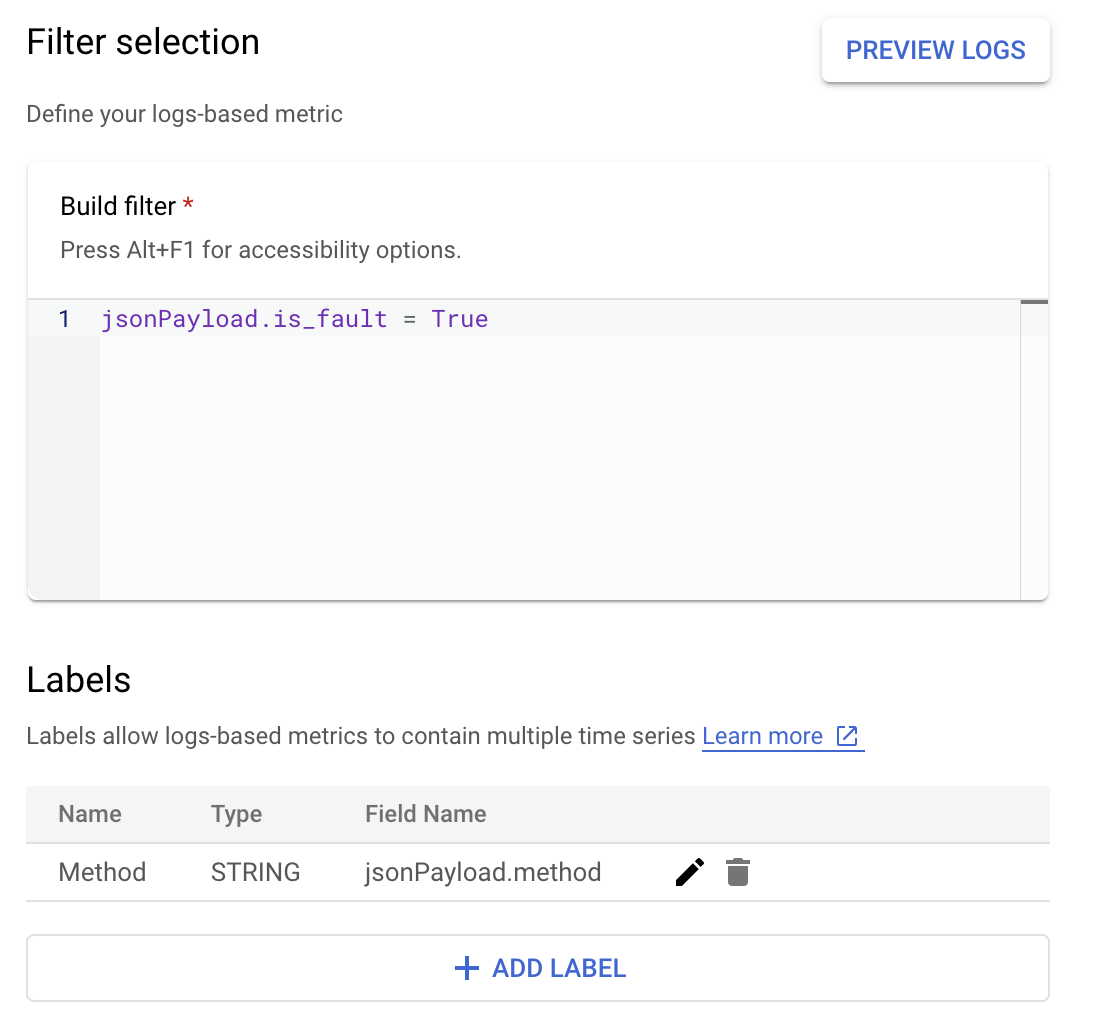
ב-Cloud Logging, תוויות מאפשרות לקבץ את המדדים לקטגוריות על סמך נתונים אחרים ביומנים. תוכלו להגדיר תווית לשדה method שנשלח ל-Cloud Logging כדי לבחון את הפירוט של מספר השגיאות בשיטת Google Ads API.
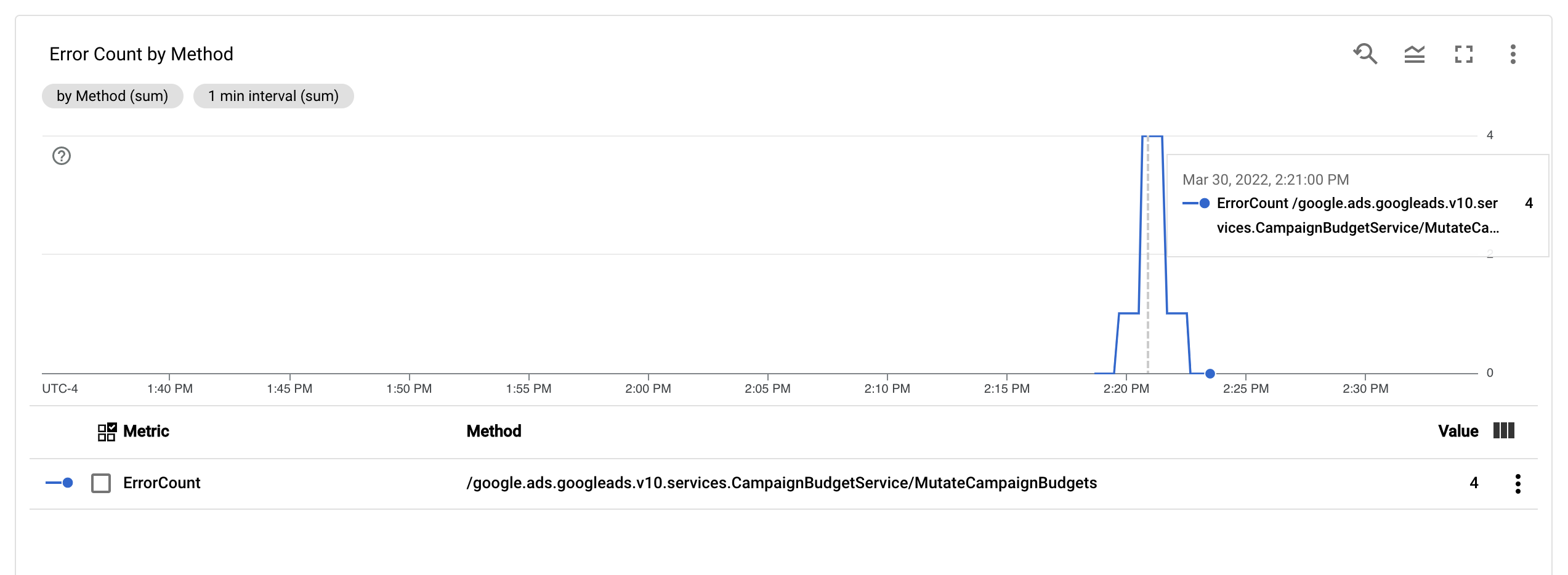
אחרי שמגדירים את המדד ErrorCount והתווית Method, אפשר ליצור תרשים חדש בלוח הבקרה של Monitoring כדי לעקוב אחרי ErrorCount בקיבוץ לפי Method.
התראות
אפשר להגדיר ב-Cloud Monitoring ובכלים אחרים מדיניות התראות שקובעת מתי ואיך התראות יופעלו על ידי המדדים שלכם. להוראות להגדרת התראות של Cloud Monitoring, היעזרו במדריך להתראות.