嵌入是一种相对低维的空间,您可以将高维向量转换为这种低维空间。借助嵌入,可以更轻松地对表示字词的稀疏向量等大型输入进行机器学习。理想情况下,嵌入会将语义上相似的输入置于嵌入空间中彼此靠近的位置,以捕获输入的一些语义。嵌套可以跨模型学习和重复使用。
嵌入
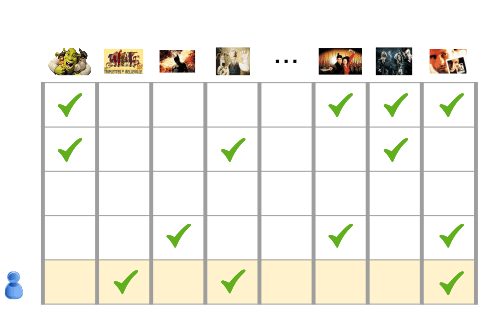
协同过滤的动机
- 输入:50 万个用户已经选择观看的 100 万部影片
- 任务:向用户推荐影片
为了解决此问题,您需要使用一些方法来确定哪些影片彼此相似。
按相似度整理电影(1 天)

按相似度整理影片(2 天)

二维嵌入

二维嵌入

d 维嵌入
- 假设用户对电影的兴趣可以通过 d 个方面大致解释
- 每部电影都变成一个 d 维点,其中维度 d 中的值表示影片与该方面相符的程度
- 可以从数据中学习嵌入
了解深度网络中的嵌套
- 不需要单独的训练过程 - 嵌入层只是一个隐藏层,每个维度一个单元
- 监督式信息(例如,用户观看了两部相同的电影)针对期望的任务定制学习的嵌入
- 隐藏的单元直观地探索了如何整理 d 维空间中的各项,从而以最佳方式优化最终目标
输入表示法
- 每个样本(此矩阵中的一行)都是用户已观看的特征(影片)的稀疏矢量
- 此示例的密集表示形式为:(0, 1, 0, 1, 0, 0, 0, 1)
从空间和时间的角度而言,效率并不高。
输入表示法
- 构建一个字典,将每个特征映射到一个整数,范围为 0、...、# 部电影 - 1
- 将稀疏向量有效地表示为用户观看过的电影。这可以表示为:


深度网络中的嵌套层
预测房屋售价的回归问题:

深度网络中的嵌套层
预测房屋售价的回归问题:

深度网络中的嵌套层
预测房屋售价的回归问题:

深度网络中的嵌套层
预测房屋售价的回归问题:

深度网络中的嵌套层
预测房屋售价的回归问题:

深度网络中的嵌套层
预测房屋售价的回归问题:

深度网络中的嵌套层
用于预测手写数字的多类别分类:

深度网络中的嵌套层
用于预测手写数字的多类别分类:

深度网络中的嵌套层
用于预测手写数字的多类别分类:

深度网络中的嵌套层
用于预测手写数字的多类别分类:

深度网络中的嵌套层
用于预测手写数字的多类别分类:

深度网络中的嵌套层
用于预测手写数字的多类别分类:

深度网络中的嵌套层
用于预测手写数字的多类别分类:

深度网络中的嵌套层
协同过滤以预测推荐的电影:

深度网络中的嵌套层
协同过滤以预测推荐的电影:

深度网络中的嵌套层
协同过滤以预测推荐的电影:

深度网络中的嵌套层
协同过滤以预测推荐的电影:

深度网络中的嵌套层
协同过滤以预测推荐的电影:

深度网络中的嵌套层
协同过滤以预测推荐的电影:

深度网络中的嵌套层
协同过滤以预测推荐的电影:

几何视图对应
深度网络
- 每个隐藏单元都对应一个维度(潜在功能)
- 影片和隐藏层之间的边缘权重是坐标值

单个影片嵌入的几何视图

选择调暗嵌入数量
- 高维度嵌入可以更准确地表示输入值之间的关系
- 但维度越多,过拟合的可能性就越高,训练速度也会越慢
- 经验法则(一个不错的起点,但应使用验证数据进行调整): $$ dimensions \approx \sqrt[4]{possible\;values} $$
嵌入作为工具
- 嵌入会以相似项彼此靠近的方式将项(例如影片、文本等)映射到低维实向量
- 嵌套也可应用于密集数据(如音频),以创建有意义的相似度指标
- 联合嵌入多种数据类型(例如文本、图片、音频等)以定义它们之间的相似性