TensorFlow는 머신러닝용 엔드 투 엔드 오픈소스 플랫폼입니다. TensorFlow는 머신러닝 시스템의 모든 측면을 관리하는 데 사용되는 풍부한 시스템입니다. 이 과정에서는 특정 TensorFlow API를 사용하여 머신러닝 모델을 개발하고 학습시키는 데 중점을 둡니다. 광범위한 TensorFlow 시스템에 관한 자세한 내용은 TensorFlow 문서를 참조하세요.
TensorFlow API는 하위 수준 API를 기반으로 한 상위 수준 API를 사용하여 계층적으로 정렬됩니다. 머신러닝 연구자는 하위 수준의 API를 사용하여 새로운 머신러닝 알고리즘을 만들고 탐색합니다. 이 클래스에서는 머신러닝 모델을 정의 및 학습시키고 예측하는 데 tf.keras라는 상위 수준 API를 사용합니다. tf.keras는 오픈소스 Keras API의 TensorFlow 변형입니다.
다음 그림은 TensorFlow 툴킷의 계층 구조를 보여줍니다.
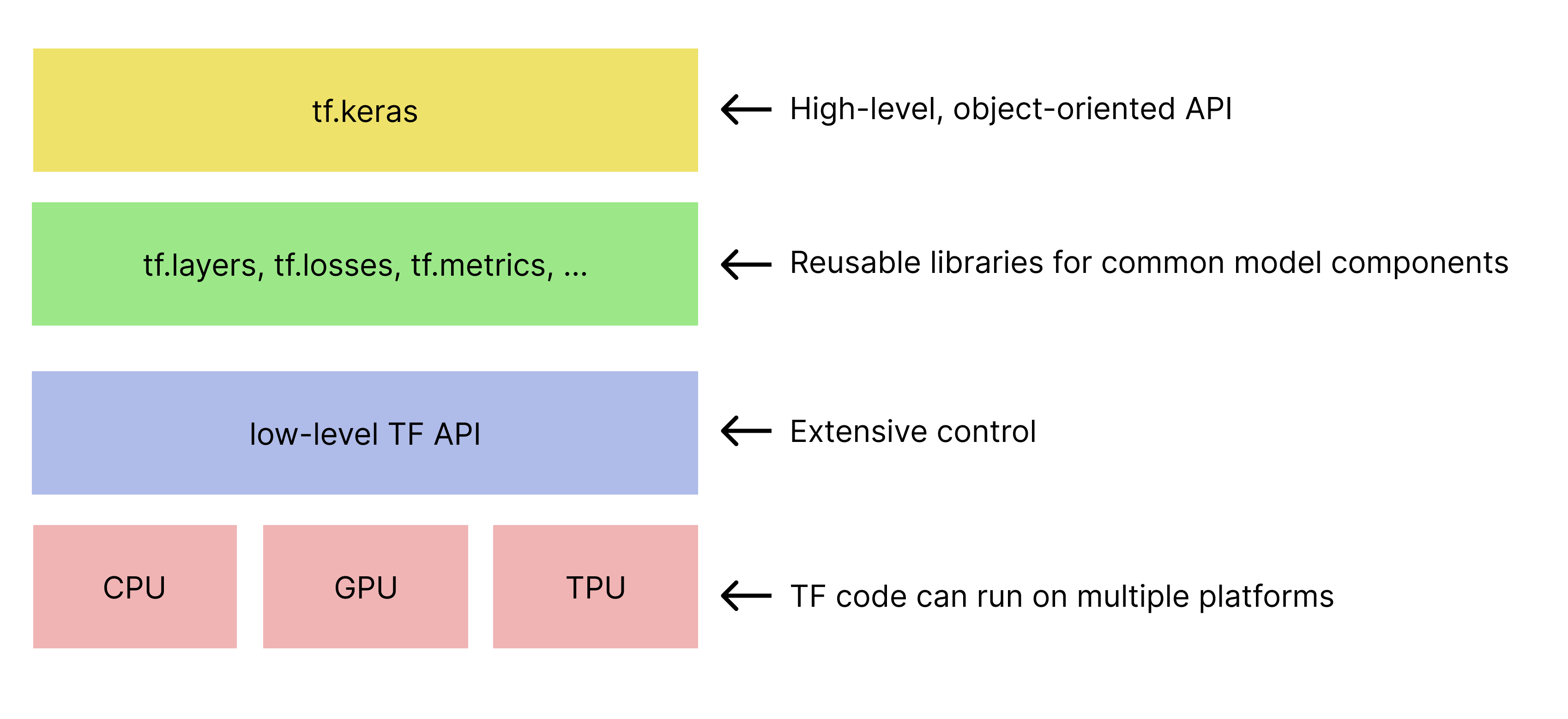
그림 1. TensorFlow 툴킷 계층 구조