이 페이지에는 결정 포레스트 용어가 포함되어 있습니다. 모든 용어집 용어는 여기를 클릭하세요.
A
속성 샘플링
각 결정 트리가 조건을 학습할 때 가능한 특성의 무작위 하위 집합만 고려하는 결정 포레스트를 학습하는 전략입니다. 일반적으로 각 노드에 대해 서로 다른 기능 하위 집합이 샘플링됩니다. 반면 속성 샘플링 없이 결정 트리를 학습할 때는 각 노드에 대해 가능한 모든 특성이 고려됩니다.
축 정렬 조건
결정 트리에서 단일 기능만 포함하는 조건 예를 들어 area가 기능인 경우 축 정렬 조건은 다음과 같습니다.
area > 200
비대칭 조건과 대비되는 개념입니다.
B
bagging
각 구성 모델이 복원 추출로 샘플링된 학습 예의 무작위 하위 집합에서 학습하는 앙상블을 학습하는 방법입니다. 예를 들어 랜덤 포레스트는 배깅으로 학습된 결정 트리의 모음입니다.
배깅이라는 용어는 부트스트랩 애그리게이팅의 줄임말입니다.
자세한 내용은 결정 트리 과정의 랜덤 포레스트를 참고하세요.
이진 조건
결정 트리에서 가능한 결과가 두 개(일반적으로 예 또는 아니요)인 조건입니다. 예를 들어 다음은 이진 조건입니다.
temperature >= 100
비이진 조건과 대비되는 개념입니다.
자세한 내용은 결정 트리 과정의 조건 유형을 참고하세요.
C
조건
결정 트리에서 테스트를 실행하는 노드입니다. 예를 들어 다음 결정 트리에는 두 가지 조건이 포함되어 있습니다.
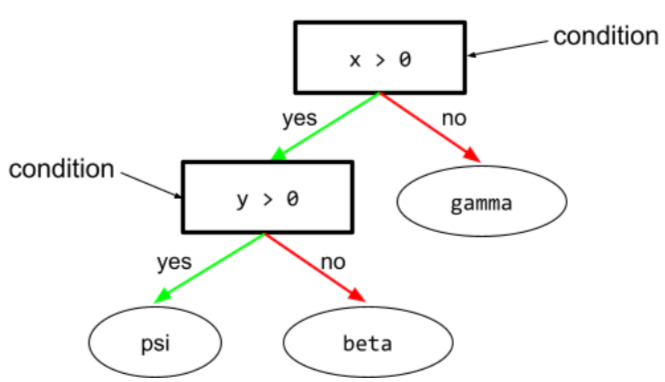
조건을 분할 또는 테스트라고도 합니다.
리프와 대비되는 조건입니다.
관련 주제에 대한 추가 정보
자세한 내용은 결정 트리 과정의 조건 유형을 참고하세요.
D
결정 포레스트
여러 결정 트리로 생성된 모델입니다. 결정 포레스트는 결정 트리의 예측을 집계하여 예측합니다. 인기 있는 결정 트리 유형에는 랜덤 포레스트와 그래디언트 부스티드 트리가 있습니다.
자세한 내용은 결정 트리 과정의 결정 트리 섹션을 참고하세요.
결정 트리
계층적으로 구성된 일련의 조건과 리프로 구성된 지도 학습 모델입니다. 예를 들어 다음은 의사 결정 트리입니다.
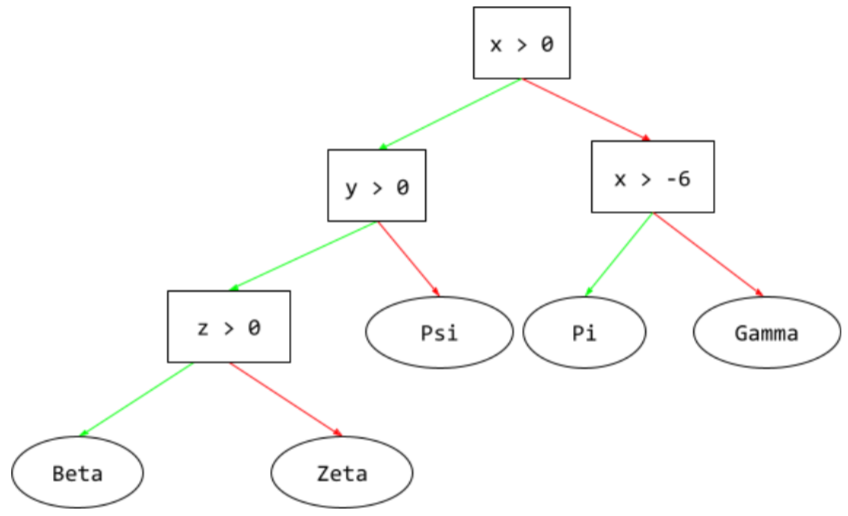
E
엔트로피
정보 이론에서 확률 분포가 얼마나 예측 불가능한지를 설명합니다. 또는 엔트로피는 각 예시에 포함된 정보의 양으로도 정의됩니다. 분포는 확률 변수의 모든 값이 동일할 때 가능한 가장 높은 엔트로피를 갖습니다.
가능한 값이 두 개인 집합('0'과 '1', 예를 들어 이진 분류 문제의 라벨)의 엔트로피는 다음 공식을 따릅니다.
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
각 항목의 의미는 다음과 같습니다.
- H는 엔트로피입니다.
- p는 '1' 예시의 비율입니다.
- q는 '0' 예시의 비율입니다. q = (1 - p)입니다.
- log는 일반적으로 log2입니다. 이 경우 엔트로피 단위는 비트입니다.
예를 들어 다음을 가정합니다.
- 100개의 예에 값 '1'이 포함되어 있습니다.
- 300개의 예시에는 '0' 값이 포함되어 있습니다.
따라서 엔트로피 값은 다음과 같습니다.
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81비트/예시
완벽하게 균형이 잡힌 집합 (예: '0' 200개와 '1' 200개)의 엔트로피는 예시당 1.0비트입니다. 세트가 불균형해질수록 엔트로피는 0.0에 가까워집니다.
결정 트리에서 엔트로피는 분류 결정 트리의 성장 중에 분할기가 조건을 선택하는 데 도움이 되는 정보 획득을 공식화하는 데 도움이 됩니다.
다음과 엔트로피 비교:
- gini impurity
- 교차 엔트로피 손실 함수
엔트로피는 흔히 섀넌의 엔트로피라고 불립니다.
자세한 내용은 결정 트리 과정의 숫자 특징이 있는 이진 분류를 위한 정확한 분할기를 참고하세요.
F
특성 중요도
변수 중요도의 동의어입니다.
G
gini 불순도
엔트로피와 유사한 측정항목입니다. 분할기는 지니 불순도 또는 엔트로피에서 파생된 값을 사용하여 분류 결정 트리의 조건을 구성합니다. 정보 획득은 엔트로피에서 파생됩니다. 지니 불순도에서 파생된 측정항목에 대해 보편적으로 허용되는 동등한 용어는 없습니다. 하지만 이 이름이 지정되지 않은 측정항목은 정보 획득만큼 중요합니다.
지니 불순도는 지니 계수 또는 간단히 지니라고도 합니다.
그래디언트 부스티드 (결정) 트리 (GBT)
다음과 같은 결정 포레스트 유형입니다.
자세한 내용은 의사결정 트리 과정의 그라디언트 부스팅 의사결정 트리를 참고하세요.
그라데이션 부스팅
강한 모델의 품질을 반복적으로 개선 (손실 감소)하기 위해 약한 모델을 학습시키는 학습 알고리즘입니다. 예를 들어 약한 모델은 선형 모델이나 작은 결정 트리 모델일 수 있습니다. 강한 모델은 이전에 학습된 모든 약한 모델의 합이 됩니다.
가장 간단한 형태의 그라디언트 부스팅에서는 각 반복에서 강력한 모델의 손실 그라디언트를 예측하도록 약한 모델이 학습됩니다. 그런 다음 경사 하강법과 유사하게 예측된 경사를 빼서 강력한 모델의 출력이 업데이트됩니다.
각 항목의 의미는 다음과 같습니다.
- $F_{0}$ 은 시작 강한 모델입니다.
- $F_{i+1}$ 은 다음 강력한 모델입니다.
- $F_{i}$ 는 현재 강력한 모델입니다.
- $\xi$ 는 0.0과 1.0 사이의 값으로 축소라고 하며, 경사 하강법의 학습률과 유사합니다.
- $f_{i}$ 는 $F_{i}$의 손실 기울기를 예측하도록 학습된 약한 모델입니다.
최신 그라데이션 부스팅 변형에는 계산에 손실의 2차 도함수(헤시안)도 포함됩니다.
결정 트리는 일반적으로 그레이디언트 부스팅에서 약한 모델로 사용됩니다. 그래디언트 부스티드 (결정) 트리를 참고하세요.
I
추론 경로
결정 트리에서 추론 중에 특정 예가 루트에서 다른 조건으로 이동하는 경로가 리프로 종료됩니다. 예를 들어 다음 결정 트리에서 더 두꺼운 화살표는 다음 기능 값이 있는 예시의 추론 경로를 보여줍니다.
- x = 7
- y = 12
- z = -3
다음 그림의 추론 경로는 리프 (Zeta)에 도달하기 전에 세 가지 조건을 거칩니다.
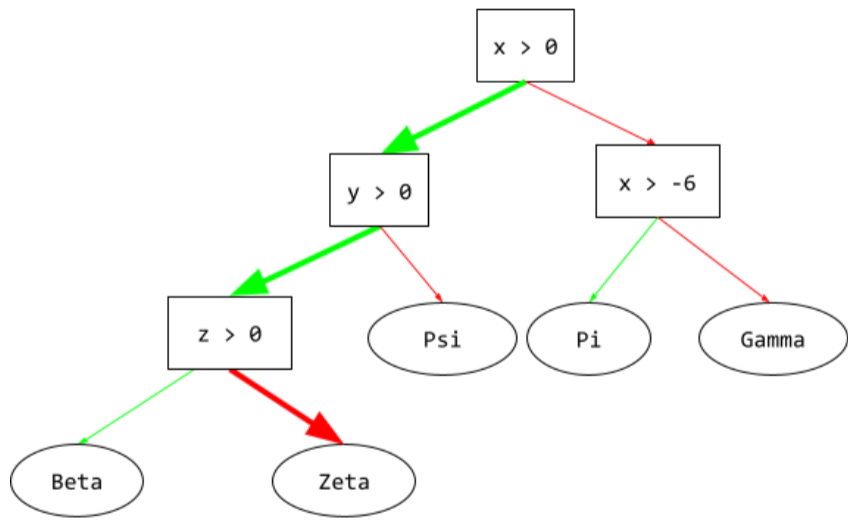
세 개의 굵은 화살표는 추론 경로를 보여줍니다.
자세한 내용은 결정 트리 과정의 결정 트리를 참고하세요.
정보 획득
결정 포레스트에서 노드의 엔트로피와 하위 노드의 엔트로피의 가중치 (예 수 기준) 합계 간의 차이입니다. 노드의 엔트로피는 해당 노드의 예시의 엔트로피입니다.
예를 들어 다음 엔트로피 값을 고려해 보세요.
- 상위 노드의 엔트로피 = 0.6
- 관련 예가 16개인 한 하위 노드의 엔트로피 = 0.2
- 관련 예가 24개인 다른 하위 노드의 엔트로피 = 0.1
따라서 예의 40% 는 한 하위 노드에 있고 60% 는 다른 하위 노드에 있습니다. 따라서 날짜는 다음과 같이 계산합니다.
- 가중 엔트로피 합계 = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
따라서 정보 획득은 다음과 같습니다.
- 정보 획득 = 상위 노드의 엔트로피 - 하위 노드의 가중 엔트로피 합계
- 정보 획득 = 0.6 - 0.14 = 0.46
대부분의 분할기는 정보 획득을 극대화하는 조건을 만들려고 합니다.
in-set 조건
결정 트리에서 상품 집합에 상품이 있는지 테스트하는 조건입니다. 예를 들어 다음은 인셋 조건입니다.
house-style in [tudor, colonial, cape]
추론 중에 주택 스타일 특성의 값이 tudor 또는 colonial 또는 cape이면 이 조건은 '예'로 평가됩니다. 하우스 스타일 기능의 값이 다른 값 (예: ranch)이면 이 조건은 '아니요'로 평가됩니다.
인셋 조건은 일반적으로 원-핫 인코딩된 특성을 테스트하는 조건보다 더 효율적인 결정 트리를 생성합니다.
L
잎
결정 트리의 모든 엔드포인트 조건과 달리 리프는 테스트를 실행하지 않습니다. 리프는 가능한 예측입니다. 리프는 추론 경로의 터미널 노드이기도 합니다.
예를 들어 다음 결정 트리에는 리프가 3개 있습니다.
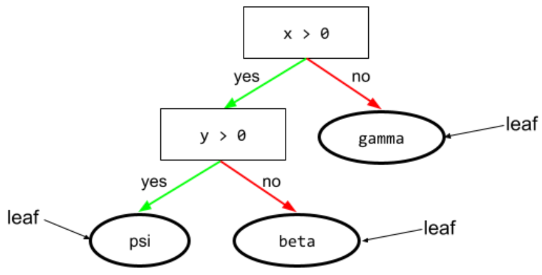
자세한 내용은 결정 트리 과정의 결정 트리를 참고하세요.
N
노드 (결정 트리)
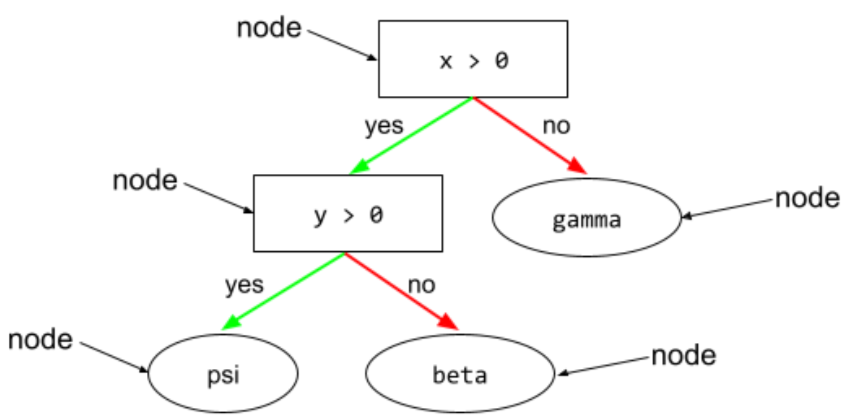
자세한 내용은 결정 트리 과정의 결정 트리를 참고하세요.
논바이너리 조건
가능한 결과가 3개 이상인 조건 예를 들어 다음 비이진 조건에는 세 가지 가능한 결과가 포함되어 있습니다.
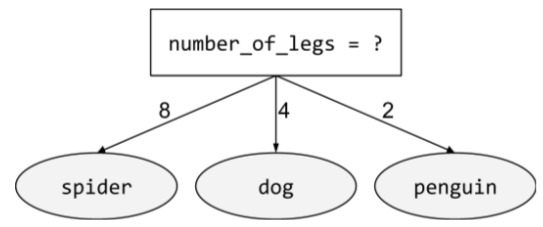
자세한 내용은 결정 트리 과정의 조건 유형을 참고하세요.
O
사선 조건
결정 트리에서 두 개 이상의 특성이 포함된 조건입니다. 예를 들어 높이와 너비가 모두 특징인 경우 다음은 사선 조건입니다.
height > width
축 정렬 조건과 대비되는 개념입니다.
자세한 내용은 결정 트리 과정의 조건 유형을 참고하세요.
out-of-bag 평가 (OOB 평가)
각 결정 트리를 해당 결정 트리의 학습 중에 사용되지 않은 예에 대해 테스트하여 결정 포레스트의 품질을 평가하는 메커니즘입니다. 예를 들어 다음 다이어그램에서 시스템은 예의 약 2/3에 대해 각 결정 트리를 학습한 다음 나머지 1/3에 대해 평가합니다.
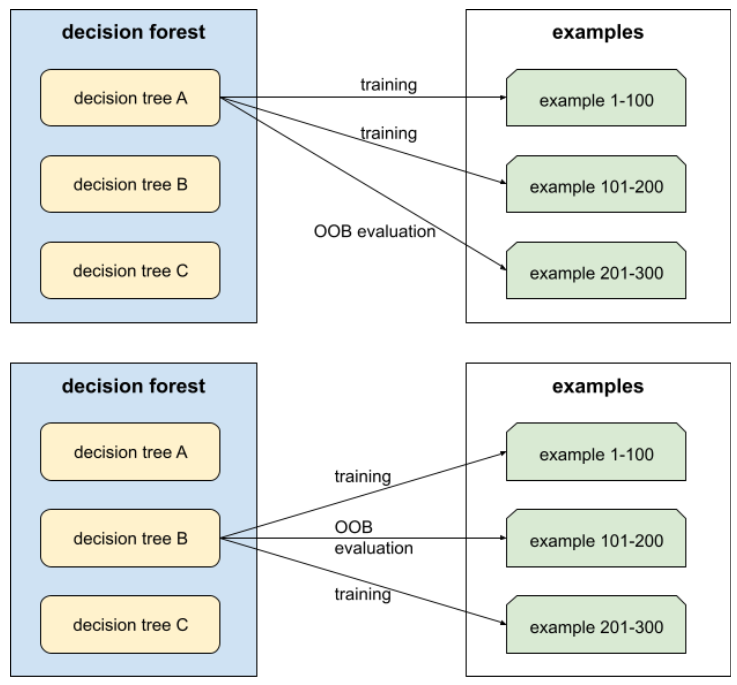
아웃 오브 백 평가는 교차 검증 메커니즘을 계산적으로 효율적이고 보수적으로 근사한 것입니다. 교차 검증에서는 각 교차 검증 라운드에 대해 하나의 모델이 학습됩니다(예: 10겹 교차 검증에서는 10개의 모델이 학습됨). OOB 평가에서는 단일 모델이 학습됩니다. 배깅은 학습 중에 각 트리에서 일부 데이터를 보류하므로 OOB 평가에서 해당 데이터를 사용하여 교차 검증을 근사할 수 있습니다.
자세한 내용은 결정 트리 과정의 OOB 평가를 참고하세요.
P
순열 변수 중요도
특성의 값을 순열한 후 모델의 예측 오류 증가를 평가하는 변수 중요도의 한 유형입니다. 순열 변수 중요도는 모델에 종속되지 않는 측정항목입니다.
R
랜덤 포레스트
각 결정 트리가 배깅과 같은 특정 무작위 노이즈로 학습되는 결정 트리의 앙상블입니다.
랜덤 포레스트는 결정 포레스트의 한 유형입니다.
자세한 내용은 결정 트리 과정의 랜덤 포레스트를 참고하세요.
루트
결정 트리의 시작 노드 (첫 번째 조건)입니다. 관례에 따라 다이어그램은 결정 트리의 루트를 상단에 배치합니다. 예를 들면 다음과 같습니다.
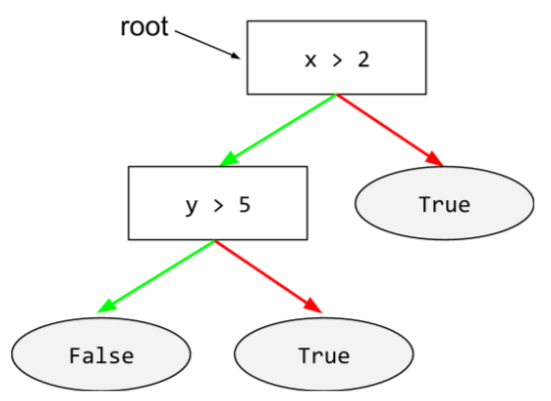
S
복원 추출
동일한 항목을 여러 번 선택할 수 있는 후보 항목 집합에서 항목을 선택하는 방법입니다. '복원'이라는 문구는 각 선택 후 선택된 항목이 후보 항목 풀로 반환된다는 의미입니다. 역방향 방법인 대체 없이 샘플링은 후보 항목을 한 번만 선택할 수 있음을 의미합니다.
예를 들어 다음과 같은 과일 세트를 생각해 보겠습니다.
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}시스템에서 fig를 첫 번째 항목으로 무작위로 선택한다고 가정해 보겠습니다.
복원 샘플링을 사용하는 경우 시스템은 다음 집합에서 두 번째 항목을 선택합니다.
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}예, 이전과 동일한 세트이므로 시스템에서 fig를 다시 선택할 수 있습니다.
교체 없이 샘플링을 사용하는 경우 선택된 샘플은 다시 선택할 수 없습니다. 예를 들어 시스템에서 fig를 첫 번째 샘플로 무작위로 선택하면 fig를 다시 선택할 수 없습니다. 따라서 시스템은 다음 (축소된) 세트에서 두 번째 샘플을 선택합니다.
fruit = {kiwi, apple, pear, cherry, lime, mango}shrinkage
그라데이션 부스팅에서 과적합을 제어하는 초매개변수입니다. 그레이디언트 부스팅의 축소는 경사하강법의 학습률과 유사합니다. 수축률은 0.0~1.0 사이의 십진수 값입니다. 수축 값이 작을수록 수축 값이 클 때보다 과적합이 더 많이 줄어듭니다.
분할
분할기
결정 트리를 학습하는 동안 각 노드에서 최적의 조건을 찾는 역할을 하는 루틴(및 알고리즘)입니다.
T
테스트
임계값 (결정 트리)
축 정렬 조건에서 기능이 비교되는 값입니다. 예를 들어 다음 조건에서 75는 기준값입니다.
grade >= 75
자세한 내용은 결정 트리 과정의 숫자 특성을 사용한 이진 분류를 위한 정확한 분할기를 참고하세요.
V
변수 중요도
모델에 대한 각 특성의 상대적 중요도를 나타내는 점수 집합입니다.
예를 들어 주택 가격을 추정하는 결정 트리를 생각해 보세요. 이 결정 트리에서 크기, 연령, 스타일의 세 가지 특징을 사용한다고 가정해 보겠습니다. 세 가지 특징의 변수 중요도가 {size=5.8, age=2.5, style=4.7}로 계산되면 크기가 연령이나 스타일보다 의사결정 트리에 더 중요합니다.
다양한 변수 중요도 측정항목이 있으며, 이를 통해 ML 전문가에게 모델의 다양한 측면에 관한 정보를 제공할 수 있습니다.
W
집단 지성
많은 사람 ('대중')의 의견이나 추정치를 평균하면 놀라울 정도로 좋은 결과가 나온다는 아이디어입니다. 예를 들어 큰 병에 들어 있는 젤리빈의 수를 추측하는 게임을 생각해 보세요. 개별 추측은 대부분 정확하지 않지만 모든 추측의 평균은 항아리에 들어 있는 실제 젤리빈 수에 놀라울 정도로 가까운 것으로 실증적으로 입증되었습니다.
앙상블은 집단 지성의 소프트웨어 버전입니다. 개별 모델이 매우 부정확한 예측을 하더라도 여러 모델의 예측을 평균하면 놀라울 정도로 좋은 예측이 생성되는 경우가 많습니다. 예를 들어 개별 결정 트리는 예측을 제대로 하지 못할 수 있지만 결정 포레스트는 매우 정확한 예측을 하는 경우가 많습니다.