 Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
公平性:評估偏誤
透過集合功能整理內容
你可以依據偏好儲存及分類內容。
評估模型時,系統會依據整個測試或驗證計算指標
因此無法準確說明模型合理性
在大多數範例,整體模型效能都表現可能不佳
對少數樣本的執行成效,可能會導致偏誤
模型預測結果你可以使用匯總成效指標,例如
精確度、
喚回度、
且準確率也未必會降低
來暴露這些問題
我們可以回顧門票模式,並探索一些新技巧
。
假設入學分類模型選出 20 位學生參加
來自 100 位候選人的大學,且屬於以下兩個客層:
多數團體 (藍色,80 名學生) 和少數族群
(橘色,20 名學生)。
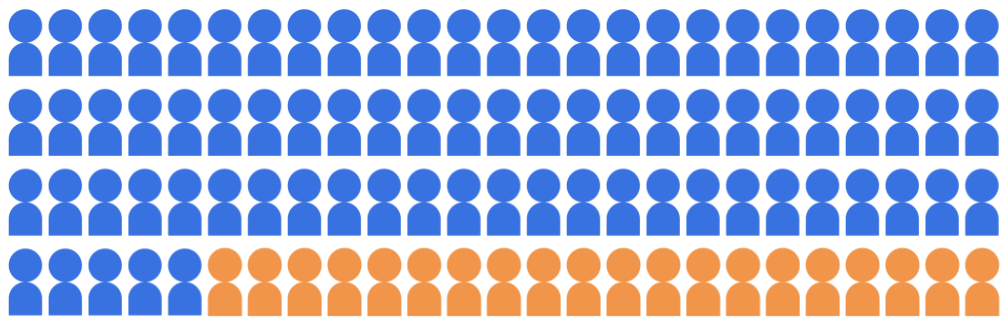 圖 1:100 名學生的候選人群:80 位學生屬於
多數族群 (藍色),20 名學生屬於少數族群
(橘色)。
圖 1:100 名學生的候選人群:80 位學生屬於
多數族群 (藍色),20 名學生屬於少數族群
(橘色)。
模型必須承認符合資格的學生
兩個客層內的候選人。
如何評估模型預測的公平性?有許多
各指標都提供不同的數學運算
「公平性」的定義後續各節將探討三種
包括客層公平性、商機平等
以及反事實的公平性
除非另有註明,否則本頁面中的內容是採用創用 CC 姓名標示 4.0 授權,程式碼範例則為阿帕契 2.0 授權。詳情請參閱《Google Developers 網站政策》。Java 是 Oracle 和/或其關聯企業的註冊商標。
上次更新時間:2024-08-13 (世界標準時間)。
[[["容易理解","easyToUnderstand","thumb-up"],["確實解決了我的問題","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["缺少我需要的資訊","missingTheInformationINeed","thumb-down"],["過於複雜/步驟過多","tooComplicatedTooManySteps","thumb-down"],["過時","outOfDate","thumb-down"],["翻譯問題","translationIssue","thumb-down"],["示例/程式碼問題","samplesCodeIssue","thumb-down"],["其他","otherDown","thumb-down"]],["上次更新時間:2024-08-13 (世界標準時間)。"],[],[]]