本頁面列出生成式 AI 詞彙表。如要查看所有詞彙,請按這裡。
A
改編
與微調或微調同義。
代理程式
這類軟體可以根據使用者輸入的內容進行推論,然後代表使用者規劃及執行動作。
在強化學習中,代理程式是使用政策的實體,可盡量提高從環境的狀態轉換所獲得的預期報酬。
聽命行事
代理功能的形容詞形式。代理式是指代理具備的特質 (例如自主性)。
代理工作流程
代理會自主規劃及執行行動,以達成目標,這個過程可能涉及推論、叫用外部工具,以及自行修正計畫。
AI 垃圾
生成式 AI 系統的輸出內容,品質不佳但數量龐大。舉例來說,如果網頁充斥著 AI 垃圾內容,就表示網頁上都是以低成本製作的 AI 生成低品質內容。
自動評估
使用軟體判斷模型輸出內容的品質。
如果模型輸出內容相對簡單,腳本或程式可以將模型輸出內容與黃金回應進行比較。這類自動評估有時也稱為「程式輔助評估」。ROUGE 或 BLEU 等指標通常有助於程式輔助評估。
如果模型輸出內容複雜或沒有正確答案,有時會由稱為「自動評分器」的獨立機器學習程式執行自動評估。
與人工評估形成對比。
自動評分工具評估
用來判斷生成式 AI 模型輸出內容品質的混合機制,結合了人工評估和自動評估。自動評估員是根據人工評估建立的資料訓練而成的機器學習模型。理想情況下,自動評估員會學習模仿人類評估員。您可以使用預先建構的自動評估人員,但最好是針對評估工作微調自動評估人員。
自我迴歸模型
模型:根據先前的預測結果推斷預測結果。舉例來說,自動迴歸語言模型會根據先前預測的權杖,預測下一個權杖。所有以 Transformer 為基礎的大型語言模型都是自動迴歸模型。
相較之下,GAN 型圖像模型通常不是自迴歸模型,因為這類模型會在單一前向傳遞中生成圖片,而不是以疊代方式逐步生成。不過,某些圖像生成模型是自動迴歸模型,因為這類模型會分階段生成圖片。
B
基礎模型
C
思維鏈提示
這項提示工程技術會引導大型語言模型 (LLM) 逐步說明推論過程。舉例來說,請看以下提示,並特別注意第二句:
如果車輛在 7 秒內從時速 0 英里加速到時速 60 英里,駕駛人會感受到多少 G 力?請在答案中列出所有相關計算。
LLM 的回覆可能如下:
- 顯示一連串物理公式,並在適當位置代入 0、60 和 7。
- 說明選擇這些公式的原因,以及各種變數的意義。
思維鏈提示會強制 LLM 執行所有計算,因此可能得出更正確的答案。此外,使用者還能透過連鎖思考提示檢查 LLM 的步驟,判斷答案是否合理。
對話
與機器學習系統 (通常是大型語言模型) 一來一往的對話內容。對話中的先前互動 (您輸入的內容和大型語言模型的回覆) 會成為後續對話的脈絡。
聊天機器人是大型語言模型的應用程式。
內容比對語言嵌入
嵌入內容,可「理解」字詞和片語,就像流利的人類說話者一樣。脈絡化語言嵌入可理解複雜的語法、語意和脈絡。
舉例來說,假設您要考量英文字詞「cow」的嵌入。較舊的嵌入 (例如 word2vec) 可以表示英文字詞,因此嵌入空間中「母牛」到「公牛」的距離,與「母羊」到「公羊」或「女性」到「男性」的距離相似。情境式語言嵌入則更進一步,可辨識出英語使用者有時會隨意使用「cow」一字來表示母牛或公牛。
脈絡窗口
模型在特定提示中可處理的權杖數量。脈絡窗口越大,模型能使用的資訊就越多,可提供連貫一致的回覆。
對話式程式設計
您與生成式 AI 模型之間的疊代式對話,目的是建立軟體。您發出提示,描述某個軟體。接著,模型會根據該說明生成程式碼。接著,您會發出新提示詞,修正先前提示詞或生成的程式碼中的瑕疵,模型就會生成更新後的程式碼。你們兩人會不斷來回調整,直到生成的軟體夠好為止。
對話式程式開發基本上就是直覺式程式開發的原始意義。
與規格化編碼形成對比。
D
直接提示
與零樣本提示同義。
蒸餾
將一個模型 (稱為「老師」) 縮減為較小的模型 (稱為「學生」),並盡可能忠實地模擬原始模型的預測結果。蒸餾技術很有用,因為與較大的模型 (老師) 相比,較小的模型有兩項主要優點:
- 推論時間縮短
- 減少記憶體和能源用量
不過,學生的預測結果通常不如老師的預測結果。
蒸餾會訓練學生模型,盡可能縮小損失函式,這是根據學生和老師模型預測結果的差異而定。
比較蒸餾與下列詞彙的異同:
詳情請參閱機器學習密集課程中的「LLM:微調、蒸餾和提示工程」。
E
evals
主要用來做為大型語言模型評估的縮寫。廣義來說,評估是任何形式的評估縮寫。
評估
評估模型品質或比較不同模型成效的程序。
如要評估監督式機器學習模型,通常會根據驗證集和測試集進行評估。評估 LLM 通常需要進行更廣泛的品質和安全評估。
F
真實性
在機器學習領域中,這項屬性用來描述模型,其輸出內容以現實為依據。事實性是概念,而非指標。 舉例來說,假設您將下列提示傳送至大型語言模型:
食鹽的化學式為何?
如果模型著重事實性,則會回覆:
NaCl
我們很容易會認為所有模型都應以事實為依據。不過,部分提示 (如下所示) 應會促使生成式 AI 模型著重創意,而非事實。
為太空人和毛毛蟲寫一首打油詩。
因此生成的打油詩不太可能符合現實。
與真實性形成對比。
快速衰減
訓練技術,可提升大型語言模型的效能。快速衰減是指在訓練期間快速降低學習率。這項策略有助於防止模型過度配適訓練資料,並提升一般化。
少量樣本提示
提示包含多個 (「幾個」) 範例,說明大型語言模型應如何回應。舉例來說,下列冗長提示包含兩個範例,向大型語言模型說明如何回答查詢。
| 提示的組成部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 您希望 LLM 回答的問題。 |
| 法國:歐元 | 舉例來說。 |
| 英國:英鎊 | 另一個例子。 |
| 印度: | 實際查詢。 |
一般來說,少量樣本提示比零樣本提示和單樣本提示產生更理想的結果。不過,少量樣本提示需要較長的提示。
少量樣本提示是少量樣本學習的一種形式,適用於以提示為基礎的學習。
詳情請參閱機器學習密集課程中的「提示工程」。
微調
對預先訓練模型進行第二階段的特定任務訓練,以便修正相關參數,將模型用於特定用途。舉例來說,部分大型語言模型的完整訓練序列如下:
- 預先訓練:使用大量一般資料集訓練大型語言模型,例如所有英文版維基百科頁面。
- 微調:訓練預先訓練模型執行特定工作,例如回覆醫療查詢。微調通常需要數百或數千個專注於特定工作的範例。
以大型圖片模型為例,完整的訓練序列如下:
- 預先訓練:使用大量一般圖片資料集 (例如 Wikimedia Commons 中的所有圖片),訓練大型圖片模型。
- 微調:訓練預先訓練模型,執行特定工作,例如生成虎鯨圖片。
微調可包含下列策略的任意組合:
- 修改預先訓練模型的所有現有參數。這有時稱為「完整微調」。
- 只修改預先訓練模型部分現有參數 (通常是靠近輸出層的層),同時保持其他現有參數不變 (通常是靠近輸入層的層)。請參閱高效參數調整。
- 新增更多層,通常是在最接近輸出層的現有層之上。
微調是遷移學習的一種形式。因此,微調作業使用的損失函數或模型類型,可能與訓練預先訓練模型時不同。舉例來說,您可以微調預先訓練的大型圖像模型,產生迴歸模型,傳回輸入圖像中的鳥類數量。
比較微調與下列詞彙的異同:
詳情請參閱機器學習密集課程的「微調」一文。
Flash 模型
這是一系列相對較小的 Gemini 模型,經過最佳化處理,速度快且延遲時間短。Flash 模型適用於各種應用程式,可快速回覆並提供高處理量。
基礎模型
這類模型經過訓練,可處理大量多樣的訓練集,是極為龐大的預先訓練模型。基礎模型可以執行下列兩項操作:
換句話說,基礎模型在一般情況下已具備強大能力,但可進一步自訂,以更有效率地完成特定工作。
成功次數比例
用於評估機器學習模型生成文字的指標。成功率是指「成功」生成的文字輸出內容數量,除以生成的文字輸出內容總數。舉例來說,如果大型語言模型生成 10 個程式碼區塊,其中 5 個成功,則成功率為 50%。
雖然成功率在整個統計領域都很有用,但在 ML 領域中,這項指標主要用於評估可驗證的任務,例如程式碼生成或數學問題。
G
Gemini
這個生態系統搭載 Google 最先進的 AI 技術,這個生態系統的元素包括:
- 各種 Gemini 模型。
- 與 Gemini 模型互動的對話式介面。 使用者輸入提示,Gemini 則根據提示回覆。
- 各種 Gemini API。
- 以 Gemini 模型為基礎的各種商用產品,例如 Gemini 版 Google Cloud。
Gemini 模型
Google 最先進的 Transformer 架構多模態模型。Gemini 模型專為與代理程式整合而設計。
使用者可以透過各種方式與 Gemini 模型互動,包括透過互動式對話介面和 SDK。
Gemma
Gemma 是一系列輕量級開放式模型,採用與建立 Gemini 模型時相同的研究成果和技術。Gemma 提供多種模型,各自具備不同功能,例如視覺、程式碼和指令遵循。詳情請參閱 Gemma。
GenAI 或 genAI
生成式 AI 的縮寫。
生成的文字
一般來說,這是指機器學習模型輸出的文字。評估大型語言模型時,部分指標會比較生成文字和參考文字。舉例來說,假設您想判斷機器學習模型將法文翻譯成荷蘭文的成效,在這種情況下:
- 生成文字是機器學習模型輸出的荷蘭文翻譯。
- 參考文字是荷蘭文翻譯,由人工翻譯人員 (或軟體) 建立。
請注意,部分評估策略不涉及參考文字。
生成式 AI
這項新興的變革性領域沒有正式定義。不過,大多數專家都認為,生成式 AI 模型可以「生成」以下內容:
- 複雜
- 連貫
- 原始圖片
生成式 AI 的例子包括:
- 大型語言模型:可生成精準的原創文字,並回答問題。
- 圖片生成模型,可生成獨一無二的圖片。
- 音訊和音樂生成模型,可創作原創音樂或生成逼真的語音。
- 影片生成模型,可生成原創影片。
包括 LSTM 和 RNN 在內的部分早期技術,也能生成原創且連貫的內容。部分專家認為這些早期技術就是生成式 AI,但也有人認為真正的生成式 AI 必須能產生比早期技術更複雜的輸出內容。
與預測型機器學習形成對比。
黃金回覆
2 + 2
理想的回覆如下:
4
GPT (生成式預先訓練 Transformer)
OpenAI 開發的大型語言模型系列,以 Transformer 為基礎。
GPT 變體可套用至多種模態,包括:
- 圖像生成 (例如 ImageGPT)
- 文字轉圖像生成 (例如 DALL-E)。
H
幻覺
生成式 AI 模型產生看似合理但與事實不符的輸出內容,並聲稱是關於現實世界的陳述。舉例來說,如果生成式 AI 模型聲稱巴拉克‧歐巴馬於 1865 年過世,就是產生幻覺。
人工評估
由人員評估機器學習模型輸出內容的品質,例如請雙語者評估機器學習翻譯模型的品質。如果模型沒有唯一正確答案,人工評估就特別有用。
人機迴圈 (HITL)
這個成語的定義較為寬鬆,可能代表下列任一情況:
- 審慎或懷疑地看待生成式 AI 輸出內容的政策。
- 確保使用者協助塑造、評估及修正模型行為的策略或系統。人機迴圈可讓 AI 同時運用機器智慧和人類智慧。舉例來說,如果 AI 生成程式碼後,軟體工程師會審查,這就是人機迴圈系統。
I
情境學習
少量樣本提示的同義詞。
推論
在傳統機器學習中,預測過程是指將訓練好的模型套用至未標記的樣本。如要瞭解詳情,請參閱「機器學習簡介」課程中的「監督式學習」。
在大型語言模型中,推論是指使用經過訓練的模型,對輸入的提示生成回覆的過程。
在統計學中,推論的意義略有不同。詳情請參閱 維基百科上關於統計推論的文章。
調整指示
這是一種微調形式,可提升生成式 AI 模型遵循指令的能力。指令調整是指使用一系列指令提示訓練模型,通常涵蓋各種工作。經過指令微調的模型通常會針對各種工作,對零樣本提示生成實用的回覆。
比較對象:
L
大型語言模型
至少需要具有大量參數的語言模型。更非正式地來說,任何以 Transformer 為基礎的語言模型,例如 Gemini 或 GPT。
詳情請參閱機器學習密集課程中的大型語言模型 (LLM)。
延遲時間
模型處理輸入內容並生成回覆所需的時間。 高延遲回覆的生成時間比低延遲回覆長。
影響大型語言模型延遲時間的因素包括:
- 輸入和輸出 token 長度
- 模型複雜性
- 模型執行的基礎架構
如要打造回應快速且容易使用的應用程式,最佳化延遲時間至關重要。
LLM
大型語言模型的縮寫。
LLM 評估
用來評估大型語言模型 (LLM) 效能的一組指標和基準。概略來說,LLM 評估作業:
- 協助研究人員找出需要改進的 LLM 領域。
- 有助於比較不同 LLM,並找出最適合特定工作的 LLM。
- 確保 LLM 的使用安全無虞且符合道德規範。
詳情請參閱機器學習密集課程中的大型語言模型 (LLM)。
LoRA
低秩適應性的縮寫。
低秩適應 (LoRA)
這項參數高效技術可微調模型,做法是「凍結」模型的預先訓練權重 (使其無法再修改),然後在模型中插入一小組可訓練的權重。這組可訓練的權重 (又稱「更新矩陣」) 比基礎模型小得多,因此訓練速度快上許多。
LoRA 具有下列優點:
- 提升模型在套用微調的領域中進行預測的品質。
- 相較於需要微調模型所有參數的技術,微調速度更快。
- 可同時提供多個共用相同基礎模型的專業模型,藉此降低推論的運算成本。
M
機器翻譯
使用軟體 (通常是機器學習模型) 將文字從一種人類語言轉換為另一種人類語言,例如從英文轉換為日文。
前 k 項的平均精確度平均值 (mAP@k)
驗證資料集中所有「k 處的平均精確度」分數的統計平均值。在 k 處的平均精確度平均值可用於判斷推薦系統產生的建議品質。
雖然「平均值」這個詞組聽起來很冗餘,但這個指標名稱很合適。畢竟這項指標會找出多個「k 處的平均精確度」值。
專家混合
這項機制只會使用部分參數 (稱為「專家」) 處理特定輸入權杖或範例,藉此提高類神經網路效率。閘道網路會將每個輸入權杖或範例,傳送給適當的專家。
詳情請參閱下列任一論文:
MMIT
多模態指令調整的縮寫。
模型串聯
系統會為特定推論查詢挑選理想的模型。
假設有一組模型,大小從非常大 (大量參數) 到小得多 (參數少得多) 不等。與較小的模型相比,非常大的模型在推論時會消耗更多運算資源。不過,大型模型通常能推斷出比小型模型更複雜的要求。模型串聯會判斷推論查詢的複雜程度,然後選擇合適的模型執行推論。模型串聯的主要動機是選取較小的模型,並僅針對較複雜的查詢選取較大的模型,藉此降低推論成本。
假設手機上執行的是小型模型,而遠端伺服器上執行的是該模型較大的版本。良好的模型串聯可讓較小的模型處理簡單要求,並只呼叫遠端模型處理複雜要求,進而降低成本和延遲。
另請參閱模型路由器。
模型路由器
這個演算法會決定模型串聯中推論的理想模型。模型路由器本身通常是機器學習模型,會逐步學習如何為特定輸入內容挑選最佳模型。不過,模型路由器有時可能是較簡單的非機器學習演算法。
MOE
專家混合的縮寫。
MT
機器翻譯的縮寫。
否
Nano
Gemini 模型相對較小,專為裝置端使用而設計。詳情請參閱「Gemini Nano」。
沒有唯一正確的答案 (NORA)
講個關於大象的有趣笑話。
評估「沒有正確答案」的提示時,通常比評估「只有一個正確答案」的提示更主觀。舉例來說,評估大象笑話需要有系統性的方法,判斷笑話有多好笑。
NORA
沒有哪種格式一定比較好的縮寫。
Notebook LM
這項工具以 Gemini 為基礎,可讓使用者上傳文件,然後使用提示詢問文件相關問題、製作摘要或整理文件。舉例來說,作者可以上傳多篇短篇故事,並要求 NotebookLM 找出共同主題,或判斷哪篇最適合改編成電影。
O
一個正確答案 (ORA)
下列敘述是否正確:土星比火星大。
唯一正確的答案是 true。
與「沒有哪種格式一定比較好」形成對比。
單樣本提示
提示,其中包含一個範例,說明大型語言模型應如何回應。舉例來說,下列提示包含一個範例,向大型語言模型說明如何回答查詢。
| 提示的組成部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 您希望 LLM 回答的問題。 |
| 法國:歐元 | 舉例來說。 |
| 印度: | 實際查詢。 |
比較單樣本提示與下列詞彙的異同:
ORA
一個正確答案的縮寫。
P
高效參數調整
這是一組技術,可比完整微調更有效率地微調大型預先訓練語言模型 (PLM)。高效參數調整通常微調的參數遠少於全面微調,但一般來說,產生的大型語言模型效能與全面微調建立的大型語言模型相同 (或幾乎相同)。
比較具參數運用效率的調整機制與下列項目:
高效參數調整也稱為高效參數微調。
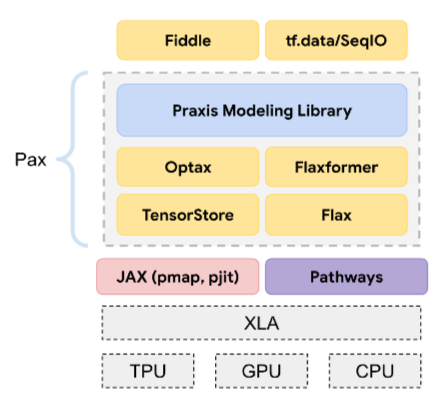
Pax
程式設計架構,專為訓練大規模類神經網路 模型而設計,模型規模龐大,可跨越多個 TPU 加速器晶片 切片或 Pod。
Pax 是以 Flax 為基礎建構,而 Flax 則是以 JAX 為基礎建構。
PLM
預先訓練語言模型的縮寫。
後訓練模型
這個詞的定義較為寬鬆,通常是指經過一些後續處理的預先訓練模型,例如:
預先訓練模型
雖然這個詞彙可能指任何訓練過的模型或訓練過的嵌入向量,但預先訓練模型現在通常是指訓練過的大型語言模型,或是其他形式的訓練過的生成式 AI 模型。
預先訓練
模型在大型資料集上進行的初始訓練。部分預先訓練模型是笨拙的巨人,通常必須透過額外訓練來精進。舉例來說,機器學習專家可能會使用大量文字資料集 (例如 Wikipedia 中所有英文網頁),預先訓練大型語言模型。預先訓練完成後,您可以透過下列任一技術進一步調整模型:
Pro
Gemini 模型的參數比 Ultra 少,但比 Nano 多。詳情請參閱「Gemini Pro」。
提示詞
輸入大型語言模型的任何文字,可讓模型以特定方式運作。提示詞可以短至片語,也可以任意長 (例如整本小說的文字)。提示可分為多個類別,包括下表所示的類別:
| 提示類別 | 範例 | 附註 |
|---|---|---|
| 問題 | 鴿子能飛多快? | |
| 指示 | 寫一首關於套利的幽默詩。 | 要求大型語言模型執行特定動作的提示。 |
| 範例 | 將 Markdown 程式碼翻譯成 HTML。例如:
Markdown:* list item HTML:<ul> <li>list item</li> </ul> |
這個範例提示的第一句話是指令。 提示的其餘部分是範例。 |
| 角色 | 向物理學博士說明為何機器學習訓練會使用梯度下降法。 | 句子的第一部分是指令,而「物理學博士」則是角色部分。 |
| 輸入部分內容,讓模型接續完成 | 英國首相住在 | 部分輸入提示詞可以突然結束 (如本例所示), 也可以底線結尾。 |
生成式 AI 模型 可以根據提示詞生成文字、程式碼、圖片、嵌入、影片等內容,幾乎無所不能。
提示型學習
某些模型具備這項功能,可根據任意文字輸入內容 (提示詞) 調整行為。在典型的提示式學習範例中,大型語言模型會生成文字來回應提示。舉例來說,假設使用者輸入下列提示:
總結牛頓第三運動定律。
能夠根據提示學習的模型並非經過特別訓練,因此無法回答先前的提示。模型「知道」許多物理學事實、一般語言規則,以及一般而言有用的答案。這些知識足以提供 (希望) 有用的答案。額外的人工回饋 (例如「這個答案太複雜了」或「什麼是回應?」) 可讓某些以提示詞為基礎的學習系統逐步提升答案的實用性。
提示設計
提示工程的同義詞。
提示工程
設計提示,引導大型語言模型生成所需回覆。人類會執行提示工程。撰寫結構良好的提示詞,是確保大型語言模型提供實用回覆的重要環節。提示工程取決於許多因素,包括:
提示設計是提示工程的同義詞。
如要進一步瞭解如何撰寫實用提示,請參閱「提示設計簡介」。
提示集
一組用於評估大型語言模型的提示。舉例來說,下圖顯示一組提示,其中包含三個提示:
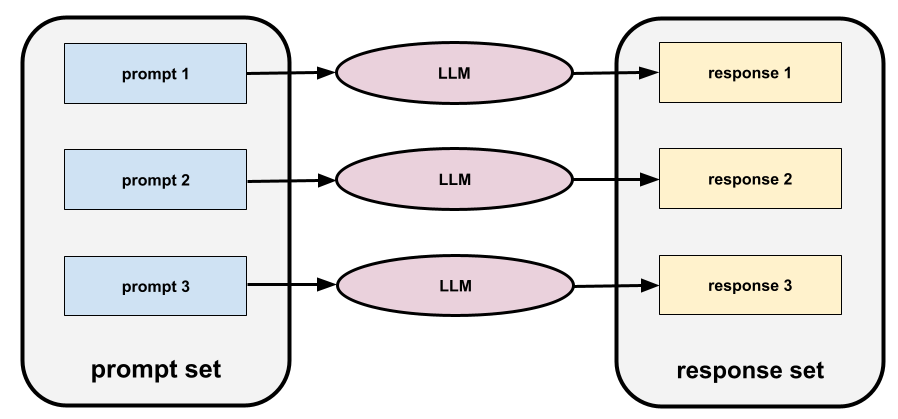
優質的提示集包含足夠「廣泛」的提示,可全面評估大型語言模型的安全性和實用性。
另請參閱回應集。
調整提示
參數效率調整機制,可學習系統在實際提示前預先加入的「前置字元」。
提示調整的一種變化 (有時稱為「前置字元調整」) 是在每個層前面加上前置字元。相較之下,大多數的提示調整作業只會為輸入層新增前置字串。
R
參考文字
專家對提示的回覆。舉例來說,如果提示如下:
將「What is your name?」這個問題從英文翻譯成法文。
專家可能會回覆:
Comment vous appelez-vous?
各種指標 (例如 ROUGE) 會評估參考文字與 ML 模型生成文字的相符程度。
反思
這項策略可改善代理工作流程的品質,方法是在將步驟的輸出內容傳遞至下一個步驟前,先檢查 (反思) 該輸出內容。
審查員通常是生成回覆的同一 LLM (但也有可能是不同的 LLM)。生成回覆的 LLM 如何公正評估自己的回覆?「訣竅」是讓 LLM 進入批判性 (反思) 思考模式。這個過程類似於作家先以創意的心態撰寫初稿,然後切換到批判性思維進行編輯。
舉例來說,假設代理工作流程的第一步是建立咖啡杯的文字。這個步驟的提示可能如下:
你是創意人員,生成適合印在咖啡杯上、長度少於 50 個半形字元的原創幽默文字。
現在,請想像下列反思提示:
你是咖啡愛好者。您覺得先前的回覆有趣嗎?
工作流程隨後可能只會將獲得高反思分數的文字傳遞至下一個階段。
人類回饋增強學習 (RLHF)
根據人工評估員的意見回饋,提升模型回覆的品質。舉例來說,RLHF 機制可以要求使用者使用「👍」或「👎」表情符號,評估模型回覆的品質。系統就能根據意見回饋調整日後的回覆。
回應
生成式 AI 模型推斷的文字、圖片、音訊或影片。換句話說,提示是生成式 AI 模型的輸入內容,而回覆則是輸出內容。
回覆集
角色提示
提示通常以代名詞「你」開頭,會要求生成式 AI 模型在生成回覆時,假裝是特定人士或扮演特定角色。 角色提示可協助生成式 AI 模型進入正確的「思維模式」,進而生成更有用的回覆。舉例來說,視您想取得的回覆類型而定,下列任何角色提示都可能適用:
您擁有電腦科學博士學位。
您是軟體工程師,喜歡向程式設計新手耐心說明 Python。
您是動作英雄,具備非常特殊的程式設計技能。 請向我保證,您會在 Python 清單中找到特定項目。
日
軟提示調整
這項技術可調整大型語言模型,以符合特定工作需求,且不必進行耗費大量資源的微調。軟提示微調會自動調整提示,以達成相同目標,不必重新訓練模型中的所有權重。
收到文字提示時,軟提示調整通常會將額外的權杖嵌入內容附加至提示,並使用反向傳播來最佳化輸入內容。
「硬」提示包含實際權杖,而非權杖嵌入。
specificational coding
以人類語言 (例如英文) 撰寫及維護軟體說明檔案的程序。接著,您可以請生成式 AI 模型或其他軟體工程師,根據該說明建立軟體。
自動生成的程式碼通常需要疊代。在規格編碼中,您會疊代說明檔。相較之下,在對話式程式碼編寫中,您會在提示詞輸入框中疊代。在實務上,自動生成程式碼有時會結合規格化編碼和對話式編碼。
T
溫度
超參數,可控制模型輸出內容的隨機程度。溫度越高,輸出內容的隨機性就越高;溫度越低,輸出內容的隨機性就越低。
選擇最佳溫度參數取決於具體應用程式和/或字串值。
U
Ultra
Gemini 模型,具有最多參數。詳情請參閱「Gemini Ultra」。
V
Vertex
Google Cloud 的 AI 和機器學習平台。Vertex 提供多種工具和基礎架構,可建構、部署及管理 AI 應用程式,包括存取 Gemini 模型。直覺式程式開發
提示生成式 AI 模型建立軟體。也就是說,您要透過提示說明軟體的用途和功能,生成式 AI 模型會將這些說明轉換為原始碼。生成的程式碼不一定符合您的意圖,因此直覺式程式開發通常需要疊代。
Andrej Karpathy 在這則 X 貼文中創造了「直覺式程式開發」一詞。在 X 貼文中,Karpathy 將其描述為「一種新的程式碼編寫方式...完全沉浸在氛圍中...」因此,這個詞彙原本是指刻意寬鬆的軟體建立方法,您甚至可能不會檢查產生的程式碼。不過,在許多領域中,這個詞彙的意義已迅速演變,現在是指任何形式的 AI 生成程式碼。
如要進一步瞭解直覺式程式開發,請參閱「The "wow" moment & your AI mentor」(令人驚豔的時刻和你的 AI 導師)。 什麼是直覺式程式開發?
此外,請比較直覺式程式開發與下列項目的異同:
Z
零樣本提示
| 提示的組成部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 您希望 LLM 回答的問題。 |
| 印度: | 實際查詢。 |
大型語言模型可能會回覆下列任一內容:
- 盧比符號
- 印度盧比
- ₹
- 印度盧比
- 盧比
- 印度盧比
所有答案都正確,但您可能會偏好特定格式。
比較並對照零樣本提示與下列術語: