Nelle figure 1 e 2, immagina quanto segue:
- I puntini blu rappresentano gli alberi malati.
- I puntini arancioni rappresentano alberi sani.
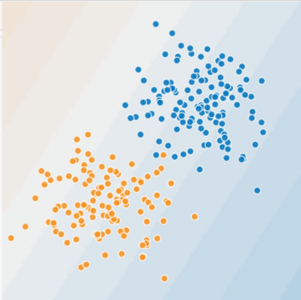
Figura 1. Si tratta di un problema lineare?
Riesci a disegnare una linea che separa accuratamente gli alberi malati da gli alberi sani? Certo. Questo è un problema lineare. La riga non sarà perfetta. Un albero o due alberi malati potrebbero essere "sani", ma la tua linea sarà un buon predittore.
Ora guarda la seguente figura:
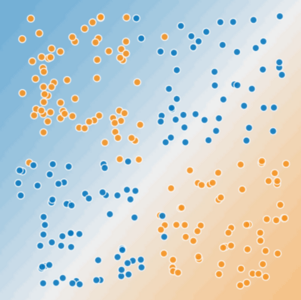
Figura 2. Si tratta di un problema lineare?
Riesci a disegnare una sola linea retta che separa accuratamente gli alberi malati dagli alberi sani? No, non puoi. Questo è un problema non lineare. Le linee che tracci potrebbero essere un predittore scarso della salute degli alberi.
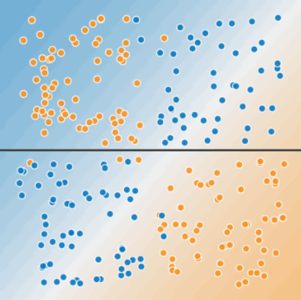
Figura 3. Non è possibile separare le due classi da una sola riga.
Per risolvere il problema non lineare mostrato nella Figura 2, crea una funzione incrociata. Una croce delle caratteristiche è una caratteristica sintetica che codifica la non linearità nello spazio delle caratteristiche moltiplicando due o più caratteristiche di input. Il termine croce deriva da cross product. Creiamo insieme una funzionalità denominata \(x_3\) attraversando \(x_1\) e \(x_2\):
Trattiamo questa croce \(x_3\) di nuova funzione coniata come qualsiasi altra funzionalità. La formula lineare diventa:
Un algoritmo lineare può apprendere una ponderazione per \(w_3\) come farebbe per \(w_1\) e \(w_2\). In altre parole, anche se \(w_3\) codifica le informazioni non lineari, non è necessario modificare il modo in cui il modello lineare viene addestrato per determinare il valore di \(w_3\).
Tipi di incroci
Possiamo creare molti tipi diversi di incroci. Ad esempio:
[A X B]: una caratteristica formata attraverso una moltiplicazione dei valori di due caratteristiche.[A x B x C x D x E]: una caratteristica incrociata formata moltiplicando i valori di cinque caratteristiche.[A x A]: un elemento croce formato quadrando una singola caratteristica.
Grazie alla discendenza gradiente stocastico, i modelli lineari possono essere addestrati in modo efficiente. Di conseguenza, l'integrazione di modelli lineari in scala con cross-feature è tradizionalmente un modo efficiente per addestrare su set di dati su larga scala.