หลายปัญหาจําเป็นต้องใช้ค่าประมาณความน่าจะเป็นเป็นเอาต์พุต การถดถอยแบบโลจิสติกส์เป็นกลไกที่มีประสิทธิภาพมากในการคํานวณความน่าจะเป็น ในทางปฏิบัติ คุณสามารถใช้ความน่าจะเป็นของการคืนสินค้าด้วยวิธีใดวิธีหนึ่งใน 2 วิธีนี้
- "ตามที่มีอยู่&;
- แปลงเป็นหมวดหมู่ไบนารีแล้ว
มาพิจารณาวิธีที่เราใช้ความน่าจะเป็นกัน"ตามที่มีอยู่" สมมติว่าเราสร้างรูปแบบการถดถอยแบบโลจิสติกส์เพื่อคาดการณ์แนวโน้มที่สุนัขจะเห่ากลางดึก เราจะเรียกความน่าจะเป็นนี้ว่า
\[p(bark | night)\]
หากโมเดลการถดถอยแบบโลจิสติกส์คาดการณ์ไว้ \(p(bark | night) = 0.05\) กว่า 1 ปี เจ้าของสุนัขควรจะต้องตื่นขึ้นมาประมาณ 18 ครั้ง
\[\begin{align} startled &= p(bark | night) \cdot nights \\ &= 0.05 \cdot 365 \\ &~= 18 \end{align} \]
ในหลายกรณี คุณจะจับคู่เอาต์พุตของการถดถอยแบบโลจิสติกส์กับวิธีการแก้ปัญหาการแยกประเภทแบบไบนารี ซึ่งมีเป้าหมายเพื่อคาดการณ์ป้ายกํากับที่เป็นไปได้จาก 1 ใน 2 รายการต่อไปนี้ได้อย่างถูกต้อง (เช่น "spam" หรือ "ไม่ใช่สแปม") โดยโมดูลในภายหลังจะโฟกัสในส่วนนี้
คุณอาจสงสัยว่ารูปแบบการถดถอยแบบโลจิสติกส์ช่วยให้เอาต์พุตเป็นไปตาม 0 ถึง 1 เสมอได้อย่างไร เมื่อเกิดกรณีนี้ขึ้น ฟังก์ชัน sigmoid ที่ระบุไว้จะสร้างเอาต์พุตที่มีลักษณะเดียวกันต่อไปนี้
ฟังก์ชัน sigmoid จะสร้างพล็อตต่อไปนี้
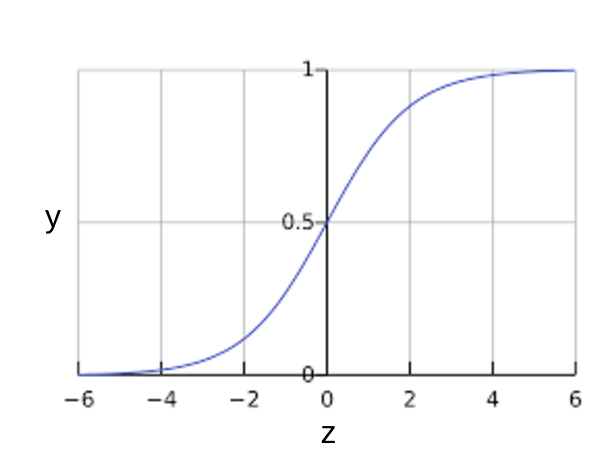
รูปที่ 1: ฟังก์ชัน Sigmoid
หาก \(z\) แสดงถึงเอาต์พุตของเลเยอร์เชิงเส้นของโมเดลที่ฝึกด้วยการถดถอยแบบโลจิสติก \(sigmoid(z)\) จะทําให้ค่า (ความน่าจะเป็น) ระหว่าง 0 ถึง 1 ในเชิงคณิตศาสตร์ ให้ทําดังนี้
ที่ไหน:
- \(y'\) เป็นเอาต์พุตของโมเดลการถดถอยแบบโลจิสติกส์สําหรับตัวอย่างที่เจาะจง
- \(z = b + w_1x_1 + w_2x_2 + \ldots + w_Nx_N\)
- ค่า \(w\) คือค่าน้ําหนักโดยประมาณของโมเดล และ \(b\) คือการให้น้ําหนักพิเศษ
- ค่า \(x\) คือค่าฟีเจอร์สําหรับตัวอย่างที่เฉพาะเจาะจง
โปรดทราบว่า \(z\) เรียกอีกอย่างว่า od-od เนื่องจากผกผันของ sigmoid ที่ระบุ \(z\) ได้เป็นบันทึกของความน่าจะเป็นของป้ายกํากับ \(1\) (เช่น "สุนัขเห่า") หารด้วยความน่าจะเป็นของ \(0\) ป้ายกํากับ (เช่น "สุนัขไม่'เห่า"):
ฟังก์ชัน sigmoid ที่มีป้ายกํากับ ML มีดังนี้

รูปที่ 2: เอาต์พุตของการถดถอยแบบโลจิสติกส์
คลิกไอคอนบวกเพื่อดูตัวอย่างการอนุมานการคํานวณการถดถอยแบบโลจิสติก
สมมติว่าเรามีโมเดลการถดถอยแบบโลจิสติกส์ที่มีฟีเจอร์ 3 รายการที่เรียนรู้เกี่ยวกับการให้น้ําหนักพิเศษและน้ําหนักต่อไปนี้
$$\begin{align} b &= 1 \\ w_1 &= 2 \\ w_2 &= -1 \\ w_3 &= 5 \end{align} $$นอกจากนี้ สมมติว่าค่าของฟีเจอร์ต่อไปนี้เป็นตัวอย่าง
$$\begin{align} x_1 &= 0 \\ x_2 &= 10 \\ x_3 &= 2 \end{align} $$ดังนั้น โอกาสในการเข้าสู่ระบบมีดังนี้
จะเป็นดังนี้
$$(1) + (2)(0) + (-1)(10) + (5)(2) = 1$$ดังนั้น การคาดการณ์การถดถอยแบบโลจิสติกของตัวอย่างนี้ จึงเป็น 0.731 ดังนี้

รูปที่ 3: ความน่าจะเป็น 73.1%