تطبیق بیش از حد به معنای ایجاد مدلی است که با مجموعه آموزشی مطابقت داشته باشد ( به خاطر بسپارد ) آنقدر نزدیک که مدل نتواند پیش بینی درستی روی داده های جدید انجام دهد. یک مدل بیش از حد شبیه به اختراعی است که در آزمایشگاه عملکرد خوبی دارد اما در دنیای واقعی بی ارزش است.
در شکل 11 تصور کنید که هر شکل هندسی موقعیت یک درخت را در یک جنگل مربعی نشان می دهد. الماس های آبی مکان درختان سالم را مشخص می کنند، در حالی که دایره های نارنجی محل درختان بیمار را مشخص می کنند.

هر شکلی را به صورت ذهنی بکشید - خطوط، منحنی ها، بیضی ها ... هر چیزی - تا درختان سالم را از درختان بیمار جدا کنید. سپس، خط بعدی را برای بررسی یک جداسازی احتمالی گسترش دهید.
باز کنید تا یک راه حل ممکن را ببینید (شکل 12).

اشکال پیچیده نشان داده شده در شکل 12 با موفقیت همه درختان به جز دو درخت را دسته بندی کردند. اگر به شکل ها به عنوان یک مدل فکر کنیم، این یک مدل فوق العاده است.
یا هست؟ یک مدل واقعا عالی نمونه های جدید را با موفقیت دسته بندی می کند. شکل 13 نشان می دهد که چه اتفاقی می افتد وقتی همان مدل روی نمونه های جدید از مجموعه آزمایشی پیش بینی می کند:

بنابراین، مدل پیچیده نشان داده شده در شکل 12 در مجموعه آموزشی کار بسیار خوبی انجام داد اما در مجموعه آزمایشی کار بسیار بدی را انجام داد. این یک مورد کلاسیک از تطابق بیش از حد مدل با داده های مجموعه آموزشی است.
فیتینگ، بیش از حد و کم تناسب
یک مدل باید روی داده های جدید پیش بینی های خوبی داشته باشد. یعنی هدف شما ایجاد مدلی است که با دادههای جدید «تناسب» داشته باشد.
همانطور که دیدید، یک مدل overfit پیشبینیهای عالی را در مجموعه آموزشی انجام میدهد اما پیشبینیهای ضعیفی را در دادههای جدید انجام میدهد. یک مدل underfit حتی پیش بینی خوبی در مورد داده های آموزشی انجام نمی دهد. اگر یک مدل overfit مانند محصولی است که در آزمایشگاه عملکرد خوبی دارد اما در دنیای واقعی ضعیف است، مدل underfit مانند محصولی است که حتی در آزمایشگاه نیز عملکرد خوبی ندارد.

تعمیم مخالف بیش از حد برازش است. یعنی مدلی که به خوبی تعمیم مییابد، پیشبینیهای خوبی را روی دادههای جدید انجام میدهد. هدف شما ایجاد مدلی است که به خوبی به داده های جدید تعمیم یابد.
تشخیص بیش از حد برازش
منحنی های زیر به شما کمک می کنند تا بیش از حد برازش را تشخیص دهید:
- منحنی های از دست دادن
- منحنی های تعمیم
یک منحنی ضرر، ضرر مدل را در برابر تعداد تکرارهای آموزشی ترسیم می کند. نموداری که دو یا چند منحنی ضرر را نشان می دهد، منحنی تعمیم نامیده می شود. منحنی تعمیم زیر دو منحنی ضرر را نشان می دهد:
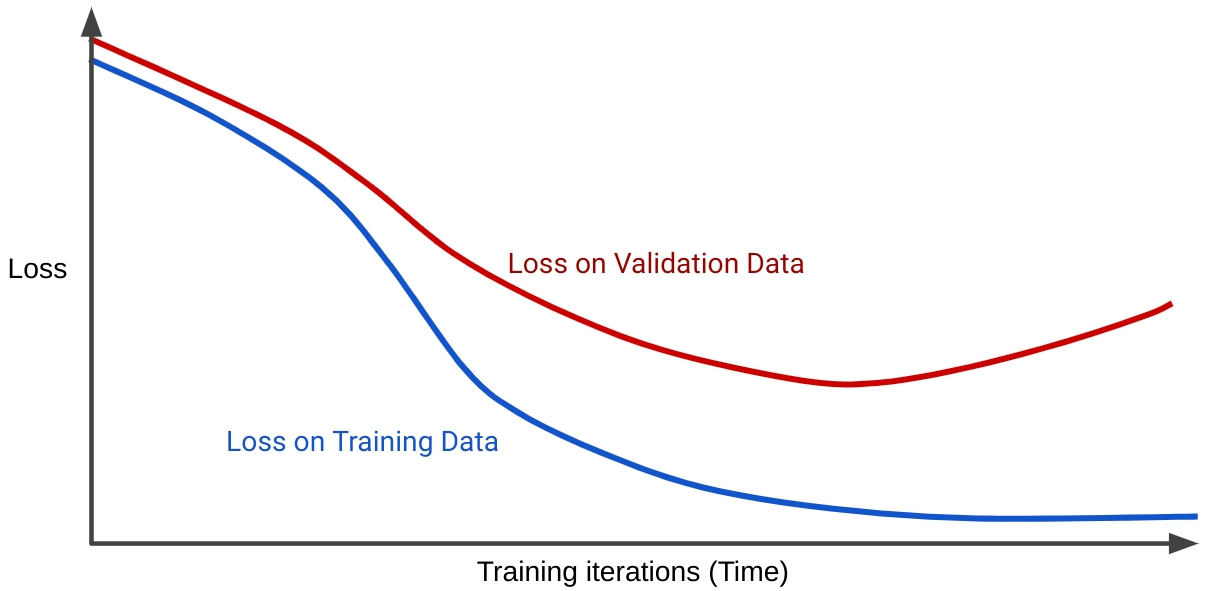
توجه داشته باشید که دو منحنی از دست دادن در ابتدا یکسان رفتار می کنند و سپس واگرا می شوند. یعنی پس از تعداد معینی از تکرار، ضرر کاهش می یابد یا برای مجموعه آموزشی ثابت می ماند (همگرا می شود)، اما برای مجموعه اعتبار سنجی افزایش می یابد. این نشان می دهد که بیش از حد مناسب است.
در مقابل، یک منحنی تعمیم برای یک مدل مناسب، دو منحنی از دست دادن را نشان میدهد که شکلهای مشابهی دارند.
چه چیزی باعث بیش از حد مناسب می شود؟
به طور کلی، برازش بیش از حد به دلیل یکی از مشکلات زیر ایجاد می شود:
- مجموعه آموزشی به اندازه کافی داده های واقعی (یا مجموعه اعتبارسنجی یا مجموعه آزمایشی) را نشان نمی دهد.
- مدل خیلی پیچیده است.
شرایط تعمیم
یک مدل در یک مجموعه آموزشی تمرین می کند، اما آزمون واقعی ارزش یک مدل این است که چگونه در نمونه های جدید، به ویژه در داده های دنیای واقعی، پیش بینی می کند. هنگام توسعه یک مدل، مجموعه آزمایشی شما به عنوان یک پروکسی برای داده های دنیای واقعی عمل می کند. آموزش مدلی که به خوبی تعمیم می یابد، مستلزم شرایط مجموعه زیر است:
- مثالها باید بهطور مستقل و یکسان توزیع شوند، که روشی جالب برای گفتن این است که مثالهای شما نمیتوانند روی یکدیگر تأثیر بگذارند.
- مجموعه داده ثابت است، به این معنی که مجموعه داده به طور قابل توجهی در طول زمان تغییر نمی کند.
- پارتیشن های مجموعه داده ها توزیع یکسانی دارند. یعنی مثالهای مجموعه آموزشی از نظر آماری مشابه نمونههای مجموعه اعتبارسنجی، مجموعه تست و دادههای دنیای واقعی هستند.
از طریق تمرینات زیر شرایط قبلی را بررسی کنید.
تمرینات: درک خود را بررسی کنید

تمرین چالشی
شما در حال ایجاد مدلی هستید که تاریخ ایده آلی را برای سواران برای خرید بلیط قطار برای یک مسیر خاص پیش بینی می کند. برای مثال، این مدل ممکن است به کاربران توصیه کند که بلیط خود را در 8 ژوئیه برای قطاری که 23 ژوئیه حرکت میکند، خریداری کنند. شرکت قطار قیمتها را هر ساعت بهروزرسانی میکند، بهروزرسانیهای خود را بر اساس عوامل مختلف اما عمدتاً بر اساس تعداد فعلی صندلیهای موجود است. یعنی:
- اگر تعداد زیادی صندلی در دسترس باشد، قیمت بلیط معمولا پایین است.
- اگر تعداد کمی صندلی در دسترس باشد، قیمت بلیط معمولاً بالاست.
پاسخ: مدل دنیای واقعی با یک حلقه بازخورد دست و پنجه نرم می کند.
به عنوان مثال، فرض کنید این مدل به کاربران توصیه می کند که در 8 جولای بلیط بخرند. برخی از سواران که از توصیه مدل استفاده می کنند بلیط خود را در ساعت 8:30 صبح روز 8 ژوئیه خریداری می کنند. در ساعت 9:00، شرکت قطار قیمت ها را افزایش می دهد زیرا تعداد صندلی های کمتری وجود دارد. در حال حاضر موجود است. سوارکارانی که از توصیه های مدل استفاده می کنند، قیمت ها را تغییر داده اند. تا عصر، قیمت بلیط ممکن است بسیار بیشتر از صبح باشد.