
Hàm PLACES_COUNT_PER_TYPE_V2 trả về một bảng BigQuery chứa số lượng địa điểm và Mã địa điểm mẫu, được phân tích theo loại địa điểm cho nhiều khu vực địa lý đầu vào. Hàm này được thiết kế để xử lý hàng loạt hiệu quả bằng cách chấp nhận một tham số bảng đầu vào của các khu vực địa lý. Bạn cung cấp các khu vực địa lý thông qua một bảng đầu vào và chỉ định các loại địa điểm dưới dạng một mảng.
Cú pháp
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_PER_TYPE_V2`( TABLE input_geographies, target_types, filters )
Thông số
PROJECT_NAME: Tên dự án trên đám mây của bạn trên Google Cloud.LINKED_DATASET_NAME: Tên của tập dữ liệu BigQuery chứa các hàm Thông tin chi tiết về địa điểm (ví dụ:places_insights___us).input_geographies: Bảng BigQuery chứa các khu vực địa lý cần phân tích. Bảng này phải có các cột sau:target_types(ARRAY<STRING>): Một mảng các chuỗi loại địa điểm mà bạn muốn lấy số lượng. Các địa điểm sẽ được tính nếu khớp với bất kỳ loại nào được liệt kê trong mảngtypes, chứ không chỉprimary_type.filters(JSON): Đối tượng JSON chứa các cặp khoá-giá trị để lọc thêm các địa điểm. Xem phần Tham số bộ lọc.
Lược đồ bảng đầu ra
Hàm PLACES_COUNT_PER_TYPE_V2 trả về một bảng có các cột sau:
| Tên cột | Loại dữ liệu | Mô tả |
|---|---|---|
geo_id |
STRING | Giá trị nhận dạng duy nhất cho khu vực địa lý đầu vào, từ bảng input_geographies. |
input_geography |
GEOGRAPHY | Đối tượng GEOGRAPHY ban đầu từ bảng input_geographies. |
place_type |
STRING | Loại địa điểm từ mảng target_types mà hàng này đại diện. |
place_count |
INTEGER | Số lượng địa điểm khớp với place_type và các bộ lọc khác trong hoặc gần khu vực địa lý. |
sample_place_ids |
ARRAY<STRING> | Một mảng gồm tối đa 250 Mã địa điểm khớp với tiêu chí cho loại và khu vực địa lý này. |
Đầu ra sẽ chứa một hàng cho mỗi tổ hợp geo_id và place_type được chỉ định trong mảng target_types, ngay cả khi số lượng là 0.
Cách hoạt động
Hàm này xử lý từng khu vực địa lý được cung cấp trong bảng input_geographies.
Đối với mỗi khu vực địa lý, hàm này sẽ đếm các địa điểm khớp với bất kỳ loại nào được liệt kê trong mảng target_types và cũng đáp ứng tất cả các điều kiện trong đối tượng JSON filters. Kết quả được tổng hợp và phân tích theo từng geo_id và từng loại trong target_types.
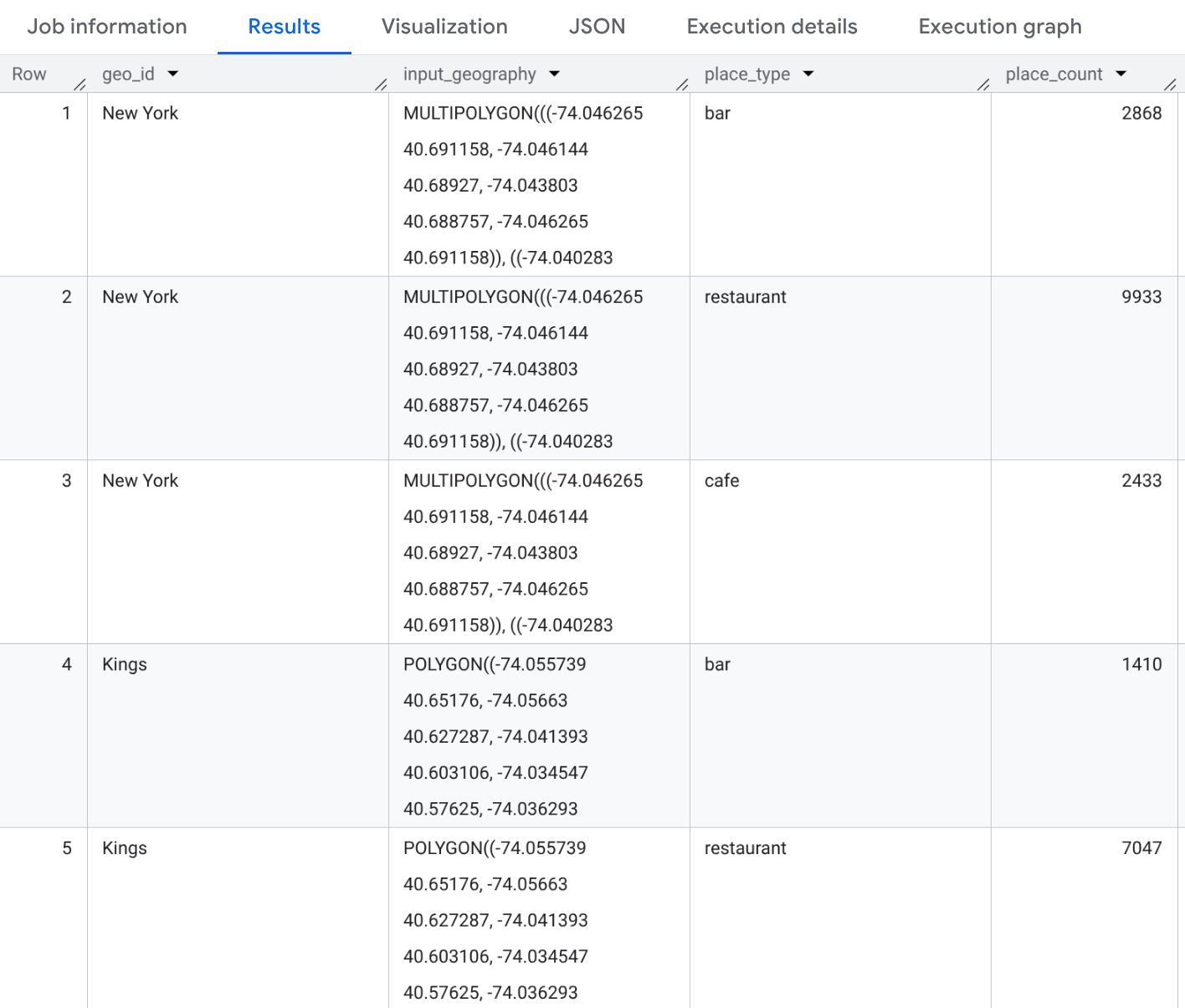
Ví dụ: Đếm các loại quán ăn ở các quận của Thành phố New York
Ví dụ này tạo một bảng số lượng cho các loại "nhà hàng", "quán cà phê" và "quán bar" trên 3 quận của Thành phố New York.
SELECT geo_id, input_geography, place_type, place_count FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), ['restaurant', 'cafe', 'bar'], -- target_types JSON_OBJECT( 'business_status', ['OPERATIONAL'] ) );
Kết quả sẽ là một bảng có 9 hàng (3 quận * 3 loại). Mỗi hàng sẽ cho biết số lượng cơ sở "nhà hàng", "quán cà phê" hoặc "quán bar" trong mỗi quận. Bạn cũng có thể đưa Mã địa điểm mẫu vào nếu thêm mã này vào câu lệnh SELECT.
Lợi ích của việc sử dụng PLACES_COUNT_PER_TYPE_V2
PLACES_COUNT_PER_TYPE_V2 mang lại một số lợi ích chính, đặc biệt là khi
so sánh với hàm PLACES_COUNT_PER_TYPE cũ hơn:
- Xử lý hàng loạt các khu vực địa lý: Không giống như
PLACES_COUNT_PER_TYPExử lý từng khu vực địa lý,PLACES_COUNT_PER_TYPE_V2chấp nhận mộtTABLEcủa các khu vực địa lý đầu vào. Điều này cho phép bạn phân tích và lấy số lượng theo loại trên nhiều khu vực địa lý (điểm, đa giác) trong một truy vấn, thay vì thực hiện nhiều lệnh gọi hàm. - Cải thiện hiệu suất và khả năng mở rộng: Bằng cách lấy dữ liệu đầu vào của bảng,
PLACES_COUNT_PER_TYPE_V2có thể tận dụng các khả năng xử lý song song và kết hợp không gian địa lý được tối ưu hoá của BigQuery trên tất cả các khu vực địa lý được cung cấp cùng một lúc. Điều này giúp cải thiện đáng kể hiệu suất và khả năng có thể mở rộng khi xử lý một số lượng lớn các khu vực địa lý. - Bao gồm số lượng bằng 0: Trả về các hàng có số lượng bằng 0 cho các loại không tìm thấy trong một khu vực cụ thể trong lô, đảm bảo một tập hợp kết quả hoàn chỉnh cho tất cả các tổ hợp loại-khu vực địa lý.