
TensorFlow is a software library that is used mainly for training and inference of neural networks. The name TensorFlow derives from the operations that neural networks perform on multidimensional data arrays, which are referred to as tensors.
TensorFlow can be used in a wide variety of programming languages, including Python and C++. TensorFlow computations are expressed as stateful dataflow graphs.
LiteRT (short for Lite Runtime), formerly known as TensorFlow Lite, is Google's high-performance runtime for on-device AI. LiteRT is an open-source framework designed for on-device inference on mobile, embedded, and IoT devices. The LiteRT runtime has APIs for mobile apps or embedded devices to generate and deploy TensorFlow models. The models are compressed and optimized in order to be more efficient and faster on smaller capacity devices such as Coral NPU.
The LiteRT framework includes a specific component called the LiteRT converter, which acts as a type of compiler or, more accurately, a model optimization and conversion tool. While the process of preparing a model for LiteRT involves "compiling" the operations into an efficient execution graph, LiteRT itself is primarily an inference framework and does not support model training. The actual training is done using the standard TensorFlow framework, often on more powerful machines.
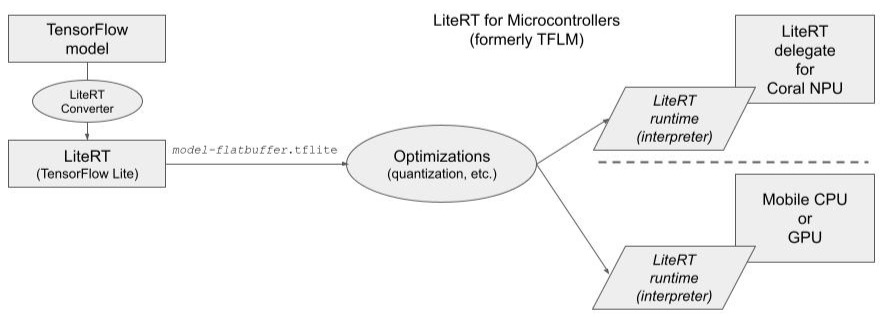
You can find ready-to-run LiteRT models for a wide range of ML/AI tasks, or convert and run TensorFlow, PyTorch, or JAX models in LiteRT format by using the AI edge conversion and optimization tools. See LiteRT overview.
Key functions of the LiteRT converter include:
- Converting standard TensorFlow models (from SavedModel or Keras formats)
into a compact and efficient FlatBuffer format with a
.tflitefile extension. - Applying optimizations like quantization and weight pruning to reduce model size and computational complexity, making the model suitable for resource-constrained environments.
- Fusing multiple operations to improve performance on the target hardware (in this case, Coral NPU).
Once converted, the resulting .tflite model is executed on the target device
using the LiteRT runtime, or interpreter, which is a separate component of the
framework optimized for low-latency inference and minimal footprint.
LiteRT for Microcontrollers
LiteRT for Microcontrollers is designed to run machine learning models on 32-bit microcontrollers and other devices with only a few kilobytes of memory. LiteRT for Microcontrollers was previously called TFLM (TensorFlow Lite Micro), and many associated tools still carry the TFLM name. See LiteRT for Microcontrollers.
See Build and convert models for details about the process of converting a TensorFlow model to run in LiteRT on microcontrollers like Coral NPU.