
Page Summary
-
Coral NPU is a RISC-V CPU designed for custom SIMD instructions and features supporting ML accelerator dataplane properties, fusing vector and scalar capabilities with domain and matrix capabilities.
-
The scalar core provides a RISC-V 32-bit ISA base, enabling a C-programmable CPU that simplifies the programming model by unifying ML/SIMD/scalar computations with a single memory model and control flow.
-
The vector execution engine utilizes a SIMD architecture for vector compute operations, supporting data widths of 8, 16, and 32 bits and simplifying compiler auto-vectorization.
-
The central matrix (MAC) execution engine is a quantized outer-product multiply-accumulate engine designed for ML domain specialization and capable of performing 256 MACs per-cycle with a vertical arrangement of multiple VDOT opcodes.
-
The Coral NPU GitHub repository is organized into subdirectories for various design components, including the top-level, scalar core, floating-point unit integration, RVV integration, and test suites.
Overview
Coral NPU is a RISC-V CPU built for custom single-instruction, multiple data (SIMD) instructions and microarchitectural features that align with the dataplane properties of an ML accelerator. The design of Coral NPU starts with domain and matrix capabilities — vector and scalar capabilities are then added for a fused architecture.
Scalar core
The scalar CPU front-end of Coral NPU provides the RISC-V 32-bit ISA base. This brings pre-existing compiler and library support from the broader software ecosystem. The scalar front-end is a C-programmable CPU in which loops and control flow enable sophisticated composition of vector ML engines. It provides a single development environment where the ML/SIMD/scalar computations have a unified memory model and control flow, thus simplifying the programming model.
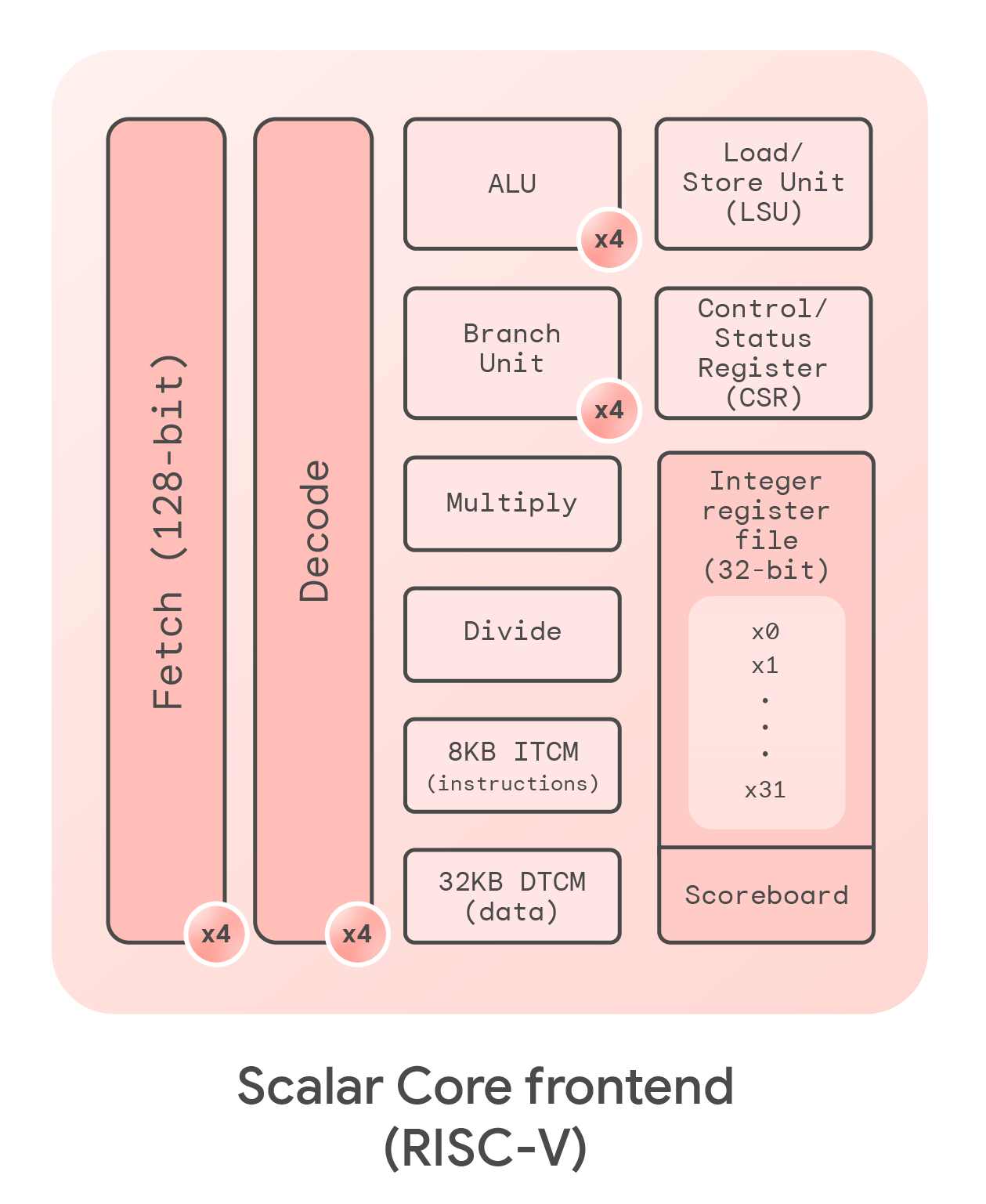
This core is a scalar front-end that drives the command queues of the ML-and-SIMD back-end. It runs the minimal set of instructions needed to support an executor run-to-completion model (no OS, no interrupts), with all control tasks onloaded to the SMC. The C extension encoding is reclaimed — as per the RISC-V specification — to provide the necessary encoding space for the SIMD registers (6b indices), and to allow flexible type encodings and instruction compression (stripmining) for the SIMD instruction set. The scalar core is an in-order machine with no speculation.
The branch policy in the fetch stage is backwards branches are taken and forward branches are not taken, incurring a penalty cycle if the execute result does not match the decision in the fetch unit.
Vector execution engine
Coral NPU features a SIMD architecture for vector compute operations. The terms SIMD and vector are used interchangeably here, referring to a simple and practical SIMD instruction definition devoid of variable-length behaviors. Coral’s scalar front-end is decoupled from the back-end by a FIFO structure that buffers vector instructions, posting only to the relevant command queues when dependencies are resolved in the vector register file (regfile). The vector core supports data widths of 8, 16, and 32 bits.
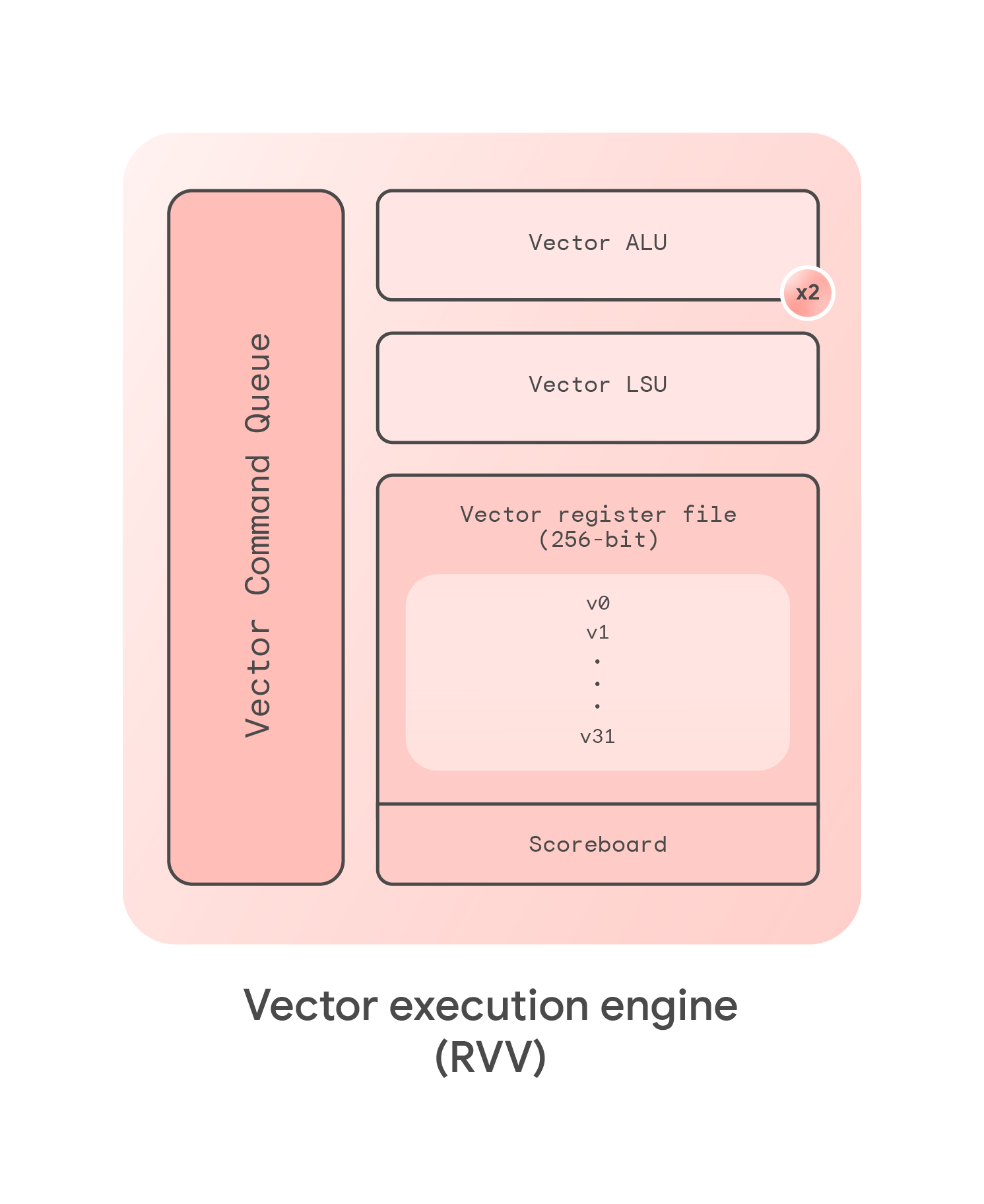
Large classes of computing can be solved with 1) ML activation functions, and 2) reductions. Data movement benefits from vector instructions in that:
- Transposition/loads/stores are common in a vector ISA.
- An outer-product engine can be fed by SIMD registers.
With Coral NPU's simplified programming model, compilers can auto-vectorize code and leverage pre-existing developer experience with NEON/SSE instruction sets.
Matrix (MAC) execution engine
The central component of the Coral NPU architecture is a quantized outer-product multiply-accumulate (MAC) engine. An outer-product engine provides two-dimensional broadcast structures to maximize the amount of deliverable compute with respect to memory accesses.
Coral NPU is designed to be simple for compilers to support even with ML domain specialization:
- Compute requirements in ML models are dominated by matrix multiplication.
- Outer-product multiplication circuit enables NxMxK MACs/cycle compute, with typical values of N=8, M=8, K=4, NxMxK=256. This can be parameterized to suit the application domain.
- Convolution, etc., can be expressed using matmuls as sub-operations.
- In a fixed-function accelerator, only matmuls are performed, with limited control flow.
On one axis is a parallel broadcast (wide, convolution weights), and on the other axis the transpose-shifted inputs of a number of batches (narrow, for example MobileNet XY batching).
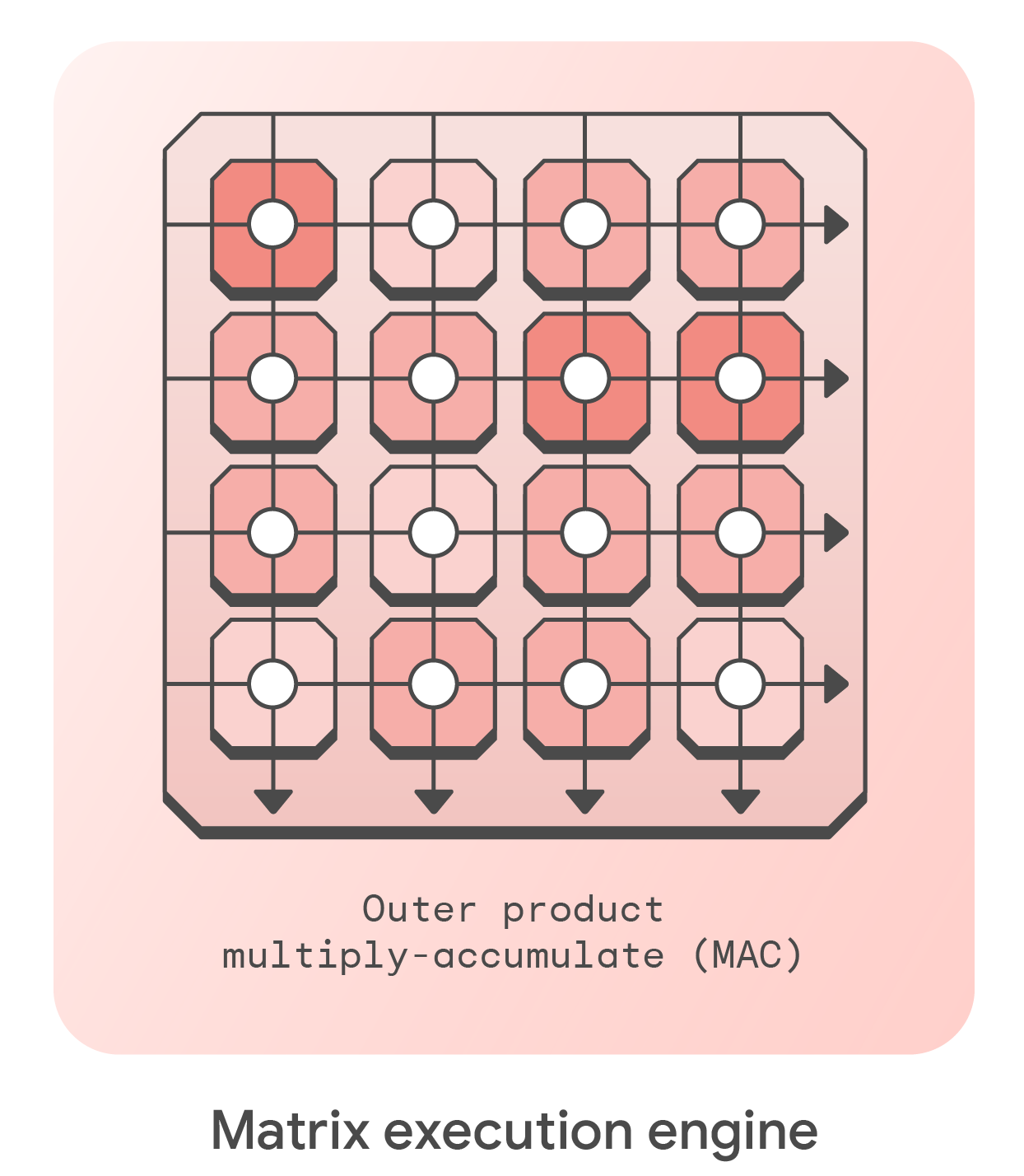
The outer-product construction is a vertical arrangement of multiple VDOT opcodes that utilize 4 x 8-bit multiplies reduced into 32-bit accumulators. This is capable of performing 256 MACs per-cycle.