
In questo documento, parleremo di come utilizzare JSON per definire gli input, i campi (incluse le etichette) e le connessioni nel blocco. Se non hai familiarità con questi termini, consulta Anatomia di un blocco prima di procedere.
Puoi anche definire input, campi e connessioni in JavaScript.
Panoramica
In JSON, descrivi la struttura di un blocco con una o più stringhe di messaggi (message0, message1, ...) e i relativi array di argomenti (args0, args1, ...). Le stringhe di messaggi sono costituite da testo, che viene convertito in etichette, e token di interpolazione (%1, %2, ...), che contrassegnano le posizioni delle connessioni e dei campi non etichetta. Gli array di argomenti descrivono come gestire i token di interpolazione.
Ad esempio, questo blocco:

è definito dal seguente JSON:
JSON
{
"message0": "set %1 to %2",
"args0": [
{
"type": "field_variable",
"name": "VAR",
"variable": "item",
"variableTypes": [""]
},
{
"type": "input_value",
"name": "VALUE"
}
]
}
Il primo token di interpolazione (%1) rappresenta un campo
variabile
(type: "field_variable"). È descritto dal primo oggetto nell'args0
array. Il secondo token (%2) rappresenta la connessione di input alla fine di un
input di valore
(type: "input_value"). È descritto dal secondo oggetto nell'args0
array.
Messaggi e input
Quando un token di interpolazione contrassegna una connessione, in realtà contrassegna la fine dell'input che contiene la connessione. Questo perché le connessioni negli input di valore e di istruzione vengono visualizzate alla fine dell'input. L'input contiene tutti i campi (incluse le etichette) dopo l'input precedente e fino al token corrente. Le sezioni seguenti mostrano esempi di messaggi e gli input creati da questi.
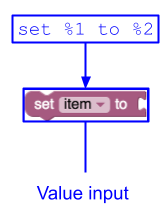
Esempio 1
JSON
{
"message0": "set %1 to %2",
"args0": [
{"type": "field_variable", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
In questo modo viene creato un singolo input di valore con tre campi: un'etichetta ("set"), un
campo variabile e un'altra etichetta ("to").
Esempio 2
JSON
{
"message0": "%1 + %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
In questo modo vengono creati due input di valore. Il primo non ha campi e il secondo ha un
campo ("+").
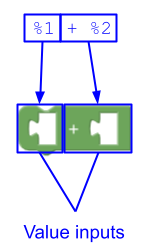
Esempio 3
JSON
{
"message0": "%1 + %2 %3",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_end_row", ...} // token %2
{"type": "input_value", ...} // token %3
],
}
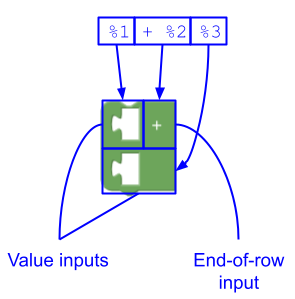
In questo modo vengono creati:
- Un input di valore senza campi,
- Un input di fine riga con un campo etichetta (
"+"), che fa sì che l'input di valore seguente venga visualizzato su una nuova riga e - Un input di valore senza campi.
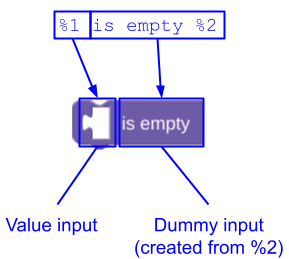
Input fittizio alla fine del messaggio
Se la stringa message termina con testo o campi, non devi aggiungere un token di interpolazione per l'input fittizio che li contiene. Blockly lo aggiunge automaticamente. Ad esempio, anziché definire un blocco lists_isEmpty come questo:
JSON
{
"message0": "%1 is empty %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_dummy", ...} // token %2
],
}
puoi lasciare che Blockly aggiunga l'input fittizio e definirlo come segue:
JSON
{
"message0": "%1 is empty",
"args0": [
{"type": "input_value", ...} // token %1
],
}
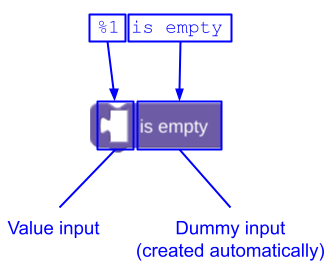
L'aggiunta automatica di un input fittizio finale consente ai traduttori di modificare message senza dover modificare gli argomenti che descrivono i token di interpolazione. Per saperne di più, consulta Ordine dei token
di interpolazione.
implicitAlign
In rari casi, l'input fittizio finale creato automaticamente deve essere allineato
a "RIGHT" o "CENTRE". Il valore predefinito, se non specificato, è "LEFT".
Nell'esempio riportato di seguito, message0 è "send email to %1 subject %2 secure %3"
e Blockly aggiunge automaticamente un input fittizio per la terza riga. L'impostazione di
implicitAlign0 su "RIGHT" forza l'allineamento a destra di questa riga.

implicitAlign
si applica a tutti gli input non definiti esplicitamente nella definizione del blocco JSON, inclusi gli input di fine riga che sostituiscono i caratteri di nuova riga
('\n'). Esiste anche la proprietà ritirata
lastDummyAlign0 che ha lo stesso comportamento di implicitAlign0.
Quando si progettano blocchi per le lingue con scrittura da destra a sinistra (arabo ed ebraico), sinistra e destra vengono invertite.
Pertanto, "RIGHT" allineerebbe i campi a sinistra.
Più messaggi
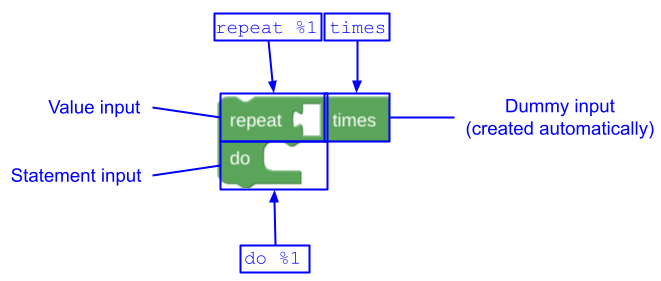
Alcuni blocchi sono naturalmente suddivisi in due o più parti separate. Considera questo blocco di ripetizione con due righe:

Se questo blocco fosse descritto con un singolo messaggio, la message0 proprietà
sarebbe "repeat %1 times %2 do %3", dove %2 rappresenta un input
di fine riga. Questa stringa è scomoda per un traduttore perché è difficile spiegare cosa significa la sostituzione %2. L'input di fine riga %2 potrebbe non essere nemmeno desiderato in alcune lingue. Inoltre, potrebbero esistere più blocchi che vogliono condividere il testo della seconda riga. Un approccio migliore consiste nell'utilizzare più proprietà message e args:
JSON
{
"message0": "repeat %1 times",
"args0": [
{"type": "input_value", ...} // token %1 in message0
],
"message1": "do %1",
"args1": [
{"type": "input_statement", ...} // token %1 in message1
],
}
Nel formato JSON è possibile definire un numero qualsiasi di proprietà message, args e implicitAlign, a partire da 0 e incrementando in sequenza. Tieni presente che Block Factory non è in grado di dividere i messaggi in più parti, ma farlo manualmente è semplice.
Ordine dei token di interpolazione
Quando localizzi i blocchi, potresti dover modificare l'ordine dei token di interpolazione in un messaggio. Questo è particolarmente importante nelle lingue con un ordine delle parole diverso dall'inglese. Ad esempio, abbiamo iniziato con un blocco definito
dal messaggio "set %1 to %2":
Ora considera una lingua ipotetica in cui "set %1 to %2" deve essere invertito
in "put %2 in %1". Se modifichi il messaggio (incluso l'ordine dei token di interpolazione) e lasci invariato l'array di argomenti, il blocco risultante è il seguente:

Blockly ha modificato automaticamente l'ordine dei campi, creato un input fittizio, e passato dagli input esterni a quelli interni inputs.
La possibilità di modificare l'ordine dei token di interpolazione in un messaggio semplifica la localizzazione. Per saperne di più, consulta Interpolazione dei messaggi JSON.
Gestione del testo
Il testo su entrambi i lati di un token di interpolazione viene troncato dagli spazi vuoti.
Il testo che utilizza il carattere % (ad es. quando si fa riferimento a una percentuale) deve utilizzare
%% in modo che non venga interpretato come un token di interpolazione.
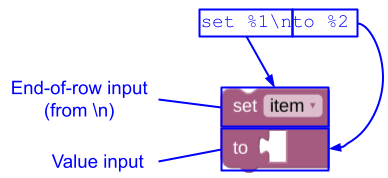
Blockly sostituisce automaticamente anche qualsiasi carattere di nuova riga (\n) nella stringa del messaggio con un input di fine riga.
JSON
{
"message0": "set %1\nto %2",
"args0": [
{"type": "field_variable", ...}, // token %1
{"type": "input_value", ...}, // token %2
]
}
Array di argomenti
Ogni stringa di messaggio è associata a un array args dello stesso numero. Ad esempio, message0 va con args0. I token di interpolazione
(%1, %2, ...) fanno riferimento agli elementi dell'array args e devono corrispondere completamente all'array
args0: nessun duplicato, nessuna omissione. I numeri dei token si riferiscono all'ordine degli elementi nell'array di argomenti; non è necessario che si trovino in ordine in una stringa di messaggio.
Ogni oggetto nell'array di argomenti ha una stringa type. Il resto dei parametri varia a seconda del tipo:
Puoi anche definire i tuoi campi personalizzati e input personalizzati e passarli come argomenti.
Campi alternativi
Ogni oggetto può avere anche un campo alt. Nel caso in cui Blockly non riconosca il type dell'oggetto, viene utilizzato l'oggetto alt al suo posto. Ad esempio, se a Blockly viene aggiunto un nuovo campo denominato field_time, i blocchi che utilizzano questo campo potrebbero utilizzare alt per definire un fallback field_input per le versioni precedenti di Blockly:
JSON
{
"message0": "sound alarm at %1",
"args0": [
{
"type": "field_time",
"name": "TEMPO",
"hour": 9,
"minutes": 0,
"alt":
{
"type": "field_input",
"name": "TEMPOTEXT",
"text": "9:00"
}
}
]
}
Un oggetto alt può avere il proprio oggetto alt, consentendo così l'incatenamento.
In definitiva, se Blockly non riesce a creare un oggetto nell'array args0 (dopo aver tentato di utilizzare gli oggetti alt), l'oggetto viene semplicemente ignorato.