
Funkcja PLACES_COUNT_PER_TYPE_V2 zwraca tabelę BigQuery zawierającą liczbę miejsc i przykładowe identyfikatory miejsc, podzielone według typu miejsca, dla wielu lokalizacji wejściowych. Ta funkcja została zaprojektowana z myślą o wydajnym przetwarzaniu wsadowym, ponieważ przyjmuje parametr tabeli wejściowej
obiektów geograficznych. Lokalizacje geograficzne podajesz w tabeli wejściowej, a typy miejsc określasz jako tablicę.
Składnia
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_PER_TYPE_V2`( TABLE input_geographies, target_types, filters )
Parametry
PROJECT_NAME: nazwa Twojego projektu Google Cloud.LINKED_DATASET_NAME: nazwa zbioru danych BigQuery zawierającego funkcje Statystyk miejsc (np.places_insights___us).input_geographies: tabela BigQuery zawierająca obszary geograficzne do analizy. Ta tabela musi zawierać te kolumny:target_types(ARRAY<STRING>): tablica ciągów znaków z typami miejsc, dla których chcesz uzyskać liczbę. Miejsca będą uwzględniane, jeśli pasują do dowolnego typu wymienionego w ich tablicytypes, a nie tylko do typuprimary_type.filters(JSON): obiekt JSON zawierający pary klucz-wartość do dodatkowego filtrowania miejsc. Zobacz Parametry filtra.
Schemat tabeli wyjściowej
Funkcja PLACES_COUNT_PER_TYPE_V2 zwraca tabelę z tymi kolumnami:
| Nazwa kolumny | Typ danych | Opis |
|---|---|---|
geo_id |
STRING | Unikalny identyfikator geograficzny danych wejściowych z tabeli input_geographies. |
input_geography |
GEOGRAPHY | Oryginalny obiekt GEOGRAPHY z tabeli input_geographies. |
place_type |
STRING | Typ miejsca z tablicy target_types, który reprezentuje ten wiersz. |
place_count |
INTEGER | Liczba miejsc pasujących do place_type i innych filtrów w regionie lub w jego pobliżu. |
sample_place_ids |
ARRAY<STRING> | Tablica zawierająca maksymalnie 250 identyfikatorów miejsc, które spełniają kryteria tego typu i lokalizacji. |
Wynik będzie zawierać wiersz dla każdej kombinacji geo_id i place_type
określonej w tablicy target_types, nawet jeśli liczba wynosi zero.
Jak to działa
Funkcja przetwarza każdy obszar geograficzny podany w tabeli input_geographies.
W przypadku każdego obszaru geograficznego zlicza miejsca, które pasują do dowolnego typu wymienionego w tablicy target_types i spełniają wszystkie warunki w obiekcie JSON filters. Wyniki są agregowane i dzielone według każdego geo_id oraz każdego typu w target_types.
Przykład: zliczanie różnych rodzajów lokali gastronomicznych w hrabstwach Nowego Jorku
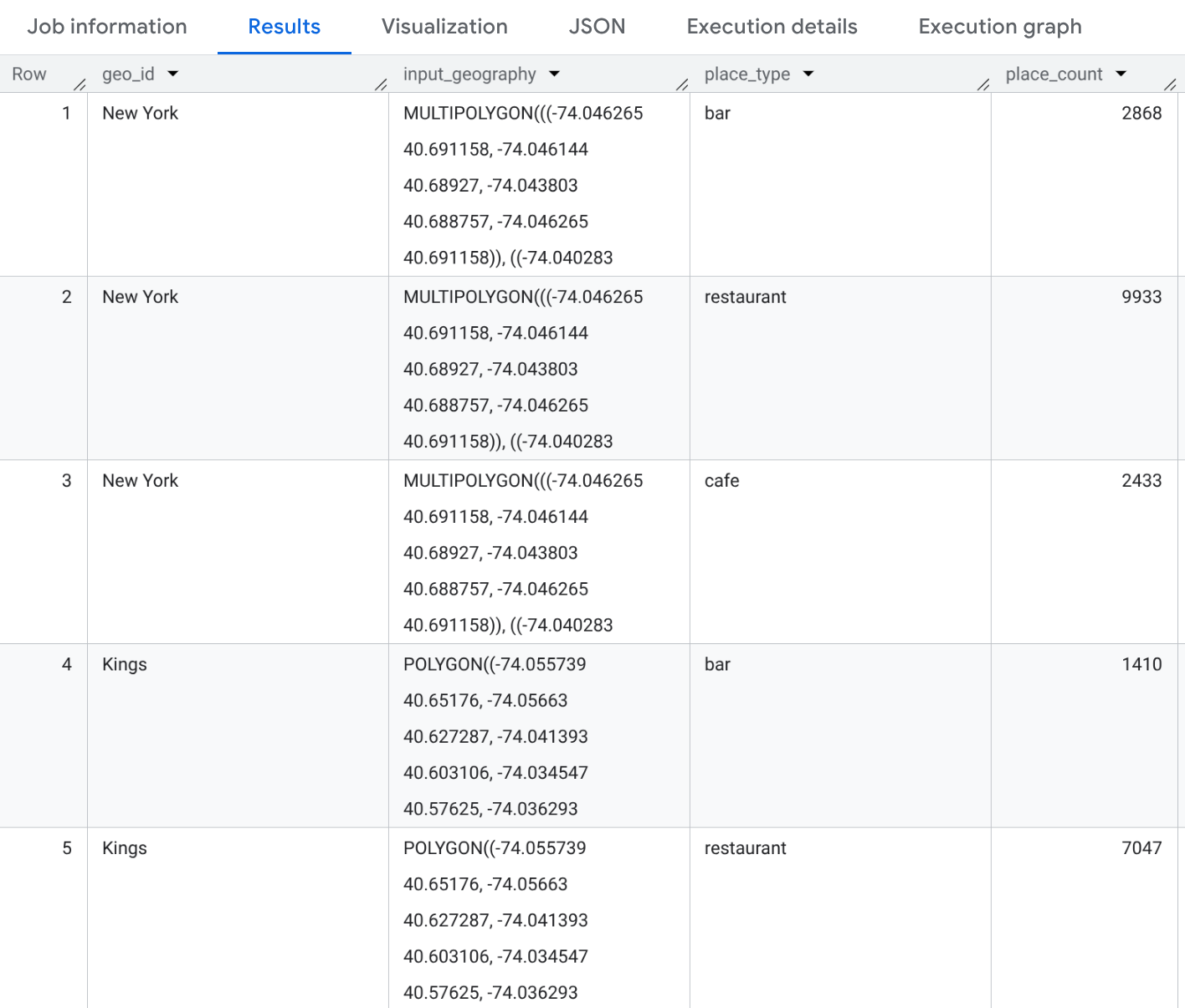
Ten przykład generuje tabelę z liczbą wystąpień typów „restauracja”, „kawiarnia” i „bar” w 3 hrabstwach Nowego Jorku.
SELECT geo_id, input_geography, place_type, place_count FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), ['restaurant', 'cafe', 'bar'], -- target_types JSON_OBJECT( 'business_status', ['OPERATIONAL'] ) );
Wynikiem będzie tabela z 9 wierszami (3 powiaty * 3 typy). Każdy wiersz będzie zawierać liczbę lokali typu „restauracja”, „kawiarnia” lub „bar” w poszczególnych hrabstwach. Jeśli dodasz go do instrukcji SELECT, możesz też uwzględnić przykładowe identyfikatory miejsc.
Korzyści z używania zmiennej PLACES_COUNT_PER_TYPE_V2
PLACES_COUNT_PER_TYPE_V2 ma kilka kluczowych zalet, zwłaszcza w porównaniu ze starszą funkcją PLACES_COUNT_PER_TYPE:
- Przetwarzanie wsadowe lokalizacji geograficznych: w przeciwieństwie do
PLACES_COUNT_PER_TYPE, które przetwarza jedną lokalizację geograficzną naraz,PLACES_COUNT_PER_TYPE_V2akceptujeTABLElokalizacji geograficznych. Dzięki temu możesz analizować i uzyskiwać dane dotyczące konkretnych typów w wielu regionach (punktach, wielokątach) w jednym zapytaniu, zamiast wykonywać wiele wywołań funkcji. - Zwiększona wydajność i skalowalność: przyjmując dane wejściowe w postaci tabeli, funkcja
PLACES_COUNT_PER_TYPE_V2może korzystać z zoptymalizowanych złączeń geoprzestrzennych BigQuery i możliwości przetwarzania równoległego we wszystkich podanych lokalizacjach geograficznych jednocześnie. Dzięki temu uzyskujemy znacznie lepsze wyniki i większą skalowalność w przypadku dużej liczby lokalizacji. - Uwzględnij zera: zwraca wiersze z zerowymi liczbami dla typów, których nie znaleziono w określonym obszarze w ramach partii, co zapewnia kompletny zestaw wyników dla wszystkich kombinacji typu i geografii.