
Neste documento, vamos discutir como usar JSON para definir as entradas, os campos (incluindo rótulos) e as conexões no seu bloco. Se você não estiver familiarizado com esses termos, consulte Anatomia de um bloco antes de continuar.
Também é possível definir entradas, campos e conexões em JavaScript.
Visão geral
Em JSON, você descreve a estrutura de um bloco com uma ou mais strings de mensagem (message0, message1, ...) e as matrizes de argumentos correspondentes (args0, args1, ...). As strings de mensagem consistem em texto, que é convertido em rótulos, e tokens de interpolação (%1, %2, ...), que marcam os locais de conexões e campos sem rótulo. As matrizes de argumentos descrevem como processar os tokens de interpolação.
Por exemplo, este bloco:

é definido pelo seguinte JSON:
JSON
{
"message0": "set %1 to %2",
"args0": [
{
"type": "field_variable",
"name": "VAR",
"variable": "item",
"variableTypes": [""]
},
{
"type": "input_value",
"name": "VALUE"
}
]
}
O primeiro token de interpolação (%1) representa um campo
de variável
(type: "field_variable"). Ele é descrito pelo primeiro objeto na matriz args0. O segundo token (%2) representa a conexão de entrada no final de uma
entrada de valor
(type: "input_value"). Ele é descrito pelo segundo objeto na matriz args0.
Mensagens e entradas
Quando um token de interpolação marca uma conexão, ele está marcando o fim da entrada que contém a conexão. Isso acontece porque as conexões nos valores e nas entradas de instruções são renderizadas no final da entrada. A entrada contém todos os campos (incluindo rótulos) após a entrada anterior e até o token atual. As seções a seguir mostram exemplos de mensagens e as entradas criadas com base nelas.
Exemplo 1
JSON
{
"message0": "set %1 to %2",
"args0": [
{"type": "field_variable", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
Isso cria uma entrada de valor único com três campos: um rótulo ("set"), um campo de variável e outro rótulo ("to").
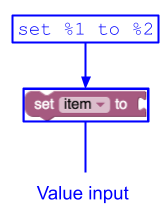
Exemplo 2
JSON
{
"message0": "%1 + %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
Isso cria duas entradas de valor. O primeiro não tem campos, e o segundo tem um campo ("+").
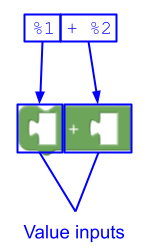
Exemplo 3
JSON
{
"message0": "%1 + %2 %3",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_end_row", ...} // token %2
{"type": "input_value", ...} // token %3
],
}
Isso cria:
- Um valor inserido sem campos,
- Uma entrada de fim de linha com um campo de marcador (
"+"), que faz com que a entrada de valor a seguir seja renderizada em uma nova linha, e - Uma entrada de valor sem campos.
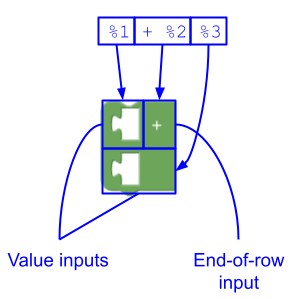
Entrada fictícia no final da mensagem
Se a string message terminar com texto ou campos, não será necessário adicionar um token de interpolação para a entrada fictícia que os contém. O Blockly adiciona isso para você. Por exemplo, em vez de definir um bloco lists_isEmpty assim:
JSON
{
"message0": "%1 is empty %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_dummy", ...} // token %2
],
}
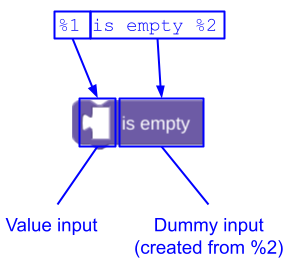
Você pode deixar o Blockly adicionar a entrada simulada e defini-la assim:
JSON
{
"message0": "%1 is empty",
"args0": [
{"type": "input_value", ...} // token %1
],
}
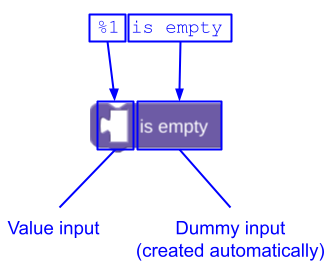
A adição automática de uma entrada fictícia final permite que os tradutores mudem
message sem precisar modificar os argumentos que descrevem os
tokens de interpolação. Para mais informações, consulte Ordem dos tokens de interpolação.
implicitAlign
Em casos raros, a entrada fictícia final criada automaticamente precisa ser alinhada
ao "RIGHT" ou "CENTRE". O padrão, se não for especificado, é "LEFT".
No exemplo abaixo, message0 é "send email to %1 subject %2 secure %3", e o Blockly adiciona automaticamente uma entrada fictícia para a terceira linha. Definir implicitAlign0 como "RIGHT" força o alinhamento à direita dessa linha.

implicitAlign
se aplica a todas as entradas que não estão definidas explicitamente na definição do bloco
JSON, incluindo entradas de fim de linha que substituem caracteres de nova linha
('\n'). Há também a propriedade descontinuada
lastDummyAlign0, que tem o mesmo comportamento de implicitAlign0.
Ao criar blocos para RTL (árabe e hebraico), esquerda e direita são invertidas.
Assim, "RIGHT" alinha os campos à esquerda.
Várias mensagens
Alguns blocos são naturalmente divididos em duas ou mais partes separadas. Considere este bloco de repetição com duas linhas:

Se esse bloco fosse descrito com uma única mensagem, a propriedade message0 seria "repeat %1 times %2 do %3", em que %2 representa uma entrada de fim de linha. Essa string é difícil para um tradutor porque
é difícil explicar o que a substituição %2 significa. A entrada %2 fim da linha
também pode não ser desejada em alguns idiomas. E pode haver vários blocos que querem compartilhar o texto da segunda linha. Uma abordagem melhor
é usar mais de uma propriedade message e args:
JSON
{
"message0": "repeat %1 times",
"args0": [
{"type": "input_value", ...} // token %1 in message0
],
"message1": "do %1",
"args1": [
{"type": "input_statement", ...} // token %1 in message1
],
}
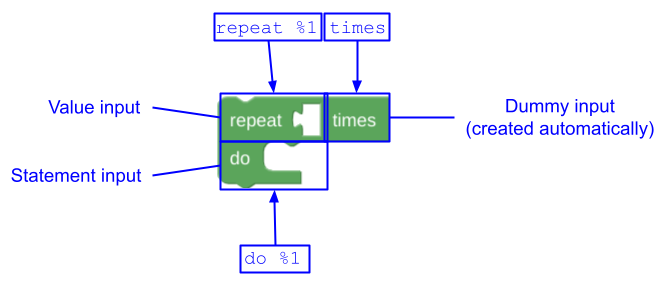
Qualquer número de propriedades message, args e implicitAlign pode ser definido no formato JSON, começando com 0 e aumentando sequencialmente. A fábrica de blocos não consegue dividir mensagens em várias partes, mas isso pode ser feito manualmente.
Ordem dos tokens de interpolação
Ao localizar blocos, talvez seja necessário mudar a ordem dos tokens de interpolação em uma mensagem. Isso é particularmente importante em idiomas que têm uma ordem de palavras diferente do inglês. Por exemplo, começamos com um bloco definido
pela mensagem "set %1 to %2":
Agora considere uma linguagem hipotética em que "set %1 to %2" precisa ser invertido
para dizer "put %2 in %1". Mudar a mensagem (incluindo a ordem dos tokens de
interpolação) e deixar a matriz de argumentos inalterada resulta no
seguinte bloco:

O Blockly mudou automaticamente a ordem dos campos, criou uma entrada fictícia e trocou as entradas externas por internas.
A capacidade de mudar a ordem dos tokens de interpolação em uma mensagem facilita a localização. Para mais informações, consulte Interpolação de mensagens JSON.
Processamento de texto
O texto em ambos os lados de um token de interpolação é cortado com espaços em branco.
O texto que usa o caractere % (por exemplo, ao se referir a uma porcentagem) precisa usar %% para que não seja interpretado como um token de interpolação.
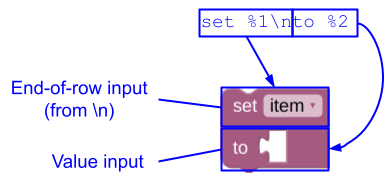
O Blockly também substitui automaticamente qualquer caractere de nova linha (\n) na string de mensagem por uma entrada de fim de linha.
JSON
{
"message0": "set %1\nto %2",
"args0": [
{"type": "field_variable", ...}, // token %1
{"type": "input_value", ...}, // token %2
]
}
Matrizes de argumentos
Cada string de mensagem é pareada com uma matriz args do mesmo número. Por
exemplo, message0 acompanha args0. Os tokens de interpolação (%1, %2, ...) se referem aos itens da matriz args e precisam corresponder completamente à matriz args0: sem duplicatas, sem omissões. Os números de token se referem à ordem dos itens na matriz de argumentos. Eles não precisam aparecer em ordem em uma string de mensagem.
Cada objeto na matriz de argumentos tem uma
string type. Os demais parâmetros variam de acordo com o tipo:
Também é possível definir seus próprios campos personalizados e entradas personalizadas e transmiti-los como argumentos.
campos alternativos
Cada objeto também pode ter um campo alt. Se o Blockly não reconhecer o type do objeto, o objeto alt será usado no lugar. Por
exemplo, se um novo campo chamado field_time for adicionado ao Blockly, os blocos que usam
esse campo poderão usar alt para definir um substituto field_input para versões mais antigas
do Blockly:
JSON
{
"message0": "sound alarm at %1",
"args0": [
{
"type": "field_time",
"name": "TEMPO",
"hour": 9,
"minutes": 0,
"alt":
{
"type": "field_input",
"name": "TEMPOTEXT",
"text": "9:00"
}
}
]
}
Um objeto alt pode ter o próprio objeto alt, permitindo o encadeamento.
Por fim, se o Blockly não conseguir criar um objeto na matriz args0 (depois de tentar qualquer objeto alt), ele será ignorado.