
इस दस्तावेज़ में, हम आपके ब्लॉक में इनपुट, फ़ील्ड (लेबल शामिल हैं) और कनेक्शन तय करने के लिए, JSON का इस्तेमाल करने के तरीके के बारे में चर्चा करेंगे. अगर आपको इन शब्दों के बारे में जानकारी नहीं है, तो आगे बढ़ने से पहले ब्लॉक की बनावट देखें.
आपके पास JavaScript में भी अपने इनपुट, फ़ील्ड, और कनेक्शन तय करने का विकल्प होता है.
खास जानकारी
JSON में, ब्लॉक की बनावट को एक या एक से ज़्यादा मैसेज स्ट्रिंग (message0, message1, ...) और उनके कलेक्शन (args0, args1, ...) के ज़रिए बताया जाता है. मैसेज स्ट्रिंग में टेक्स्ट शामिल होता है, जिसे लेबल में बदला जाता है. साथ ही, इंटरपोलेशन टोकन (%1, %2, ...) शामिल होते हैं. ये टोकन, कनेक्शन और नॉन-लेबल फ़ील्ड की जगहों को मार्क करते हैं. कलेक्शन में, इंटरपोलेशन टोकन को मैनेज करने का तरीका बताया जाता है.
उदाहरण के लिए, यह ब्लॉक:

को इस JSON से तय किया जाता है:
JSON
{
"message0": "set %1 to %2",
"args0": [
{
"type": "field_variable",
"name": "VAR",
"variable": "item",
"variableTypes": [""]
},
{
"type": "input_value",
"name": "VALUE"
}
]
}
पहला इंटरपोलेशन टोकन (%1), वैरिएबल
फ़ील्ड
(type: "field_variable") को दिखाता है. इसे args0
कलेक्शन में मौजूद पहले ऑब्जेक्ट से तय किया जाता है. दूसरा टोकन (%2), वैल्यू इनपुट (type: "input_value") के आखिर में मौजूद इनपुट कनेक्शन को दिखाता है. इसे args0 कलेक्शन में मौजूद दूसरे ऑब्जेक्ट से तय किया जाता है.
मैसेज और इनपुट
जब कोई इंटरपोलेशन टोकन, कनेक्शन को मार्क करता है, तो वह असल में उस इनपुट के आखिर को मार्क करता है जिसमें कनेक्शन शामिल होता है. ऐसा इसलिए होता है, क्योंकि वैल्यू और स्टेटमेंट इनपुट में मौजूद कनेक्शन, इनपुट के आखिर में रेंडर होते हैं. इनपुट में, पिछले इनपुट के बाद और मौजूदा टोकन तक के सभी फ़ील्ड (लेबल शामिल हैं) शामिल होते हैं. यहां दिए गए सेक्शन में, सैंपल मैसेज और उनसे बनाए गए इनपुट दिखाए गए हैं.
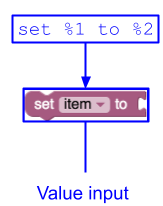
उदाहरण 1
JSON
{
"message0": "set %1 to %2",
"args0": [
{"type": "field_variable", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
इससे तीन फ़ील्ड वाला एक वैल्यू इनपुट बनता है: एक लेबल ("set"), एक
वैरिएबल फ़ील्ड, और दूसरा लेबल ("to").
उदाहरण 2
JSON
{
"message0": "%1 + %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_value", ...} // token %2
],
}
इससे दो वैल्यू इनपुट बनते हैं. पहले में कोई फ़ील्ड नहीं होता और दूसरे में एक
फ़ील्ड ("+").

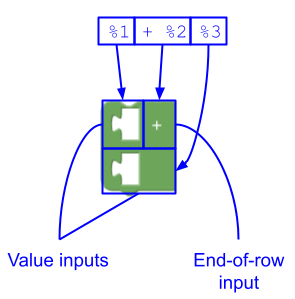
उदाहरण 3
JSON
{
"message0": "%1 + %2 %3",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_end_row", ...} // token %2
{"type": "input_value", ...} // token %3
],
}
इससे ये चीज़ें बनती हैं:
- बिना फ़ील्ड वाला एक वैल्यू इनपुट,
- एक एंड-ऑफ़-रो इनपुट
जिसमें लेबल फ़ील्ड (
"+"), जिसकी वजह से अगला वैल्यू इनपुट नई लाइन में रेंडर होता है, और - बिना फ़ील्ड वाला एक वैल्यू इनपुट.
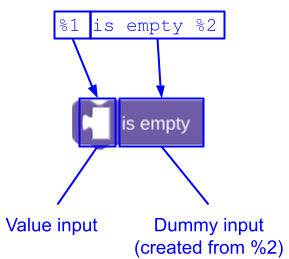
मैसेज के आखिर में डमी इनपुट
अगर आपकी message स्ट्रिंग, टेक्स्ट या फ़ील्ड के साथ खत्म होती है, तो आपको उस डमी इनपुट के लिए इंटरपोलेशन टोकन जोड़ने की ज़रूरत नहीं है जिसमें वे शामिल हैं. Blockly, इसे आपके लिए जोड़ता है. उदाहरण के लिए, lists_isEmpty ब्लॉक को इस तरह तय करने के बजाय:
JSON
{
"message0": "%1 is empty %2",
"args0": [
{"type": "input_value", ...} // token %1
{"type": "input_dummy", ...} // token %2
],
}
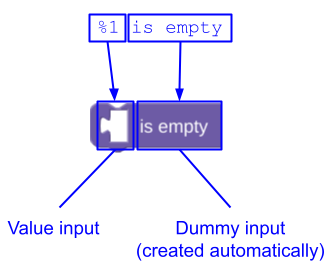
आपके पास Blockly को डमी इनपुट जोड़ने की अनुमति देने और इसे इस तरह तय करने का विकल्प होता है:
JSON
{
"message0": "%1 is empty",
"args0": [
{"type": "input_value", ...} // token %1
],
}
आखिर में डमी इनपुट के अपने-आप जुड़ने की वजह से, अनुवादक message में बदलाव कर सकते हैं. इसके लिए, उन्हें इंटरपोलेशन टोकन के बारे में बताने वाले आर्ग्युमेंट में बदलाव करने की ज़रूरत नहीं होती. ज़्यादा जानकारी के लिए, इंटरपोलेशन टोकन
का क्रम देखें.
implicitAlign
कुछ मामलों में, अपने-आप बनने वाले आखिर के डमी इनपुट को अलाइन करना पड़ता है
"RIGHT" या "CENTRE" पर. अगर कुछ नहीं बताया गया है, तो डिफ़ॉल्ट वैल्यू "LEFT" होती है.
यहां दिए गए उदाहरण में, message0 "send email to %1 subject %2 secure %3"
है. साथ ही, Blockly तीसरी लाइन के लिए अपने-आप एक डमी इनपुट जोड़ता है.
implicitAlign0 को "RIGHT" पर सेट करने से, यह लाइन दाईं ओर अलाइन हो जाती है.

implicitAlign
उन सभी इनपुट पर लागू होता है जिन्हें JSON
ब्लॉक की परिभाषा में साफ़ तौर पर तय नहीं किया गया है. इनमें, एंड-ऑफ़-रो इनपुट भी शामिल हैं जो नई लाइन के वर्णों
('\n')की जगह इस्तेमाल किए जाते हैं. इसके अलावा, अब इस्तेमाल न की जाने वाली प्रॉपर्टी
lastDummyAlign0भी है जिसका व्यवहार implicitAlign0जैसा ही है.
आरटीएल (अरबी और हिब्रू) के लिए ब्लॉक डिज़ाइन करते समय, बाएं और दाएं को उलट दिया जाता है.
इसलिए, "RIGHT" से फ़ील्ड बाईं ओर अलाइन हो जाएंगे.
कई मैसेज
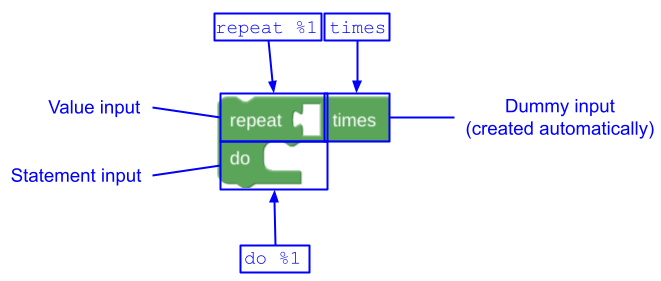
कुछ ब्लॉक, स्वाभाविक तौर पर दो या उससे ज़्यादा अलग-अलग हिस्सों में बंटे होते हैं. इस 'दोहराएं' ब्लॉक को देखें, जिसमें दो लाइनें हैं:

अगर इस ब्लॉक को एक मैसेज से तय किया जाता है, तो message0 प्रॉपर्टी
"repeat %1 times %2 do %3" होगी. इसमें %2 एक एंड-ऑफ़-रो
इनपुट को दिखाता है. यह स्ट्रिंग, अनुवादक के लिए मुश्किल होती है, क्योंकि %2 के बदले में आने वाली वैल्यू का मतलब समझाना मुश्किल होता है. ऐसा भी हो सकता है कि कुछ भाषाओं में %2 एंड-ऑफ़-रो इनपुट की ज़रूरत न हो. साथ ही, ऐसे कई ब्लॉक हो सकते हैं जो दूसरी लाइन के टेक्स्ट को शेयर करना चाहते हों. एक बेहतर तरीका यह है कि एक से ज़्यादा message और args प्रॉपर्टी का इस्तेमाल किया जाए:
JSON
{
"message0": "repeat %1 times",
"args0": [
{"type": "input_value", ...} // token %1 in message0
],
"message1": "do %1",
"args1": [
{"type": "input_statement", ...} // token %1 in message1
],
}
JSON फ़ॉर्मैट में, message, args, और implicitAlign प्रॉपर्टी की कोई भी संख्या तय की जा सकती है. इनकी शुरुआत 0 से होती है और ये क्रम से बढ़ती हैं. ध्यान दें कि Block Factory, मैसेज को कई हिस्सों में नहीं बांट सकता. हालांकि, ऐसा मैन्युअल तरीके से आसानी से किया जा सकता है.
इंटरपोलेशन टोकन का क्रम
ब्लॉक को स्थानीय भाषा में उपलब्ध कराते समय, आपको किसी मैसेज में इंटरपोलेशन टोकन का क्रम बदलना पड़ सकता है. यह उन भाषाओं के लिए खास तौर पर ज़रूरी है जिनमें शब्दों का क्रम, अंग्रेज़ी से अलग होता है. उदाहरण के लिए, हमने
मैसेज "set %1 to %2" से तय किए गए ब्लॉक से शुरुआत की:
अब एक ऐसी काल्पनिक भाषा पर विचार करें जिसमें "set %1 to %2" को बदलकर
कहना पड़ता है "put %2 in %1". मैसेज (इंटरपोलेशन टोकन के क्रम सहित) में बदलाव करने और आर्ग्युमेंट कलेक्शन को न बदलने पर, यह ब्लॉक मिलता है:

Blockly ने फ़ील्ड का क्रम अपने-आप बदल दिया है, एक डमी इनपुट बनाया है, और बाहरी इनपुट से बदलकर इंटरनल इनपुट का इस्तेमाल किया है.
किसी मैसेज में इंटरपोलेशन टोकन का क्रम बदलने की सुविधा से, स्थानीय भाषा में उपलब्ध कराना आसान हो जाता है. ज़्यादा जानकारी के लिए, JSON मैसेज इंटरपोलेशन देखें.
टेक्स्ट को मैनेज करना
किसी इंटरपोलेशन टोकन के दोनों ओर मौजूद टेक्स्ट से, सफ़ेद जगहें हटा दी जाती हैं.
अगर % वर्ण का इस्तेमाल करके टेक्स्ट लिखा जाता है (जैसे, प्रतिशत के बारे में बताते समय), तो
%% का इस्तेमाल करना चाहिए, ताकि इसे इंटरपोलेशन टोकन के तौर पर इंटरप्रेट न किया जाए.
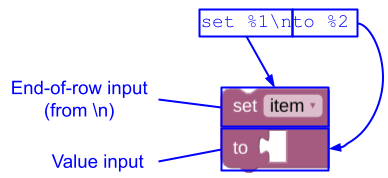
Blockly, मैसेज स्ट्रिंग में मौजूद नई लाइन के किसी भी वर्ण (\n) को, एंड-ऑफ़-रो इनपुट से भी अपने-आप बदल देता है.
JSON
{
"message0": "set %1\nto %2",
"args0": [
{"type": "field_variable", ...}, // token %1
{"type": "input_value", ...}, // token %2
]
}
आर्ग्युमेंट कलेक्शन
हर मैसेज स्ट्रिंग को, उसी नंबर के args कलेक्शन के साथ जोड़ा जाता है. उदाहरण के लिए, message0 को args0 के साथ जोड़ा जाता है. इंटरपोलेशन टोकन
(%1, %2, ...), args कलेक्शन के आइटम को दिखाते हैं. साथ ही, इन्हें
args0 कलेक्शन से पूरी तरह मेल खाना चाहिए. इनमें डुप्लीकेट नहीं होने चाहिए और कोई भी आइटम छूटना नहीं चाहिए. टोकन नंबर, आर्ग्युमेंट कलेक्शन में आइटम के क्रम को दिखाते हैं. ज़रूरी नहीं है कि ये किसी मैसेज स्ट्रिंग में क्रम से दिखें.
आर्ग्युमेंट कलेक्शन में मौजूद हर ऑब्जेक्ट में, type स्ट्रिंग होती है. बाकी पैरामीटर, टाइप के हिसाब से अलग-अलग होते हैं:
आपके पास अपने कस्टम फ़ील्ड और कस्टम इनपुट तय करने और उन्हें आर्ग्युमेंट के तौर पर पास करने का विकल्प भी होता है.
वैकल्पिक फ़ील्ड
हर ऑब्जेक्ट में alt फ़ील्ड भी हो सकता है. अगर Blockly, ऑब्जेक्ट के type को नहीं पहचानता है, तो उसकी जगह alt ऑब्जेक्ट का इस्तेमाल किया जाता है. उदाहरण के लिए, अगर Blockly में field_time नाम का कोई नया फ़ील्ड जोड़ा जाता है, तो इस फ़ील्ड का इस्तेमाल करने वाले ब्लॉक, Blockly के पुराने वर्शन के लिए field_input फ़ॉलबैक तय करने के लिए, alt का इस्तेमाल कर सकते हैं:
JSON
{
"message0": "sound alarm at %1",
"args0": [
{
"type": "field_time",
"name": "TEMPO",
"hour": 9,
"minutes": 0,
"alt":
{
"type": "field_input",
"name": "TEMPOTEXT",
"text": "9:00"
}
}
]
}
alt ऑब्जेक्ट में अपना alt ऑब्जेक्ट हो सकता है. इस तरह, चेनिंग की जा सकती है.
आखिर में, अगर Blockly, args0 कलेक्शन में कोई ऑब्जेक्ट नहीं बना पाता है (किसी भी alt ऑब्जेक्ट को आज़माने के बाद), तो उस ऑब्जेक्ट को अनदेखा कर दिया जाता है.