
Scale your design
Multimodal design
Saba Zaidi and Ulas Kirazci, on designing multimodal Actions at Google I/O 2018
Anatomy of a response
Conversational components
Conversational components are combined to compose the content in the spoken prompts, display prompts, and chips.
Conversational components (prompts and chips) should be designed for every dialog turn.
| Spoken prompt | The content your Action speaks to the user, via TTS or pre-recorded audio |
| Display prompt | The content your Action writes to the user, via printed text on the screen |
| Chips | Suggestions for how the user can continue or pivot the conversation |

Visual components
Visual components include cards, carousels, and other visual assets.
Perfect for scanning and comparing options, visual components are useful if you're presenting detailed information—but they aren't required for every dialog turn.
| Basic card | Use basic cards to display an image and text to users. |
| Browsing carousel | Browsing carousels are optimized for allowing users to select one of many items, when those items are content from the web. |
| Carousel | Carousels are optimized for allowing users to select one of many items, when those items are most easily differentiated by an image. |
| List | Lists are optimized for allowing users to select one of many items, when those items are most easily differentiated by their title. |
| Media response | Media responses are used to play and control the playback of audio content like music or other media. |
| Table | Tables are used to display static data to users in an easily scannable format. |
Group devices by the components used for the response:

For conversations on smart speakers or headphones, the spoken prompts carry the whole conversation and convey the core message.
For conversations in the car or on a smart display, the screen may not always be available to the user. Therefore, the spoken prompts have to carry most of the conversation and convey the core message. The screen can be used for supplementary visual information as well as suggestions to continue or pivot the conversation.
Conversations on a TV, laptop, phone or watch are equally suited for audio input/output and screen-based interactions. The user can choose to continue the conversation in either the spoken or visual modality. Therefore, all the components work together to carry the conversation and convey the core message.
Go from spoken to multimodal

Start with the original spoken prompt from the example sample dialog.

Most of the time, you can simply re-use the same spoken prompt on devices like smart displays, since the need to convey the core of the conversation remains the same.
At this point in the conversation, there isn’t any content that would be appropriate in a visual component like a card or carousel, so none is included.
Be sure to add chips. At a minimum, these should include any options offered in the prompts so the user can quickly tap them to respond.

Since there isn’t any content that would be appropriate in a visual component, there’s no content that can be moved out of the spoken prompt. Therefore, it’s okay to re-use the original.
The display prompt should be a condensed version of the spoken prompt, optimized for scannability. Move any response options to the chips, but be sure to always include the question.
Re-use the same chips you just created.

Start with the original spoken prompt from the example sample dialog.
Note that the spoken list is limited to 6 items (of 17 total) in order to reduce cognitive load. The topics are randomized to not favor one topic over another.

Once again, it’s okay to re-use the same spoken prompt, since we can’t assume the user is looking at the screen.
Including a visual list of all the topics helps the user to browse and select. Note that the visual list of all 17 items (paginated) is shown in alphabetical order, which is easiest for users to search for the topic they want.
Because the list already enumerates the topics that can be chosen, there is no need to include them as chips. Instead, include other options like “None of those” to offer the user a way out.

Here, we can assume that the user has equal access to the audio and the screen. Since the visual modality is better suited to lists, leverage this strength by directing the user to the screen to pick a topic. This allows us to shorten the spoken prompt to a simple list overview and question.
Only the question needs to be maintained in the display prompt.
Re-use the same chip you just created.
Relationship between prompts
In general, spoken prompts are optimized for and follow the conventions of spoken conversations. Display prompts are optimized for and follow the conventions of written conversations. Although slightly different, they should still convey the same core message.
Design prompts for both the ear and the eye. It’s easiest to start with the spoken prompt, imagining what you might say in a human-to-human conversation. Then, condense it to create the display prompt.
Say, essentially, the same thing

Do.
Keep the same narrative from spoken prompt to display prompt.

Don't.
Don't lead the user to a different topic or branching experience.
Display prompts should be condensed versions of their spoken counterparts

Do.
Use condensed display prompts.

Don't.
Don't simply duplicate spoken prompts.
Keep the voice and tone consistent

Do.
Stay in persona.

Don't.
Avoid designing prompts that feel like they’re coming from different personas.
Design spoken and display prompts so they can be understood independently

Do.
If you’re asking a question, make sure it appears in both prompts, so the user knows what to do next.

Don't.
Don't rely on spoken prompts alone to carry the conversation. This can backfire when the user can't hear them. Here, if the user has their device muted, they won’t hear the question.
Relationship between components
Remember that all the components are meant to provide a single unified response.
It’s often easiest to start by writing prompts for a screenless experience, again imagining what you might say in a human-to-human conversation. Then, imagine how the conversation would change if one of the participants was holding a touchscreen. What details can now be omitted from the conversational components? Typically, the display prompt is significantly reduced since the user can just as easily comprehend the information in the visual as they can in the display prompt. Group the information in such a way that the user doesn’t have to look back and forth between the display prompt and visual repeatedly.
Always include the question in the prompts

Do.
Make the call to action clear by asking a question.

Don't.
When presented with this design, many users did not take their turn.
Avoid redundancy

Do.
Spread information across the display prompt and visual component.

Don't.
Don't cram everything from the visual component into the prompts. Focus on just the key information.
Give the short answer in the prompts, and the details in the visuals
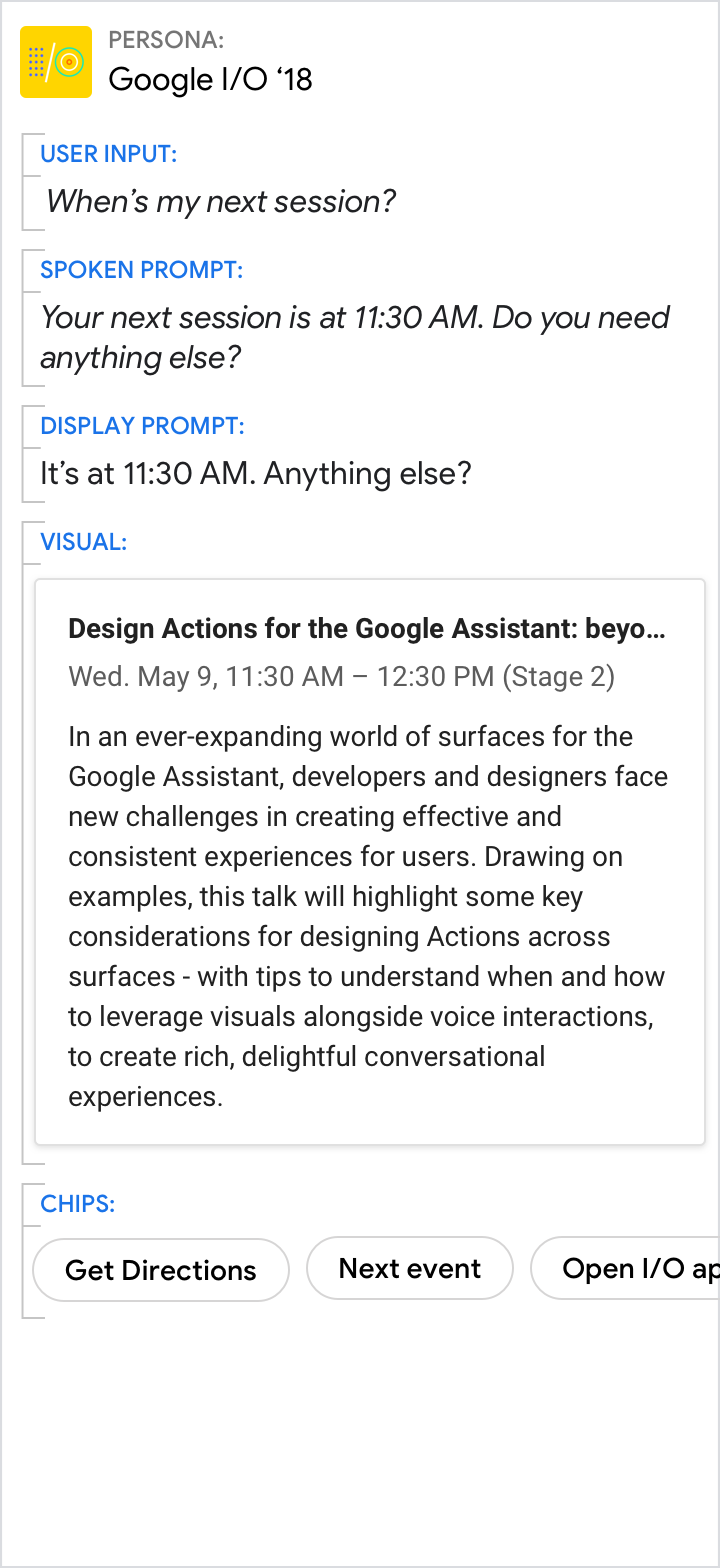
Do.
Use the spoken and display prompts to give the specific answer to the user’s directed question (11:30 AM in this example). Use the visuals for related details.
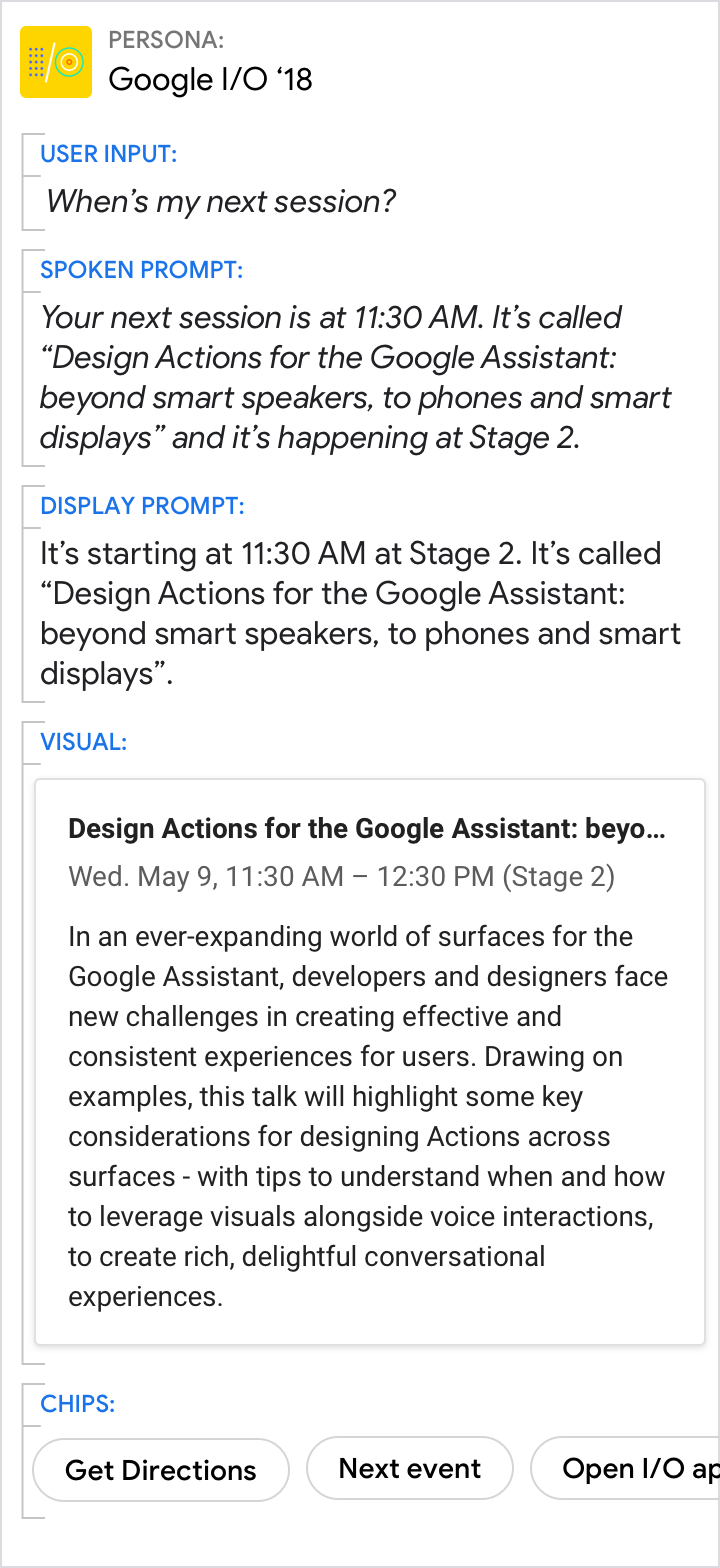
Don't.
Avoid redundancy between the spoken prompt, display prompt, and visuals.
Even when the visuals provide the best answer, make sure the prompts still carry the core of the message

Do.
Use the prompts to give an overview. Use the visuals to provide additional detail.

Don't.
Don’t force the reader to scan and read. Your persona should reduce the work the user needs to do, which includes the effort of scanning through detailed information.
Encourage users to select from lists or carousels, but allow them to continue with their voice

Do.
Encourage the user to look at the list.

Don't.
Don't rattle out the full list.