Strukturierte Daten für Datensätze (Dataset, DataCatalog, DataDownload)
Ein Datensatz lässt sich im Tool Datensatzsuche einfacher finden, wenn du strukturierte Daten verwendest, um ergänzende Informationen wie den Namen, eine Beschreibung, den Ersteller und das Distributionsformat anzugeben. Google möchte das Auffinden von Datensätzen vereinfachen und nutzt daher Schema.org und andere Metadatenstandards, die den Seiten hinzugefügt werden können, die Datensätze beschreiben. Der Zweck dieses Markups besteht darin, das Auffinden von Datensätzen aus Bereichen wie Bio- und Sozialwissenschaften, maschinellem Lernen sowie zivilen und staatlichen Daten zu optimieren.
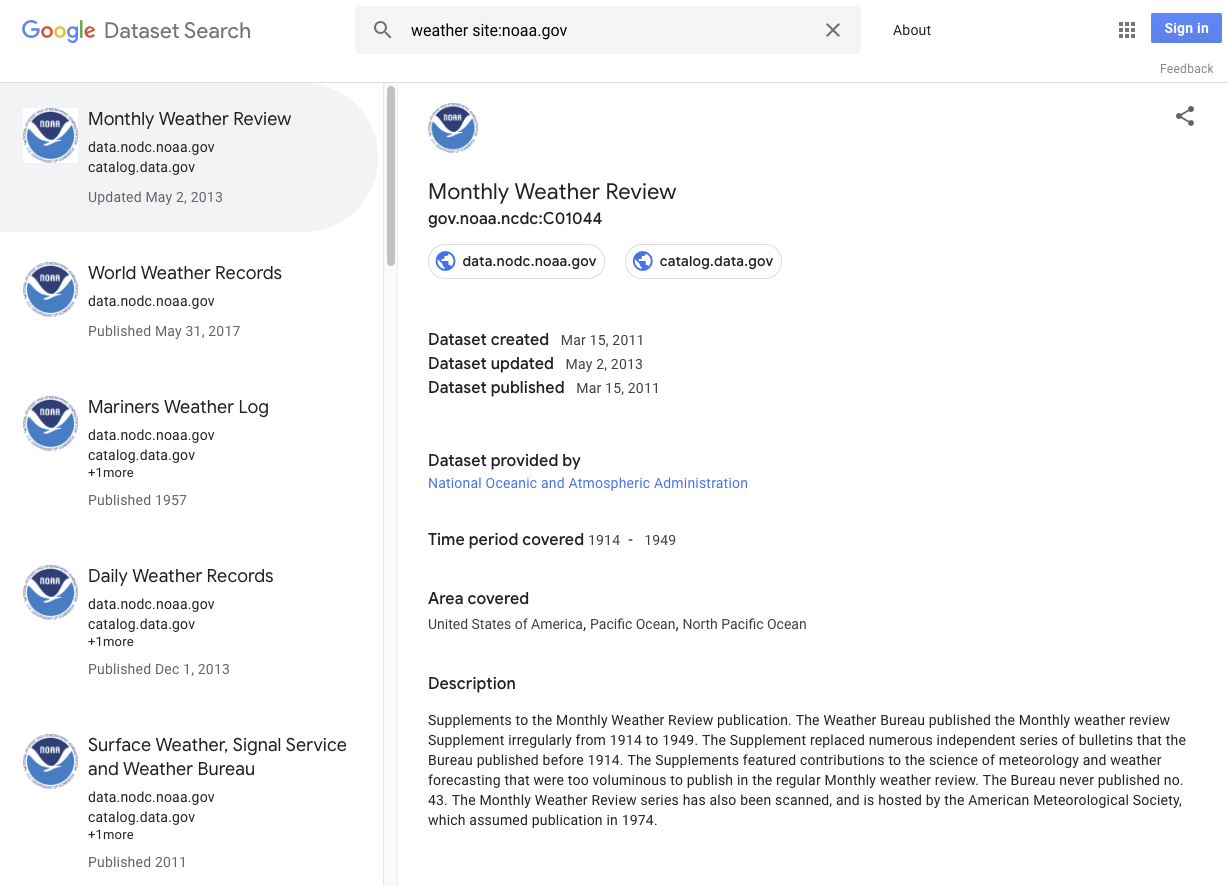
Hier einige Beispiele für mögliche Datensätze:
- Eine Tabelle oder CSV-Datei mit einigen Daten
- Eine organisierte Sammlung von Tabellen
- Eine Datei in einem proprietären Format, die Daten enthält
- Eine Sammlung von Dateien, die gemeinsam einen aussagekräftigen Datensatz bilden
- Ein strukturiertes Objekt mit Daten in einem anderen Format, die du zur Verarbeitung in ein spezielles Tool laden möchtest
- Bilder von Daten
- Dateien für maschinelles Lernen, beispielsweise trainierte Parameter oder Definitionen von Strukturen neuronaler Netzwerke
So fügst du strukturierte Daten hinzu
Strukturierte Daten sind ein standardisiertes Format, mit dem du Informationen zu einer Seite angeben und die Seiteninhalte klassifizieren kannst. Falls strukturierte Daten für dich ein neues Thema sind, findest du hier Informationen dazu, wie sie funktionieren.
In der folgenden Übersicht haben wir zusammengefasst, wie du strukturierte Daten erstellst, testest und veröffentlichst.
- Füge die erforderlichen Properties hinzu. Hier erfährst du, wie du strukturierte Daten je nach verwendetem Format auf der Seite einfügst.
- Folge den Richtlinien.
- Prüfe deinen Code mit dem Test für Rich-Suchergebnisse und behebe alle kritischen Fehler. Zusätzlich solltest du alle nicht kritischen Probleme beheben, die im Tool möglicherweise gemeldet werden. Das kann dabei helfen, die Qualität deiner strukturierten Daten zu verbessern. Das ist jedoch nicht nötig, um für Rich-Suchergebnisse geeignet zu sein.
- Stelle ein paar Seiten mit deinen strukturierten Daten bereit und teste mit dem URL-Prüftool, wie Google die Seiten sieht. Achte darauf, dass die Seiten für Google zugänglich sind und nicht durch eine robots.txt-Datei, das
noindex-Tag oder Anmeldeanforderungen blockiert werden. Wenn die Seiten in Ordnung sind, kannst du Google bitten, deine URLs noch einmal zu crawlen. - Damit Google über künftige Änderungen auf dem Laufenden bleibt, empfehlen wir dir, eine Sitemap einzureichen. Mit der Search Console Sitemap API lässt sich dieser Vorgang automatisieren.
Datensatz aus den Ergebnissen der Datensatzsuche löschen
Wenn du nicht möchtest, dass ein Datensatz in den Ergebnissen der Datensatzsuche erscheint, kannst du mithilfe des robots-meta-Tags steuern, wie dein Datensatz indexiert wird. Es kann allerdings eine Weile dauern (Tage oder Wochen, je nach Crawling-Zeitplan), bis die Änderungen in der Datensatzsuche widergespiegelt werden.
So ermöglichen wir das Auffinden von Datensätzen
Damit wir strukturierte Daten über Datensätze auf Webseiten verstehen können, nutzen wir wahlweise Dataset-Markup von Schema.org oder gleichwertige Strukturen im DCAT-Format (Data Catalog Vocabulary) des W3C. Außerdem untersuchen wir die experimentelle Unterstützung für strukturierte Daten auf der Grundlage von W3C-konformem CSVW. In Anlehnung an die Best Practices für die Datensatzbeschreibung werden wir unseren Ansatz kontinuierlich weiterentwickeln. Weitere Informationen zu unserem Ansatz findest du im englischsprachigen Blogpost Making it easier to discover datasets.
Beispiele
Hier siehst du ein Beispiel für Datensätze mit der (bevorzugten) JSON-LD- und Schema.org-Syntax im Test für Rich-Suchergebnisse. Das gleiche Schema.org-Vokabular kann auch in der RDFa 1.1- oder Mikrodaten-Syntax verwendet werden. Außerdem kannst du das W3C-DCAT-Vokabular zum Beschreiben der Metadaten verwenden. Das folgende Beispiel basiert auf der Beschreibung eines realen Datensatzes.
Hier siehst du ein Beispiel für einen Datensatz in JSON-LD:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Hier siehst du ein Beispiel für einen Datensatz in RDFa unter Verwendung des DCAT-Vokabulars (wird im Test für Rich-Suchergebnisse nicht unterstützt):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Richtlinien
Websites müssen den Richtlinien für strukturierte Daten entsprechen. Zusätzlich empfehlen wir die folgenden Best Practices für Sitemaps und Best Practices für Quelle und Herkunft.
Best Practices für Sitemaps
Wenn du eine XML-Sitemap-Datei verwendest, kann Google deine URLs einfacher finden. Mithilfe von XML-Sitemap-Dateien und sameAs-Markup wird dokumentiert, wie Datensatzbeschreibungen auf deiner Website veröffentlicht werden.
Wenn du ein Datensatz-Repository hast, gibt es auf deiner Website wahrscheinlich mindestens zwei Seitentypen: kanonische Seiten – also Landingpages – für jeden Datensatz und Seiten, die mehrere Datensätze auflisten, wie etwa Suchergebnisse oder Datensatzteilmengen. Wir empfehlen dir, strukturierte Daten für Datensätze den kanonischen Seiten hinzuzufügen. Mit der Property sameAs stellst du eine Verknüpfung zur kanonischen Seite her, wenn du mehreren Kopien des Datensatzes, wie Auflistungen auf Suchergebnisseiten, strukturierte Daten hinzufügst.
Best Practices für Quelle und Herkunft
Offene Datensätze werden häufig mehrfach veröffentlicht, aggregiert und auf der Basis anderer Datensätze erstellt. Im Folgenden findest du eine erste Skizze unseres Ansatzes, mit dem wir Situationen darstellen, in denen ein Datensatz eine Kopie eines anderen Datensatzes ist oder in anderer Weise auf diesem basiert.
- Wenn der Datensatz oder die Beschreibung eine einfache Neuveröffentlichung von bereits anderweitig veröffentlichtem Material ist, verwende die Property
sameAszur Kennzeichnung der kanonischsten URLs für das Original. Der Wert vonsameAsmuss den Datensatz eindeutig kennzeichnen. Mit anderen Worten: Zwei unterschiedliche Datensätze dürfen nicht denselbensameAs-Wert haben. - Falls der wieder veröffentlichte Datensatz – gegebenenfalls einschließlich seiner Metadaten – beträchtlich verändert wurde, verwende die Property
isBasedOn. - Wenn ein Datensatz von mehreren Originalen abstammt oder diese aggregiert, verwende ebenfalls die Property
isBasedOn. - Mit der Property
identifierkannst du relevante Digital Object Identifiers (DOIs) oder Compact Identifiers anhängen. Wenn der Datensatz mehrere IDs enthält, verwende die Propertyidentifiermehrfach. In JSON-LD wird dies mithilfe der JSON-Listensyntax dargestellt.
Wir hoffen, unsere Empfehlungen anhand des Nutzerfeedbacks optimieren zu können, und zwar insbesondere in den Bereichen Herkunft und Versionierung und bei den Datumsangaben im Zusammenhang mit der Veröffentlichung von Zeitreihen. Wir laden dich außerdem ein, an den Diskussionen in der Community teilzunehmen.
Empfehlungen für textbasierte Properties
Wir empfehlen, alle textbasierten Properties auf maximal 5.000 Zeichen zu beschränken. Die Google Datensatzsuche verwendet nur die ersten 5.000 Zeichen jeder textbasierten Property. Namen und Titel bestehen normalerweise nur aus wenigen Wörtern oder einem kurzen Satz.
Bekannte Fehler und Warnungen
Im Test für Rich-Suchergebnisse von Google und in anderen Validierungssystemen können Fehler oder Warnungen auftreten. Validierungssysteme empfehlen Organisationen eventuell auch, Kontaktdaten einschließlich eines contactType einzubinden. Nützliche Werte hierfür sind customer service, emergency, journalist, newsroom und public engagement.
Fehler für csvw:Table als unerwarteter Wert der Property mainEntity kannst du ignorieren.
Definitionen strukturierter Datentypen
Damit die Inhalte als Rich-Suchergebnis angezeigt werden können, musst du alle erforderlichen Properties hinzufügen. Empfohlene Propertys bieten darüber hinaus die Möglichkeit, weitere Informationen in den Inhalt aufzunehmen und so die Angebotsqualität für Nutzer weiter zu verbessern.
Mit dem Test für Rich-Suchergebnisse kannst du dein Markup überprüfen.
Das Hauptaugenmerk liegt auf der Beschreibung von Informationen zu einem Datensatz bzw. dessen Metadaten und der Beschreibung seiner Inhalte. So geben Datensatz-Metadaten beispielsweise an, welchen Zweck der Datensatz erfüllt, welche Variablen er misst oder wer ihn erstellt hat. Nicht enthalten sind dagegen zum Beispiel konkrete Werte für die Variablen.
Dataset
Die vollständige Definition von Dataset findest du unter schema.org/Dataset.
Du kannst zusätzliche Informationen zur Veröffentlichung des Datensatzes angeben, etwa die Lizenz, den Zeitpunkt der Veröffentlichung, den DOI oder einen sameAs-Wert, der auf eine kanonische Version des Datensatzes in einem anderen Repository verweist. Füge identifier, license und sameAs für Datensätze hinzu, um Informationen zu Herkunft und Lizenz zur Verfügung zu stellen.
Die von Google unterstützten Properties sind folgende:
| Erforderliche Properties | |
|---|---|
description
|
Text
Eine kurze Zusammenfassung, die den Datensatz beschreibt Richtlinien
|
name
|
Text
Ein aussagekräftiger Name für den Datensatz. Beispiel: „Schneehöhen in der nördlichen Hemisphäre“ Richtlinien
Empfohlen: Nicht empfohlen: |
| Empfohlene Properties | |
|---|---|
alternateName
|
Text
Alternative Namen für diesen Datensatz, z. B. Aliasse oder Abkürzungen. Beispiel im JSON-LD-Format: "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person oder Organization
Der Ersteller oder Autor dieses Datensatzes. Verwende die ORCID ID als Wert für die Property "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text oder CreativeWorkKennzeichnet wissenschaftliche Artikel, die vom Datenanbieter empfohlen und zusätzlich zum Datensatz selbst zitiert werden. Gib die Zitation für den Datensatz selbst mithilfe von anderen Properties an, beispielsweise "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Zusätzliche Richtlinien
|
funder
|
Person oder OrganizationEine Person oder Organisation, die diesen Datensatz finanziell unterstützt. Verwende die ORCID ID als Wert für die Property "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart oder isPartOf
|
URL oder Dataset
Wenn der Datensatz eine Sammlung kleinerer Datensätze ist, kennzeichne eine solche Beziehung mit der Property "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text, oder PropertyValue
Eine ID, z. B. ein DOI oder ein Compact Identifier. Wenn der Datensatz mehrere IDs enthält, verwende die Property |
isAccessibleForFree
|
Boolean
Gibt an, ob auf das Dataset kostenlos zugegriffen werden kann. |
keywords
|
Text
Stichwörter, die den Datensatz zusammenfassen |
license
|
URL oder CreativeWorkEine Lizenz, unter der der Datensatz verbreitet wird. Beispiel: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Zusätzliche Richtlinien
|
measurementTechnique
|
Text oder URLDas Verfahren, die Technologie oder die Methodik, die in einem Datensatz verwendet wird. Das kann den in |
sameAs
|
URL
Die URL einer Referenzwebseite, auf der eindeutig die Identität des Datensatzes erkennbar ist. |
spatialCoverage |
Text oder Place
Du kannst einen einzelnen Punkt angeben, der den räumlichen Aspekt des Datensatzes beschreibt. Binde diese Property nur ein, wenn der Datensatz eine räumliche Dimension hat. Beispielsweise könnte dies ein einzelner Punkt sein, an dem alle Messungen erfasst wurden, oder es könnten die Koordinaten eines Begrenzungsrahmens für einen Bereich sein. Punkte "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Formen Verwende "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } Punkte innerhalb der Properties Benannte Orte "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
Die Daten im Datensatz erstrecken sich über einen bestimmten Zeitrahmen. Binde diese Property nur ein, wenn der Datensatz eine zeitliche Dimension hat. Schema.org verwendet zur Beschreibung von Zeiträumen und -punkten den Standard ISO 8601. Du kannst Datumsangaben je nach Datensatzintervall unterschiedlich beschreiben. Offene Intervalle gibst du dabei mit zwei Dezimalpunkten ( Einzelnes Datum "temporalCoverage" : "2008" Zeitraum "temporalCoverage" : "1950-01-01/2013-12-18" Offener Zeitraum "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text oder PropertyValueDie Variable, die von diesem Datensatz gemessen wird. Beispiel: Temperatur oder Druck. |
version
|
Text oder NumberDie Versionsnummer für den Datensatz |
url
|
URL
Die Position einer Seite, die den Datensatz beschreibt |
DataCatalog
Die vollständige Definition von DataCatalog findest du unter schema.org/DataCatalog.
Datensätze werden häufig in Repositories veröffentlicht, die viele weitere Datensätze enthalten. Derselbe Datensatz kann außerdem in mehreren derartigen Repositories enthalten sein. Du kannst einen Datenkatalog, zu dem dieser Datensatz gehört, durch einen direkten Verweis angeben. Dazu verweist du mit den folgenden Properties direkt darauf:
| Empfohlene Properties | |
|---|---|
includedInDataCatalog
|
DataCatalog
Der Katalog, zu dem der Datensatz gehört
|
DataDownload
Die vollständige Definition von DataDownload findest du unter schema.org/DataDownload. Füge zusätzlich zu den „Dataset“-Properties die folgenden Properties hinzu, die Optionen für den Download von Datensätzen angeben.
Die Property distribution beschreibt, wie der Datensatz selbst abgerufen wird, denn die URL verweist häufig auf die Landingpage, die den Datensatz beschreibt. distribution dagegen gibt an, wo und in welchem Format die eigentlichen Daten abgerufen werden können. Die Property kann mehrere Werte haben, beispielsweise eine URL für eine CSV-Version und eine andere URL für eine Excel-Version.
| Erforderliche Properties | |
|---|---|
distribution.contentUrl
|
URL
Der Link zum Download |
| Empfohlene Properties | |
|---|---|
distribution
|
DataDownload
Die Beschreibung des Speicherorts, von dem der Datensatz heruntergeladen werden kann, und des Dateiformats für den Download
|
distribution.encodingFormat
|
Text oder URLDas Dateiformat der Distribution
|
Tabellarische Datensätze
Ein tabellarischer Datensatz ist in erster Linie als Raster aus Zeilen und Spalten organisiert. Für Seiten, in die tabellarische Datensätze eingebettet werden, kannst du auch expliziteres Markup erstellen, das auf dem grundlegenden Ansatz aufbaut. Gegenwärtig verstehen wir hierunter eine Variante von CSVW, die parallel zu für Nutzer gedachten tabellarischen Inhalten auf der HTML-Seite zur Verfügung gestellt wird. Informationen zu CSVW („CSV on the Web“) findest du beim W3C.
Im nachfolgenden Beispiel siehst du eine kleine Tabelle, die im CSVW-Format in JSON-LD codiert ist. Im Testtool für Rich-Suchergebnisse gibt es hierzu verschiedene bekannte Fehler.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Rich-Suchergebnisse mit der Search Console beobachten
Die Search Console ist ein Tool, mit dem du die Leistung deiner Seiten in der Google-Suche beobachten kannst. Damit deine Website in die Google-Suchergebnisse aufgenommen wird, musst du dich nicht für die Search Console registrieren. Du kannst aber mithilfe der Search Console möglicherweise besser nachvollziehen, wie deine Website von Google gesehen wird, und sie bei Bedarf optimieren. Wir empfehlen, die Search Console in den folgenden Fällen aufzusuchen:
- Nach der erstmaligen Bereitstellung von strukturierten Daten
- Nach der Veröffentlichung neuer Vorlagen oder der Aktualisierung deines Codes
- Zur regelmäßigen Analyse der Zugriffe
Nach der erstmaligen Bereitstellung von strukturierten Daten
Nachdem Google deine Seiten indexiert hat, kannst du mithilfe des entsprechenden Statusberichts für Rich-Suchergebnisse nach Problemen suchen. Im Idealfall nimmt die Anzahl der gültigen Elemente zu, die Anzahl der ungültigen Elemente aber nicht. Wenn Probleme mit deinen strukturierten Daten auftreten:
- Korrigiere die ungültigen Elemente.
- Prüfe eine Live-URL, um festzustellen, ob das Problem weiterhin besteht.
- Beantrage die Validierung mithilfe des Statusberichts.
Nachdem du neue Vorlagen veröffentlicht oder deinen Code aktualisiert hast
Wenn du wichtige Änderungen an deiner Website vornimmst, solltest du auf eine Zunahme von ungültigen Elementen in strukturierten Daten achten.- Wenn du eine Zunahme der ungültigen Elemente feststellst, hast du möglicherweise eine neue Vorlage eingeführt, die nicht funktioniert. Eventuell interagiert deine Website auch auf eine neue und fehlerhafte Art mit der vorhandenen Vorlage.
- Wenn du eine Abnahme der gültigen Elemente, aber keine Zunahme der ungültigen Elemente feststellst, sind möglicherweise keine strukturierten Daten mehr in deine Seiten eingebettet. Verwende das URL-Prüftool, um die Ursache des Problems zu ermitteln.
Zur regelmäßigen Analyse der Zugriffe
Analysiere mit dem Leistungsbericht die Zugriffe über die Google Suche. Die Daten geben Aufschluss darüber, wie oft deine Seite als Rich-Suchergebnis angezeigt wird, wie oft Nutzer darauf klicken und wie hoch deine durchschnittliche Position in den Suchergebnissen ist. Diese Ergebnisse lassen sich auch mit der Search Console API automatisch abrufen.Fehlerbehebung
Falls du Probleme bei der Implementierung oder Fehlerbehebung von strukturierten Daten hast, versuch es mit diesen Lösungsansätzen:
- Wenn du ein CMS (Content-Management-System) verwendest oder jemand anderes sich um deine Website kümmert, bitte diese Person oder den CMS-Support, dir zu helfen. Leite am besten alle Search Console-Nachrichten, in denen das Problem beschrieben ist, entsprechend weiter.
- Google kann nicht garantieren, dass Funktionen, die strukturierte Daten nutzen, in den Suchergebnissen angezeigt werden. Eine Liste mit häufigen Gründen, aus denen Google deine Inhalte möglicherweise nicht in einem Rich-Suchergebnis anzeigt, findest du im Artikel Allgemeine Richtlinien für strukturierte Daten.
- Möglicherweise sind deine strukturierten Daten fehlerhaft. Sehen Sie sich die Liste der Fehler bei strukturierten Daten und den Bericht zu strukturierten Daten, die nicht geparst werden können an.
- Wenn auf deiner Seite eine manuelle Maßnahme gegen strukturierte Daten vorliegt, werden die strukturierten Daten auf der Seite ignoriert, obwohl die Seite weiter in den Ergebnissen der Google Suche erscheinen kann. Nutze den Bericht zu manuellen Maßnahmen, um Probleme mit strukturierten Daten zu beheben.
- Lies dir die Richtlinien noch einmal durch und prüfe, ob deine Inhalte den Richtlinien entsprechen. Das Problem kann durch Spaminhalte oder die Verwendung von Spam-Markup verursacht sein. Allerdings ist es auch möglich, dass das Problem kein Syntaxproblem ist und daher beim Test für Rich-Suchergebnisse nicht identifiziert werden kann.
- Lies dir den Abschnitt zur Fehlerbehebung bei fehlenden Rich-Suchergebnissen und bei Rückgang der Gesamtzahl der Rich-Suchergebnisse durch.
- Räume genug Zeit für das erneute Crawling und die Neuindexierung ein. Nachdem eine Seite veröffentlicht wurde, kann es einige Tage dauern, bis sie von Google gefunden und gecrawlt wurde. Antworten auf allgemeine Fragen zum Crawlen und Indexieren erhältst du auf der Seite Häufig gestellte Fragen zum Crawling und zur Indexierung in der Google Suche.
- Oder du postest deine Frage im Forum von Google Search Central.
Ein bestimmter Datensatz wird nicht in den Ergebnissen der Google Datensatzsuche angezeigt
error Problemursache: Deine Website enthält auf der Seite, die die Datensätze beschreibt, keine strukturierten Daten oder die Seite wurde noch nicht gecrawlt.
done Problem beheben
- Kopiere den Link der Seite, die in den Ergebnissen der Datensatzsuche angezeigt werden soll, und füge ihn im Testtool für Rich-Suchergebnisse ein. Wenn die Meldung „Die in diesem Test bekannten Rich-Suchergebnisse sind für diese Seite nicht möglich“ oder „Rich-Suchergebnisse nicht für das gesamte Markup möglich“ angezeigt wird, ist auf der Seite kein Dataset-Markup vorhanden oder es ist falsch. Wie du das Problem beheben kannst, erfährst du im Abschnitt So fügst du strukturierte Daten hinzu.
- Falls sich Markup auf der Seite befindet, wurde sie möglicherweise noch nicht gecrawlt. Du kannst den Crawling-Status in der Search Console prüfen.
Das Unternehmenslogo fehlt oder wird nicht richtig in den Ergebnissen angezeigt
error Problemursache: Möglicherweise fehlt auf deiner Seite das schema.org-Markup für Organisationslogos oder Google kennt dein Unternehmen noch nicht.
done Problem beheben
- Füge deiner Seite strukturierte Logo-Daten hinzu.
- Richte Unternehmensinformationen bei Google ein.