
传统的企业间潜在客户发掘往往依赖于购买静态目录或行业名单来确定区域潜力。不过,这些静态兴趣点 (POI) 数据集几乎立即就会过时。由于这些数据往往缺乏最新的营业状态或精细的地点类型分类,因此现场销售团队可能会浪费宝贵的时间来追寻已永久停业、分类错误或与理想客户资料无关的企业。
本指南提供了一个工作流,可使用 Places Insights 和 Places API 来弥合这一差距。通过将现有业务与地点 ID 相关联,您可以使用 BigQuery 找出某个区域内尚未纳入客户关系管理 (CRM) 数据库的每个运营业务。本指南将向您介绍如何构建排除引擎,以便为您的现场销售代表提供高度精准且经过验证的潜在客户名单。
示例应用
假设某销售终端 (POS) 提供商计划在纽约市拓展现场销售业务。通常,组织会提取一份报告,其中包含每个邮政编码对应的食品和饮料场所总数。这种方法存在销售代表依赖过时数据(例如已永久停业的地点)或不相关潜在客户(例如没有店面的私人餐饮厨房)的风险。不妨想象一下,如果采用地点数据分析这种现代化方法,会是什么样的效果。地点数据分析利用了 Google 地图的全球规模和经过多个来源验证的最新数据。地点数据分析支持近 500 个地点类别和 70 多种属性,可让您根据特定商家类型(例如 scandinavian_restaurant)、营业时间和提供的服务(例如 accepts_credit_cards)以高精度细化潜在客户。通过将地点数据分析与内部 CRM 进行交叉对比,您可以为销售团队提供一份高度精细的潜在客户名单,其中包含尚未联系但极具潜力的潜在客户。
解决方案工作流
本指南提供了一个技术框架,用于创建动态“潜在客户地图”,该地图会自动滤除现有业务,仅留下可供销售团队跟进的全新运营潜在客户。
四步架构
- 定义目标地点类型:将理想客户资料与地点类型相关联。
- 确定高潜力区域:在 BigQuery 中执行 Places Count 函数,以生成运营目标企业的密度热图。
- 将 CRM 数据标准化为地点 ID:通过数据清理流水线处理非结构化 CRM 记录,利用地址验证、地理编码和 Places API 查找现有客户的地点 ID。
- 执行空白区排除:将 CRM 地点 ID 与 BigQuery 中的地点数据分析数据联接,以动态过滤掉现有客户,并输出全新的潜在客户名单。
前提条件
在开始之前,请确保您满足以下条件:
Google Cloud 项目:
- 启用了结算功能的 Google Cloud 项目。
数据访问权限:
- BigQuery 中的 地点数据分析订阅。
- 您自己的 CRM 数据集(例如 BigQuery 表),其中包含现有客户的商家名称和地址,可作为排除列表。
Google Maps Platform:
- API 密钥。
- 您的密钥已启用以下 API:
IAM 权限:
- 确保您的用户账号或服务账号具有以下 IAM 角色,以便执行查询和管理数据集:
角色 ID BigQuery Data Editor roles/bigquery.dataEditorBigQuery User roles/bigquery.user
- 确保您的用户账号或服务账号具有以下 IAM 角色,以便执行查询和管理数据集:
费用意识:
- 本教程使用 Google Cloud 的收费组件。请注意与以下方面相关的潜在费用:
- BigQuery:根据查询执行期间使用的计算槽或处理的数据量收费。
- 地点数据分析:根据查询使用情况收费。
- Google Maps Platform:按请求次数收费,适用于 Address Validation API、Geocoding API 和文本搜索 API。
- 本教程使用 Google Cloud 的收费组件。请注意与以下方面相关的潜在费用:
第 1 步:定义目标地点类型
地点数据分析支持近 500 个地点类别和 70 多种属性(例如营业时间、支付方式和营业状态)。不加区分地查询整个数据集效率低下且成本高昂。
作为基础步骤,请使用 Gemini 等 LLM 将内部客户资料转换为地点类型,以便在构建地点数据分析的查询时使用。这种宏观分类法定义可确保您后续的 BigQuery 搜索具有高度针对性,从而减少计算处理开销。
例如,如果您要为销售终端系统设计工作流,可以向 Gemini 提供地点类型列表,并使用以下提示:
“你是一位市场分析师。在受支持的 Google 地图地点类型中,哪些是销售终端系统提供商的主要目标?请说明做出此决定的理由。”
根据此提示,Gemini 会分析分类,并返回一个有针对性的相关地点类型子集,供您在 BigQuery types 过滤条件中使用:
| 主要类别 | 理由 | 关键地点类型 |
|---|---|---|
| 餐饮 | 需要快速的交易处理、餐桌管理、订单开票和消费处理。 | restaurant、bar、cafe、coffee_shop |
| 购物 | 需要强大的库存跟踪、条形码扫描、退货处理和会员集成功能。 | clothing_store、grocery_store、supermarket、convenience_store |
| 服务以及健康与保健 | 需要集成预约、日程安排、客户个人资料和佣金跟踪功能。 | hair_salon、beauty_salon、spa、massage |
| 娱乐、休闲和体育 | 需要快速处理客户的紧急需求、扫描数字票券,并快速销售零食。 | movie_theater、amusement_park、bowling_alley、stadium |
在本指南中,我们将重点介绍餐饮类别的建议地点类型。
第 2 步:提取商家数量,以确定高潜力区域
若要找出潜在商机,您首先需要从宏观角度了解商家密度。您可以在 BigQuery 中执行地点数量函数(例如 PLACES_COUNT_PER_H3 或 PLACES_COUNT_PER_GEO)来实现此目的。
虽然您可以直接查询数据集,但“地点数量”函数是预定义的优化 SQL 查询,不会强制执行至少 5 个地点的标准汇总阈值(标准直接查询会省略包含 1-4 家企业的行;不过,这些函数可让您准确了解即使只有一个潜在客户,也位于何处)。至关重要的是,这些函数使用 sample_place_ids 列,每个地理区域最多返回 250 个 Place ID 的数组。这既为区域规划人员提供了统计热图,也为潜在客户发掘提供了所需的基础标识符。
以下查询演示了如何使用公共数据集动态检索复杂的多边形(纽约市的整个边界),然后将该地理位置传递给 Places Count 函数。通过在整个城市范围内以更广的分辨率 (8) 利用 H3 空间索引,您可以生成宏观密度图。
此外,通过选择所有列 (SELECT *),该函数会返回 geography 列,即表示 H3 单元格的多边形。这样一来,您就可以立即将 BigQuery 结果导入商业智能工具(例如 Looker Studio),以创建填充地图可视化图表,直观地显示市场热点。
-- Illustrative logic: Extracting target business counts per H3 cell across New York City
DECLARE geo GEOGRAPHY;
-- Get the geography for New York City using the Overture Maps public dataset
SET geo = (SELECT geometry FROM `bigquery-public-data.overture_maps.division_area`
WHERE country = 'US' AND subtype = 'locality' AND names.primary = 'New York' LIMIT 1);
SELECT *
FROM `YOUR_PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', geo,
'h3_resolution', 8,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
)
ORDER BY count DESC;
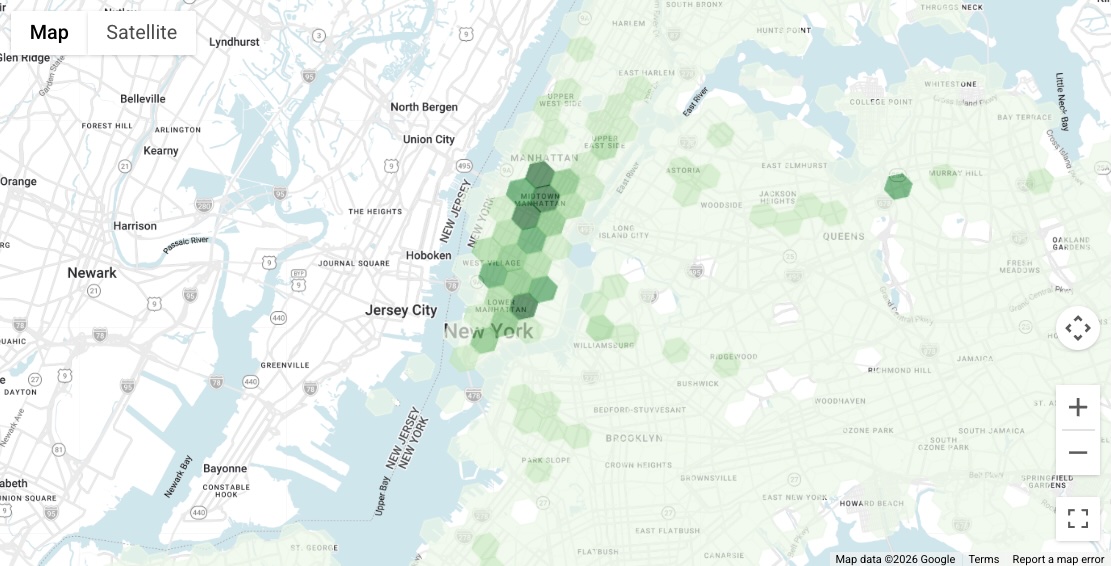
从生成的视觉效果中可以看出,曼哈顿各处都有明显的高密度目标商家区域。在本文档的其余部分,我们将重点介绍其中一个高潜力区域:联合广场附近的区域,并专注于在该区域开展潜在客户发掘工作。
第 3 步:将 CRM 数据归一化为 Place ID
若要执行排除分析,您首先需要将 CRM 记录转换为地点 ID。 由于 CRM 数据通常是非结构化数据,因此将原始文本传递到搜索 API 会导致匹配率较低。使用此两步流水线可清理地址、考虑区域 API 覆盖范围,并保证您为 BigQuery 提取正确的营业场所 ID。
假设您的 CRM 中有以下 5 位位于纽约市的餐厅客户:
| 地名 | 地址 |
|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States |
| Gramercy Tavern | 42 E 20th St, New York, NY 10003, United States |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States |
| Union Square Cafe | 101 E 19th St, New York, NY 10003, United States |
由于这些记录包含非结构化文本,因此您无法直接将它们与 BigQuery 中的地点数据分析数据联接。请改为通过以下流水线处理每一行,以标准化文本并提取地点 ID。
第 3a 步:地址清理和直接匹配
请先对地址数据进行标准化处理。根据目标国家/地区选择 API:
对于支持的地区,请将串联的 CRM 商家名称和地址传递给 API。检查响应的 result.geocode.placeTypes 数组:
- 商家匹配:如果其中包含
establishment或point_of_interest,则表示 API 已成功解析商家。将此placeId附加到您的数据集,然后转到下一个 CRM 记录。此条目无需进一步 API 调用。 - 非实体店匹配:如果不包含这些商家类型,则 API 无法明确确认商业实体。返回的地点 ID 表示地貌(例如建筑物、街道或城市)。请勿将此地点 ID 用于 BigQuery,否则排除联接会失败。请改为保存
result.address.formattedAddress并继续执行第 3b 步。
选项 2:Geocoding API
对于地址验证不支持的区域,请仅将 CRM 地址传递到 Geocoding API 中。请勿添加商家名称,因为 Geocoding API 可能会返回不可预测的结果。提取所得的 formattedAddress,然后继续执行第 3b 步。
高级架构:使用 LLM 处理非结构化数据
如果您的 CRM 数据质量非常差,例如商家名称和地址混杂在单个自由文本备注字段中,请使用 Gemini 等 LLM 对记录进行预处理。您可以提示 Gemini 从营业地点中清晰地解析出商家名称,然后再将其馈送到此流水线中。
第 3b 步:解析营业实体
如果第 3a 步仅返回清理后的地址,请将其与原始 CRM 商家名称串联,然后将其传递给 文本搜索 API。先将地址标准化,可显著提高匹配率。
为了优化性能和费用,请使用字段掩码 (X-Goog-FieldMask:
places.id) 并将 "pageSize": 1 设置为确保仅返回高度相符的地点 ID。
文本搜索请求示例:
curl -X POST -d '{
"textQuery" : "Gramercy Tavern 42 E 20th St, New York, NY 10003-1324, USA",
"pageSize": 1
}' \
-H 'Content-Type: application/json' -H 'X-Goog-Api-Key: YOUR_API_KEY' \
-H 'X-Goog-FieldMask: places.id' \
'https://places.googleapis.com/v1/places:searchText'
流水线输出
通过这个两步流水线处理 CRM 记录后,无论是在第 3a 步中成功提取了 ID,还是在第 3b 步中使用文本搜索解析了 ID,您的最终目标都是向数据集中附加一个新的 place_id 列。生成的表格现在可以上传到 BigQuery 中,作为排除列表使用。
| 地名 | 地址 | 地点 ID |
|---|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| Gramercy Tavern | 42 E 20th St, New York, NY 10003, United States | ChIJvSQIgqFZwokRFYQbJdzceSs |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States | ChIJQ7XpyqNZwokRQpVfvGEViWM |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States | ChIJFZh0PABZwokRVzoJu0o-mLY |
| Union Square Cafe | 101 E 19th St, New York, NY 10003, United States | ChIJxTHke6JZwokRCLWVd99eDBw |
第 4 步:在 BigQuery 中执行空白区排除分析
将现有客户与地点 ID 相关联后,使用地点数函数查找新潜在客户。
在此示例中,我们将搜索联合广场 (40.73595, -73.99043) 半径 850 米范围内的营业目标商家(餐厅、酒吧、咖啡馆和咖啡店)。为了更精细地查看街道级路线,我们将 PLACES_COUNT_PER_H3 函数的分辨率提高到 10。
由于该函数会在 sample_place_ids 列中以数组形式返回 Place ID,因此我们必须对该数组进行 UNNEST,以便将每个潜在商家放在单独的行中。然后,我们针对已知的客户地点 ID 执行 LEFT JOIN。
为了证明排除逻辑在此演示中有效,以下查询使用 CASE 语句来标记结果,而不是完全过滤掉结果。它还会明确地将现有客户排序到结果表格的最顶部,以便您验证他们是否成功匹配。
SQL 查询
WITH existing_customers AS (
-- 1. Simulate the uploaded CRM table
SELECT * FROM UNNEST([
'ChIJc1Vf7KFZwokR1YL2Rn9oxi8', -- Boucherie Union Square
'ChIJvSQIgqFZwokRFYQbJdzceSs', -- Gramercy Tavern
'ChIJQ7XpyqNZwokRQpVfvGEViWM', -- Barn Joo Union Square
'ChIJFZh0PABZwokRVzoJu0o-mLY', -- LOS TACOS No.1
'ChIJxTHke6JZwokRCLWVd99eDBw' -- Union Square Cafe
]) AS place_id
),
target_area_businesses AS (
-- 2. Query Places Insights for target businesses in the radius
SELECT
h3_cell_index,
place_id
FROM `places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_GEOGPOINT(-73.99043, 40.73595),
'geography_radius', 850,
'h3_resolution', 10,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
),
UNNEST(sample_place_ids) AS place_id
)
-- 3. The "Proof" Output: Flag them instead of filtering them out
SELECT
t.h3_cell_index,
t.place_id,
-- Flag whether the LEFT JOIN found a match in the CRM table
CASE
WHEN e.place_id IS NOT NULL THEN 'Existing Customer (To Be Excluded)'
ELSE 'Net-New Lead'
END AS lead_status,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
ORDER BY
-- Explicitly sort the existing customers to the top (0 comes before 1)
CASE WHEN e.place_id IS NOT NULL THEN 0 ELSE 1 END ASC;
查询结果
以下是查询输出的摘录,显示了如何成功识别现有客户并将其与同一细粒度 H3 单元格中的全新潜在客户分开。
请注意,该查询如何使用 CONCAT 语句来构建跨平台 Google 地图网址,并使用 place_id。这样会自动生成 actionable_maps_url 列,为您的销售团队提供一个可点击的即时链接,以便在 Google 地图移动应用或浏览器中加载确切的商家。
h3_cell_index |
place_id |
lead_status |
actionable_maps_url |
|---|---|---|---|
| 8a2a100d2767fff | ChIJQ7XpyqNZwokRQpVfvGEViWM | 现有客户(要排除的对象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJQ7XpyqNZwokRQpVfvGEViWM |
| 8a2a100d20effff | ChIJvSQIgqFZwokRFYQbJdzceSs | 现有客户(要排除的对象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJvSQIgqFZwokRFYQbJdzceSs |
| 8a2a100d2397fff | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 | 现有客户(要排除的对象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| 8a2a100d2397fff | ChIJFZh0PABZwokRVzoJu0o-mLY | 现有客户(要排除的对象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJFZh0PABZwokRVzoJu0o-mLY |
| 8a2a100d23b7fff | ChIJxTHke6JZwokRCLWVd99eDBw | 现有客户(要排除的对象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJxTHke6JZwokRCLWVd99eDBw |
| 8a2a1072c96ffff | ChIJ6atD-WRZwokRULgcZ4TWin8 | 全新潜在客户 | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ6atD-WRZwokRULgcZ4TWin8 |
| 8a2a1072c96ffff | ChIJ09yg-llZwokRKAgp0jg6TCU | 全新潜在客户 | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ09yg-llZwokRKAgp0jg6TCU |
使用 Places UI Kit 直观呈现潜在客户
您可以将 place_ids 直接传递到 Places UI Kit 中,而不是提供原始的 Google 地图网址,从而为销售团队构建丰富的内部潜在客户发掘信息中心。
这些组件可在各个平台上使用,您可以插入 Web、Android 和 iOS 的预构建组件。
这些组件会自动显示丰富的地图注点数据,例如照片、评分和营业时间,而无需您编写前端界面代码或手动处理 API 响应。
数据限制
Places Count 函数在 sample_place_ids 数组中每个地理位置单元格最多返回 250 个 Place ID。如果某个区域的人口密度非常高,则为该特定网格生成的潜在客户名单上限为 250 个。为确保您能捕获高密度市场中的所有潜在客户,请考虑以下策略:
- 使用具体的查询过滤器:不要像上面的示例那样将多种类型归为一组,而是针对每种地点类型分别运行查询。
- 缩小空间范围:使用较小的
geography_radius减小总体搜索面积,或者通过提高 H3 分辨率(最高可达分辨率 11)将该面积划分为更精细的更小分桶。 - 按密度调整分辨率:在分析人口密度各不相同的区域时,请动态调整搜索范围,以免达到 250 个地点 ID 的限制。在商家分布稀疏的农村地区,使用更广的 H3 分辨率(例如 6 或 7)或更大的
geography_radius。 反之,在人口密集的城市地区,请使用非常精细的粒度(例如 10 或 11),以确保您能捕获每个潜在客户,而不会截断名单。
生产查询
验证现有客户是否已成功识别后,您可以恢复为查询的正式版。将最终的 SELECT 块替换为以下 WHERE 子句,以永久过滤掉现有业务:
SELECT
t.h3_cell_index,
t.place_id,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
WHERE e.place_id IS NULL; -- Filters out the CRM matches
架构治理与合规性
为保持高性能和合规的系统,请遵循以下标准:
- 将地点 ID 用作永久性标识符:除了地点 ID 之外,《Google 地图服务条款》禁止存储或缓存从 Places API 返回的各个 POI 数据(例如电话号码和联系方式)。请将地点 ID 用作永久性标识符,以便进行周期性的空白区域分析。
- 通过实时 API 调用确保属性的新鲜度:使用地点 ID 对地点详情 API 进行“及时”调用,以确保销售人员拥有最新的商家和联系信息。或者,如查询输出所示,您可以动态构建 Google 地图网址,以便为销售团队提供指向 Google 地图上商家资料的直接链接。
总结
通过将地点 ID 标准化为主键,您成功弥合了高级市场分析与可行的基层销售运营之间的差距。此架构避开了基于传统人口统计数据的定位所带来的不准确性,利用无服务器数据仓库进行繁重的计算联接,并在 API 层严格遵循成本管理和合规性最佳实践。
后续操作
- 申请访问 地点数据分析 示例数据集。
- 使用 BigQuery Data Exchange 中的商品详情订阅地点数据分析数据集,以访问示例数据或完整的国家/地区数据。
- 查看过滤条件参数参考,根据业务属性和类型微调 BigQuery SQL 查询。
- 在 CRM 或销售线索分配应用中实现动态 Places API 查找,以显示新生成的潜在客户的最新合规联系信息。
贡献者
- Henrik Valve | DevX 工程师