
आम तौर पर, कारोबार से कारोबार के लिए लीड जनरेट करने के लिए, स्टैटिक डायरेक्ट्री या इंडस्ट्री की सूचियां खरीदी जाती हैं. इससे, किसी इलाके में कारोबार की संभावनाओं का पता चलता है. हालांकि, दिलचस्पी की जगहों (पीओआई) के ये स्टैटिक डेटासेट, तुरंत पुराने हो जाते हैं. ऐसा इसलिए होता है, क्योंकि इनमें अक्सर कारोबार के चालू होने की मौजूदा स्थिति या जगह के टाइप की बारीक कैटगरी की जानकारी नहीं होती. इस वजह से, फ़ील्ड सेल्स टीमों का कीमती समय उन कारोबारों के पीछे भागने में बर्बाद हो जाता है जो हमेशा के लिए बंद हो चुके हैं, गलत कैटगरी में शामिल हैं या उनकी आदर्श ग्राहक प्रोफ़ाइल से मेल नहीं खाते.
इस गाइड में, जगह की अहम जानकारी और Places API का इस्तेमाल करके, इस अंतर को कम करने का तरीका बताया गया है. अपने मौजूदा कारोबार को जगह के आईडी से मैप करके, BigQuery का इस्तेमाल किया जा सकता है. इससे, किसी ऐसे इलाके में मौजूद हर कारोबार को अलग किया जा सकता है जो पहले से ही आपके ग्राहक संबंध प्रबंधन (सीआरएम) डेटाबेस में नहीं है. इस गाइड में, बाहर रखने वाले इंजन को बनाने का तरीका बताया गया है. इससे, आपके फ़ील्ड प्रतिनिधियों को टारगेट की गई और पुष्टि की गई लीड की सूची मिल सकेगी.
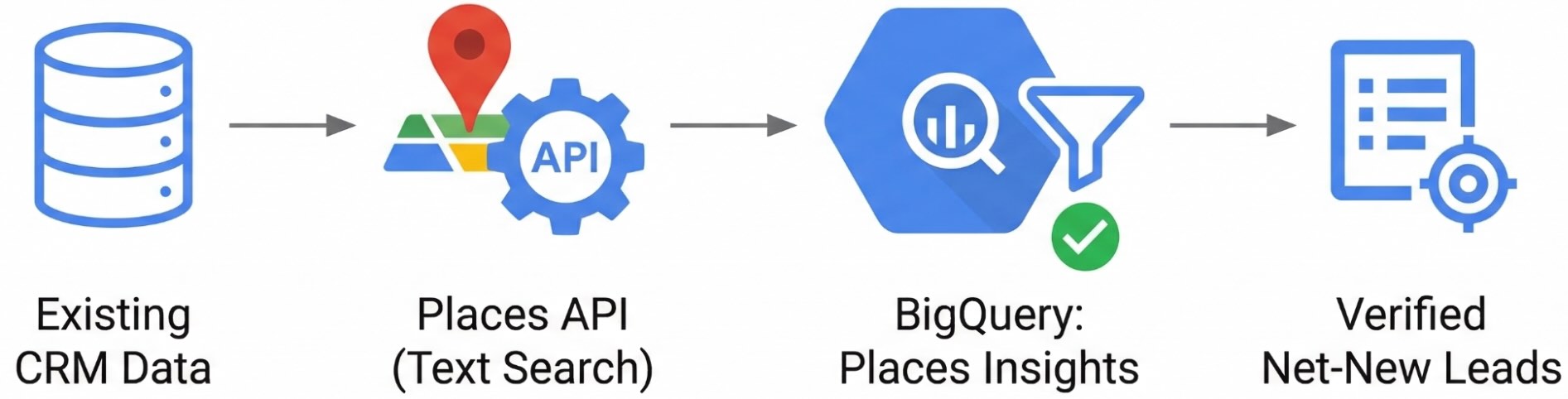
उदाहरण के लिए ऐप्लिकेशन
मान लें कि बिक्री की जगह (पीओएस) की सेवा देने वाली कोई कंपनी, न्यूयॉर्क शहर में फ़ील्ड सेल्स का दायरा बढ़ाना चाहती है. आम तौर पर, संगठन हर ज़िप कोड के हिसाब से, खाने-पीने की कुल दुकानों की रिपोर्ट बनाता है. इस तरीके से, सेल्स प्रतिनिधियों को पुराने डेटा पर भरोसा करने का जोखिम होता है. जैसे, हमेशा के लिए बंद हो चुकी जगहें या काम की नहीं रही लीड. जैसे, बिना स्टोरफ़्रंट वाली प्राइवेट कैटरिंग किचन.
इसके बजाय, Places Insights का इस्तेमाल करके आधुनिक तरीके से काम किया जा सकता है. यह Google Maps के ग्लोबल स्केल और कई स्रोतों से पुष्टि किए गए अप-टू-डेट डेटा का फ़ायदा उठाता है.
जगहों के बारे में अहम जानकारी की सुविधा, जगहों की करीब 500 कैटगरी और 70 से ज़्यादा एट्रिब्यूट के साथ काम करती है. इससे आपको कारोबार के टाइप (जैसे, scandinavian_restaurant), स्टोर के खुले रहने के समय, और दी जाने वाली सेवाओं (जैसे, accepts_credit_cards) के आधार पर, संभावित ग्राहकों को ज़्यादा सटीक तरीके से टारगेट करने में मदद मिलती है. जगहों के बारे में अहम जानकारी की सुविधा को अपने इंटरनल सीआरएम से क्रॉस-रेफ़रंस करके, अपनी सेल्स टीम को ऐसे संभावित ग्राहकों की सूची दी जा सकती है जिनसे अब तक संपर्क नहीं किया गया है और जिनके ग्राहक बनने की संभावना ज़्यादा है.
समस्या हल करने से जुड़ा वर्कफ़्लो
इस गाइड में, डाइनैमिक "लीड मैप" बनाने के लिए तकनीकी फ़्रेमवर्क दिया गया है. यह मैप, आपके मौजूदा कारोबार की जानकारी को अपने-आप फ़िल्टर कर देता है. इससे आपकी सेल्स टीम को सिर्फ़ नई और काम की लीड मिलती हैं.
चार चरणों वाला आर्किटेक्चर
- टारगेट की गई जगहों के टाइप तय करना: अपनी संभावित ग्राहक प्रोफ़ाइलों को जगहों के टाइप से मैप करें.
- ज़्यादा संभावना वाले इलाकों की पहचान करना: BigQuery में Places Count फ़ंक्शन का इस्तेमाल करके, टारगेट किए गए कारोबारों के डेंसिटी हीट मैप जनरेट करें.
- सीआरएम डेटा को प्लेस आईडी में बदलना: डेटा को साफ़ करने वाली पाइपलाइन के ज़रिए, बिना किसी स्ट्रक्चर वाले सीआरएम रिकॉर्ड प्रोसेस करें. इसके लिए, पता की पुष्टि करने वाले एपीआई, जियोकोडिंग एपीआई, और Places API का इस्तेमाल करें. इससे आपको अपने मौजूदा ग्राहकों के प्लेस आईडी मिल जाएंगे.
- व्हाइटस्पेस एक्सक्लूज़न लागू करें: BigQuery में मौजूद जगहों की अहम जानकारी के डेटा के साथ अपने सीआरएम के प्लेस आईडी जोड़ें. इससे मौजूदा ग्राहकों को डाइनैमिक तरीके से फ़िल्टर किया जा सकेगा. साथ ही, नई लीड की सूची तैयार की जा सकेगी.
ज़रूरी शर्तें
शुरू करने से पहले, पक्का करें कि आपके पास ये चीज़ें हों:
Google Cloud प्रोजेक्ट:
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
डेटा ऐक्सेस:
- BigQuery में Places Insights की सदस्यता.
- आपका अपना सीआरएम डेटासेट (जैसे, BigQuery टेबल), जिसमें मौजूदा ग्राहक के कारोबार के नाम और पते शामिल हों. इससे आपको एक्सक्लूज़न लिस्ट बनाने में मदद मिलेगी.
Google Maps Platform:
- एक एपीआई पासकोड.
- आपकी कुंजी के लिए ये एपीआई चालू किए गए हैं:
IAM अनुमतियां:
- पक्का करें कि आपके उपयोगकर्ता या सेवा खाते के पास क्वेरी चलाने और अपने डेटासेट को मैनेज करने के लिए, ये आईएम रोल हों:
भूमिका आईडी BigQuery डेटा एडिटर roles/bigquery.dataEditorBigQuery यूज़र roles/bigquery.user
- पक्का करें कि आपके उपयोगकर्ता या सेवा खाते के पास क्वेरी चलाने और अपने डेटासेट को मैनेज करने के लिए, ये आईएम रोल हों:
लागत के बारे में जानकारी:
- इस ट्यूटोरियल में, बिल किए जाने वाले Google Cloud कॉम्पोनेंट का इस्तेमाल किया गया है. इनसे जुड़े संभावित खर्चों के बारे में जानें:
- BigQuery: क्वेरी को प्रोसेस करने के दौरान इस्तेमाल किए गए कंप्यूट स्लॉट या प्रोसेस किए गए डेटा के लिए शुल्क लिया जाता है.
- Places Insights: क्वेरी के इस्तेमाल के आधार पर शुल्क लिया जाता है.
- Google Maps Platform: Address Validation API, Geocoding API, और Text Search API के लिए, हर अनुरोध पर शुल्क लिया जाता है.
- इस ट्यूटोरियल में, बिल किए जाने वाले Google Cloud कॉम्पोनेंट का इस्तेमाल किया गया है. इनसे जुड़े संभावित खर्चों के बारे में जानें:
पहला चरण: टारगेट किए जाने वाले जगहों के टाइप तय करना
जगह की अहम जानकारी देने वाली सुविधा, जगह की करीब 500 कैटगरी और 70 से ज़्यादा एट्रिब्यूट के बारे में जानकारी देती है. जैसे, स्टोर के खुले होने का समय, पेमेंट के तरीके, और कारोबार की स्थिति. पूरे डेटासेट से बिना सोचे-समझे क्वेरी करने से, समय और पैसे की बर्बादी होती है.
सबसे पहले, Gemini जैसे एलएलएम का इस्तेमाल करके, अपनी इंटरनल कस्टमर प्रोफ़ाइलों को जगह के टाइप में बदलें. इनका इस्तेमाल, Places Insights के लिए क्वेरी बनाते समय किया जाता है. मैक्रो-लेवल की टैक्सोनॉमी की इस परिभाषा से यह पक्का होता है कि आपकी आने वाली BigQuery खोजें, ज़्यादा टारगेट की गई हैं. इससे कंप्यूट प्रोसेसिंग का ओवरहेड कम हो जाता है.
उदाहरण के लिए, अगर आपको पॉइंट ऑफ़ सेल सिस्टम के लिए कोई वर्कफ़्लो डिज़ाइन करना है, तो Gemini को जगह के टाइप की सूची दी जा सकती है. इसके लिए, यह प्रॉम्प्ट इस्तेमाल करें:
"मान लो कि तुम एक मार्केट ऐनलिस्ट हो. Google Maps पर कारोबार की जगहों की जानकारी के लिए उपलब्ध टाइप में से, पॉइंट ऑफ़ सेल सिस्टम उपलब्ध कराने वाली कंपनी के मुख्य टारगेट कौनसे हैं? यह भी बताएं कि आपको ऐसा क्यों लगता है."
इस प्रॉम्प्ट के आधार पर, Gemini टैक्सोनॉमी का विश्लेषण करेगा और जगह के टाइप का टारगेट किया गया सबसेट दिखाएगा. इसका इस्तेमाल BigQuery types फ़िल्टर में किया जा सकता है:
| मुख्य कैटगरी | वजह | मुख्य जगहों के टाइप |
|---|---|---|
| खाने-पीने की चीज़ें | इसमें लेन-देन को तेज़ी से प्रोसेस करना, टेबल मैनेज करना, ऑर्डर के टिकट बनाना, और टिप मैनेज करना ज़रूरी होता है. | restaurant, bar, cafe, coffee_shop |
| शॉपिंग | इन्हें इन्वेंट्री को बेहतर तरीके से ट्रैक करने, बारकोड स्कैन करने, सामान लौटाने की प्रोसेस को मैनेज करने, और लॉयल्टी प्रोग्राम को इंटिग्रेट करने की ज़रूरत होती है. | clothing_store, grocery_store, supermarket, convenience_store |
| सेवाएं और स्वास्थ्य एवं फ़िटनेस | इसमें अपॉइंटमेंट बुक करने, शेड्यूल करने, ग्राहक की प्रोफ़ाइल बनाने, और कमीशन ट्रैक करने की सुविधा इंटिग्रेट की गई हो. | hair_salon, beauty_salon, spa, massage |
| मनोरंजन, खेल-कूद, और अन्य गतिविधियां | इसमें ग्राहकों की भीड़ को तुरंत मैनेज करना, डिजिटल टिकट स्कैन करना, और रियायती टिकटों की बिक्री को तेज़ी से पूरा करना शामिल है. | movie_theater, amusement_park, bowling_alley, stadium |
इस गाइड के लिए, हम खाने-पीने की कैटगरी के लिए सुझाए गए जगह के टाइप पर फ़ोकस करेंगे.
दूसरा चरण: कारोबारों की संख्या निकालकर, ज़्यादा संभावना वाले इलाकों की पहचान करना
मौके वाले क्षेत्रों का पता लगाने के लिए, आपको सबसे पहले कारोबार की डेंसिटी का मैक्रो-व्यू देखना होगा. इसके लिए, BigQuery में जगहों की संख्या बताने वाले फ़ंक्शन (जैसे कि PLACES_COUNT_PER_H3 या PLACES_COUNT_PER_GEO) इस्तेमाल करें.
डेटासेट को सीधे तौर पर क्वेरी किया जा सकता है. हालांकि, जगहों की संख्या बताने वाले फ़ंक्शन पहले से तय होते हैं. ये ऑप्टिमाइज़ की गई एसक्यूएल क्वेरी होती हैं. इनमें कम से कम पांच जगहों के स्टैंडर्ड एग्रीगेशन थ्रेशोल्ड को लागू नहीं किया जाता है. स्टैंडर्ड डायरेक्ट क्वेरी में, एक से चार कारोबारों वाली पंक्तियां शामिल नहीं की जाती हैं. हालांकि, इन फ़ंक्शन की मदद से यह देखा जा सकता है कि कोई संभावित ग्राहक कहां मौजूद है. अहम बात यह है कि ये फ़ंक्शन, sample_place_ids कॉलम का इस्तेमाल करके, हर भौगोलिक क्षेत्र के हिसाब से ज़्यादा से ज़्यादा 250 प्लेस आईडी की एक ऐरे दिखाते हैं. इससे आपके इलाके के प्लानर को, आंकड़ों वाला हीट मैप मिलता है. साथ ही, लीड जनरेट करने के लिए ज़रूरी आइडेंटिफ़ायर मिलते हैं.
यहां दी गई क्वेरी में बताया गया है कि सार्वजनिक डेटासेट का इस्तेमाल करके, डाइनैमिक तरीके से जटिल पॉलीगॉन (न्यूयॉर्क शहर की पूरी सीमा) को कैसे वापस पाया जाता है. इसके बाद, उस जगह की जानकारी को Places Count फ़ंक्शन में पास किया जाता है. शहर के अलग-अलग हिस्सों में, ज़्यादा रिज़ॉल्यूशन (8) पर H3 स्पैटियल इंडेक्स का इस्तेमाल करके, मैक्रो-लेवल का डेंसिटी मैप जनरेट किया जा सकता है.
इसके अलावा, सभी कॉलम (SELECT *) चुनने पर, फ़ंक्शन geography कॉलम दिखाता है. यह कॉलम, H3 सेल को दिखाने वाला एक पॉलीगॉन होता है. इससे आपको अपने BigQuery के नतीजों को कारोबार से जुड़ी अहम जानकारी देने वाले टूल (जैसे कि Looker Studio) में तुरंत इंपोर्ट करने की सुविधा मिलती है. इससे भरे हुए मैप विज़ुअलाइज़ेशन बनाए जा सकते हैं, जो मार्केट के हॉटस्पॉट को विज़ुअल तौर पर दिखाते हैं.
-- Illustrative logic: Extracting target business counts per H3 cell across New York City
DECLARE geo GEOGRAPHY;
-- Get the geography for New York City using the Overture Maps public dataset
SET geo = (SELECT geometry FROM `bigquery-public-data.overture_maps.division_area`
WHERE country = 'US' AND subtype = 'locality' AND names.primary = 'New York' LIMIT 1);
SELECT *
FROM `YOUR_PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', geo,
'h3_resolution', 8,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
)
ORDER BY count DESC;
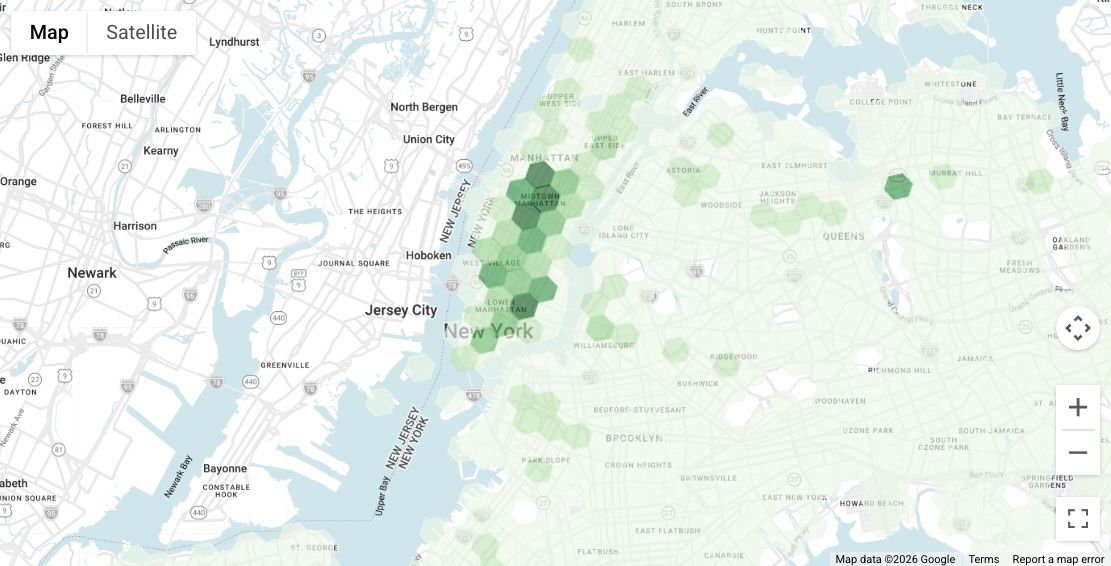
नतीजे के तौर पर मिले विज़ुअलाइज़ेशन में दिखाया गया है कि मैनहैटन में टारगेट किए गए कारोबारों की संख्या ज़्यादा है. इस दस्तावेज़ के बाकी हिस्से में, हम ज़ूम इन करेंगे और लीड जनरेट करने की कोशिशों को इन ज़्यादा संभावना वाले ज़ोन में से किसी एक पर फ़ोकस करेंगे: यूनियन स्क्वेयर के आस-पास का इलाका.
तीसरा चरण: अपने सीआरएम डेटा को जगह के आईडी के हिसाब से सामान्य बनाना
एक्सक्लूज़न विश्लेषण करने के लिए, आपको सबसे पहले अपने सीआरएम रिकॉर्ड को जगह के आईडी में बदलना होगा. सीआरएम डेटा अक्सर अनस्ट्रक्चर्ड होता है. इसलिए, सर्च एपीआई में रॉ टेक्स्ट पास करने से, मैच रेट कम मिलते हैं. पते साफ़ करने, क्षेत्र के हिसाब से एपीआई कवरेज का हिसाब लगाने, और यह पक्का करने के लिए कि आपने BigQuery के लिए सही Establishment Place ID निकाले हैं, इस दो चरणों वाली पाइपलाइन का इस्तेमाल करें.
मान लें कि आपके सीआरएम में, न्यूयॉर्क शहर में रहने वाले रेस्टोरेंट के ये पांच ग्राहक हैं:
| स्थान नाम | पता |
|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States |
| ग्रामर्सी टैवर्न | 42 E 20th St, New York, NY 10003, United States |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States |
| यूनियन स्क्वेयर कैफ़े | 101 E 19th St, New York, NY 10003, United States |
इन रिकॉर्ड में बिना किसी स्ट्रक्चर वाला टेक्स्ट होता है. इसलिए, इन्हें सीधे तौर पर BigQuery में मौजूद जगहों की अहम जानकारी के डेटा से नहीं जोड़ा जा सकता. इसके बजाय, हर लाइन को इस पाइपलाइन से प्रोसेस करें, ताकि टेक्स्ट को स्टैंडर्ड बनाया जा सके और प्लेस आईडी निकाला जा सके.
तीसरा चरण: पते को साफ़ करना और सीधे तौर पर मैच करना
सबसे पहले, अपने पते के डेटा को स्टैंडर्ड फ़ॉर्मैट में बदलें. टारगेट किए गए देश के हिसाब से एपीआई चुनें:
पहला विकल्प: Address Validation API
इन देशों/इलाकों में, सीआरएम में मौजूद कारोबार का नाम और पता, एपीआई में एक साथ पास करें. जवाब के result.geocode.placeTypes ऐरे की जांच करें:
- कारोबार से जुड़ी जानकारी का मिलान: अगर इसमें
establishmentयाpoint_of_interestशामिल है, तो एपीआई ने कारोबार की जानकारी का मिलान कर लिया है. अपने डेटासेट में यहplaceIdजोड़ें और अगले सीआरएम रिकॉर्ड पर जाएं. इस एंट्री के लिए, किसी अन्य एपीआई कॉल की ज़रूरत नहीं है. - कारोबार के टाइप से मेल न खाना: अगर इसमें कारोबार के टाइप शामिल नहीं हैं, तो API कारोबार की पुष्टि नहीं कर सका. जवाब में मिला Place ID, किसी भौगोलिक जगह (जैसे कि कोई बिल्डिंग, सड़क या शहर) को दिखाता है. BigQuery के लिए इस जगह के आईडी का इस्तेमाल न करें, क्योंकि इससे एक्सक्लूज़न जॉइन नहीं हो पाएंगे. इसके बजाय,
result.address.formattedAddressसेव करें और तीसरे चरण पर जाएं.
दूसरा विकल्प: Geocoding API
जिन देशों/इलाकों में पते की पुष्टि करने की सुविधा उपलब्ध नहीं है वहां सिर्फ़ सीआरएम पते को जियोकोडिंग एपीआई में पास करें. कारोबार का नाम शामिल न करें, क्योंकि Geocoding API से अनुमान के मुताबिक नतीजे मिल सकते हैं. नतीजे के तौर पर मिले formattedAddress को एक्सट्रैक्ट करें और तीसरे चरण पर जाएं.
ऐडवांस आर्किटेक्चर: एलएलएम की मदद से अनस्ट्रक्चर्ड डेटा को मैनेज करना
अगर आपके सीआरएम का डेटा बहुत खराब है, जैसे कि कारोबार के नाम और पते, एक ही फ़्री-टेक्स्ट नोट फ़ील्ड में मिक्स किए गए हैं, तो Gemini जैसे एलएलएम का इस्तेमाल करके, रिकॉर्ड को पहले से प्रोसेस करें. Gemini को यह निर्देश दिया जा सकता है कि वह जगह की जानकारी से कारोबार का नाम साफ़ तौर पर पार्स करे. इसके बाद, उसे इस पाइपलाइन में शामिल करे.
तीसरे चरण का दूसरा हिस्सा: कारोबार की कानूनी इकाई की समस्या हल करना
अगर तीसरे चरण (क) में सिर्फ़ साफ़ किया गया पता मिलता है, तो उसे सीआरएम में मौजूद कारोबार के मूल नाम के साथ जोड़ें. इसके बाद, इसे Text Search API को भेजें. पते को स्टैंडर्ड फ़ॉर्मैट में बदलने से, मैच रेट में काफ़ी सुधार होता है.
परफ़ॉर्मेंस और लागत को ऑप्टिमाइज़ करने के लिए, फ़ील्ड मास्क (X-Goog-FieldMask:
places.id) का इस्तेमाल करें. साथ ही, "pageSize": 1 को सेट करें, ताकि सिर्फ़ सबसे मिलते-जुलते प्लेस आईडी को दिखाया जा सके.
टेक्स्ट खोजने के अनुरोध का उदाहरण:
curl -X POST -d '{
"textQuery" : "Gramercy Tavern 42 E 20th St, New York, NY 10003-1324, USA",
"pageSize": 1
}' \
-H 'Content-Type: application/json' -H 'X-Goog-Api-Key: YOUR_API_KEY' \
-H 'X-Goog-FieldMask: places.id' \
'https://places.googleapis.com/v1/places:searchText'
पाइपलाइन का आउटपुट
इस दो चरणों वाली पाइपलाइन के ज़रिए अपनी सीआरएम रिकॉर्ड प्रोसेस करने के बाद, आपका मुख्य लक्ष्य अपने डेटासेट में एक नया place_id कॉलम जोड़ना होता है. भले ही, आईडी को तीसरे चरण में 3a में निकाला गया हो या तीसरे चरण में 3b में टेक्स्ट खोज का इस्तेमाल करके हल किया गया हो. अब इस टेबल को, BigQuery में ऑप्ट-आउट करने वाले लोगों की सूची के तौर पर अपलोड किया जा सकता है.
| स्थान नाम | पता | जगह का आईडी |
|---|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| ग्रामर्सी टैवर्न | 42 E 20th St, New York, NY 10003, United States | ChIJvSQIgqFZwokRFYQbJdzceSs |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States | ChIJQ7XpyqNZwokRQpVfvGEViWM |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States | ChIJFZh0PABZwokRVzoJu0o-mLY |
| यूनियन स्क्वेयर कैफ़े | 101 E 19th St, New York, NY 10003, United States | ChIJxTHke6JZwokRCLWVd99eDBw |
चौथा चरण: BigQuery में, व्हाइटस्पेस को छोड़कर विश्लेषण करना
अपने मौजूदा ग्राहकों को प्लेस आईडी के साथ मैप करें. इसके बाद, जगहों की संख्या बताने वाले फ़ंक्शन का इस्तेमाल करके, नई लीड खोजें.
इस उदाहरण में, हम यूनियन स्क्वेयर (40.73595, -73.99043) के 850 मीटर के दायरे में मौजूद, चालू हालत में मौजूद टारगेट कारोबार (रेस्टोरेंट, बार, कैफ़े, और कॉफ़ी शॉप) खोजेंगे. सड़क के हिसाब से रूटिंग की ज़्यादा जानकारी पाने के लिए, हम PLACES_COUNT_PER_H3 फ़ंक्शन को रिज़ॉल्यूशन 10 तक बढ़ाएंगे.
फ़ंक्शन, प्लेस आईडी को sample_place_ids कॉलम में एक अरे के तौर पर दिखाता है. इसलिए, हमें अरे को UNNEST करना होगा, ताकि हर संभावित कारोबार को उसकी अपनी लाइन में रखा जा सके. इसके बाद, हम अपने मौजूदा ग्राहक के प्लेस आईडी के साथ LEFT JOIN करते हैं.
यह दिखाने के लिए कि इस उदाहरण में, बाहर रखने की लॉजिक काम कर रहा है, नीचे दी गई क्वेरी में CASE स्टेटमेंट का इस्तेमाल किया गया है. इससे नतीजों को पूरी तरह से फ़िल्टर करने के बजाय, उन्हें फ़्लैग किया जाता है.
यह मौजूदा ग्राहकों को नतीजों की टेबल में सबसे ऊपर भी दिखाता है, ताकि यह पुष्टि की जा सके कि उन्हें मैच कर लिया गया है.
एसक्यूएल क्वेरी
WITH existing_customers AS (
-- 1. Simulate the uploaded CRM table
SELECT * FROM UNNEST([
'ChIJc1Vf7KFZwokR1YL2Rn9oxi8', -- Boucherie Union Square
'ChIJvSQIgqFZwokRFYQbJdzceSs', -- Gramercy Tavern
'ChIJQ7XpyqNZwokRQpVfvGEViWM', -- Barn Joo Union Square
'ChIJFZh0PABZwokRVzoJu0o-mLY', -- LOS TACOS No.1
'ChIJxTHke6JZwokRCLWVd99eDBw' -- Union Square Cafe
]) AS place_id
),
target_area_businesses AS (
-- 2. Query Places Insights for target businesses in the radius
SELECT
h3_cell_index,
place_id
FROM `places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_GEOGPOINT(-73.99043, 40.73595),
'geography_radius', 850,
'h3_resolution', 10,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
),
UNNEST(sample_place_ids) AS place_id
)
-- 3. The "Proof" Output: Flag them instead of filtering them out
SELECT
t.h3_cell_index,
t.place_id,
-- Flag whether the LEFT JOIN found a match in the CRM table
CASE
WHEN e.place_id IS NOT NULL THEN 'Existing Customer (To Be Excluded)'
ELSE 'Net-New Lead'
END AS lead_status,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
ORDER BY
-- Explicitly sort the existing customers to the top (0 comes before 1)
CASE WHEN e.place_id IS NOT NULL THEN 0 ELSE 1 END ASC;
क्वेरी के नतीजे
यहां क्वेरी के आउटपुट का एक हिस्सा दिया गया है. इसमें दिखाया गया है कि मौजूदा ग्राहकों की पहचान कैसे की जाती है और उन्हें एक ही ग्रेन्यूलर H3 सेल में नई लीड से कैसे अलग किया जाता है.
ध्यान दें कि क्वेरी में place_id का इस्तेमाल करके, CONCAT स्टेटमेंट का इस्तेमाल करके क्रॉस-प्लैटफ़ॉर्म Maps यूआरएल बनाया गया है. इससे actionable_maps_url कॉलम अपने-आप जनरेट हो जाता है. साथ ही, आपकी सेल्स टीम को एक ऐसा लिंक मिलता है जिस पर क्लिक करके, Google Maps के मोबाइल ऐप्लिकेशन या ब्राउज़र में कारोबार की सटीक जानकारी तुरंत लोड की जा सकती है.
h3_cell_index |
place_id |
lead_status |
actionable_maps_url |
|---|---|---|---|
| 8a2a100d2767fff | ChIJQ7XpyqNZwokRQpVfvGEViWM | मौजूदा ग्राहक (जिन्हें बाहर रखा जाना है) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJQ7XpyqNZwokRQpVfvGEViWM |
| 8a2a100d20effff | ChIJvSQIgqFZwokRFYQbJdzceSs | मौजूदा ग्राहक (जिन्हें बाहर रखा जाना है) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJvSQIgqFZwokRFYQbJdzceSs |
| 8a2a100d2397fff | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 | मौजूदा ग्राहक (जिन्हें बाहर रखा जाना है) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| 8a2a100d2397fff | ChIJFZh0PABZwokRVzoJu0o-mLY | मौजूदा ग्राहक (जिन्हें बाहर रखा जाना है) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJFZh0PABZwokRVzoJu0o-mLY |
| 8a2a100d23b7fff | ChIJxTHke6JZwokRCLWVd99eDBw | मौजूदा ग्राहक (जिन्हें बाहर रखा जाना है) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJxTHke6JZwokRCLWVd99eDBw |
| 8a2a1072c96ffff | ChIJ6atD-WRZwokRULgcZ4TWin8 | नेट-न्यू लीड | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ6atD-WRZwokRULgcZ4TWin8 |
| 8a2a1072c96ffff | ChIJ09yg-llZwokRKAgp0jg6TCU | नेट-न्यू लीड | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ09yg-llZwokRKAgp0jg6TCU |
जगहों की जानकारी देने वाली यूआई किट की मदद से लीड विज़ुअलाइज़ करना
Maps का रॉ यूआरएल देने के बजाय, place_ids को सीधे Places UI Kit में पास किया जा सकता है. इससे, सेल्स टीम के लिए लीड जनरेट करने वाला बेहतर इंटरनल डैशबोर्ड बनाया जा सकता है.
यह सुविधा सभी प्लैटफ़ॉर्म पर उपलब्ध है. इसमें वेब, Android, और iOS के लिए पहले से बने कॉम्पोनेंट शामिल किए जा सकते हैं.
ये कॉम्पोनेंट, पीओएस की बेहतर जानकारी अपने-आप दिखाते हैं. जैसे, फ़ोटो, रेटिंग, और खुले रहने का समय. इसके लिए, आपको फ़्रंटएंड यूज़र इंटरफ़ेस (यूआई) कोड लिखने या एपीआई रिस्पॉन्स को मैन्युअल तरीके से हैंडल करने की ज़रूरत नहीं होती.
डेटा सीमाएं
जगहों की संख्या बताने वाले फ़ंक्शन, sample_place_ids कलेक्शन में मौजूद हर भौगोलिक सेल के लिए ज़्यादा से ज़्यादा 250 जगह के आईडी दिखाते हैं. अगर कोई इलाका बहुत घना है, तो उस सेल के लिए जनरेट की गई लीड की सूची में ज़्यादा से ज़्यादा 250 लीड शामिल की जाएंगी. ज़्यादा घनत्व वाले इलाकों में सभी लीड कैप्चर करने के लिए, इन रणनीतियों का इस्तेमाल करें:
- क्वेरी के लिए खास फ़िल्टर इस्तेमाल करें: ऊपर दिए गए उदाहरण की तरह, कई टाइप को एक क्वेरी में ग्रुप करने के बजाय, हर जगह के टाइप के लिए अलग-अलग क्वेरी चलाएं.
- स्पेशल स्कोप कम करें: छोटे
geography_radiusका इस्तेमाल करके, खोज के दायरे को कम करें. इसके अलावा, H3 रिज़ॉल्यूशन (रिज़ॉल्यूशन 11 तक) बढ़ाकर, इलाके को छोटे और ज़्यादा सटीक बकेट में बांटें. - डेंसिटी के हिसाब से रिज़ॉल्यूशन में बदलाव करना: अलग-अलग जनसंख्या घनत्व वाले इलाकों का विश्लेषण करते समय, खोज के साइज़ में डाइनैमिक तौर पर बदलाव करें. इससे, 250 प्लेस आईडी की सीमा तक पहुंचने से बचा जा सकेगा. ग्रामीण इलाकों में, जहां कारोबार दूर-दूर तक फैले होते हैं वहां ज़्यादा रिज़ॉल्यूशन (जैसे, 6 या 7) वाले H3 या बड़े
geography_radiusका इस्तेमाल करें. इसके उलट, घनी आबादी वाले शहरी इलाकों में ज़्यादा सटीक रिज़ॉल्यूशन (जैसे, 10 या 11) का इस्तेमाल करें. इससे यह पक्का किया जा सकेगा कि आपकी सूची में कोई भी संभावित लीड न छूटे.
प्रोडक्शन क्वेरी
जब आपको यह पुष्टि हो जाए कि मौजूदा ग्राहकों की पहचान सही तरीके से हो गई है, तब क्वेरी के प्रोडक्शन वर्शन पर वापस जाया जा सकता है. अपने मौजूदा कारोबार की बुक को हमेशा के लिए फ़िल्टर करने के लिए, फ़ाइनल SELECT ब्लॉक को इस WHERE क्लॉज़ से बदलें:
SELECT
t.h3_cell_index,
t.place_id,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
WHERE e.place_id IS NULL; -- Filters out the CRM matches
आर्किटेक्चरल गवर्नेंस और अनुपालन
बेहतर परफ़ॉर्मेंस और नियमों का पालन करने वाले सिस्टम को बनाए रखने के लिए, इन मानकों का पालन करें:
- प्लेस आईडी को परसिस्टेंट आइडेंटिफ़ायर के तौर पर इस्तेमाल करना: Google Maps की सेवा की शर्तों के मुताबिक, प्लेस आईडी के अलावा, Places API से मिले किसी भी पीओआई डेटा को सेव या कैश मेमोरी में सेव नहीं किया जा सकता. जैसे, फ़ोन नंबर और संपर्क जानकारी. बार-बार सफ़ेद जगह का विश्लेषण करने के लिए, प्लेस आईडी को परसिस्टेंट आइडेंटिफ़ायर के तौर पर इस्तेमाल करें.
- रीयल-टाइम एपीआई कॉल की मदद से, एट्रिब्यूट की नई जानकारी पाएं: Place Details API को "जस्ट-इन-टाइम" कॉल करने के लिए, प्लेस आईडी का इस्तेमाल करें. इससे यह पक्का किया जा सकेगा कि आपके सेल्स पर्सन के पास, जगह के हिसाब से कारोबार और संपर्क की सबसे नई जानकारी हो. इसके अलावा, क्वेरी के आउटपुट में दिखाए गए तरीके से, Google Maps के यूआरएल डाइनैमिक तरीके से बनाए जा सकते हैं. इससे, आपकी सेल्स टीम को Google Maps पर मौजूद Business Profile के सीधे लिंक मिल जाते हैं.
नतीजा
आपने प्लेस आईडी को प्राइमरी कुंजी के तौर पर इस्तेमाल करके, मार्केट के बड़े विश्लेषण और बिक्री से जुड़ी कार्रवाई करने लायक जानकारी के बीच के अंतर को कम किया. यह आर्किटेक्चर, आबादी के हिसाब से टारगेटिंग करने के पारंपरिक तरीकों की कमियों को दूर करता है. साथ ही, इसमें ज़्यादा कंप्यूटेशनल जॉइन के लिए सर्वरलेस डेटा वेयरहाउसिंग का इस्तेमाल किया जाता है. इसके अलावा, यह एपीआई लेयर पर लागत को मैनेज करने और नियमों का पालन करने के सबसे सही तरीकों का सख्ती से पालन करता है.
अगली कार्रवाइयां
- Places Insights के सैंपल डेटासेट को ऐक्सेस करने का अनुरोध करें.
- BigQuery डेटा एक्सचेंज की लिस्टिंग का इस्तेमाल करके, Places Insights डेटासेट की सदस्यता लें. इससे आपको देश के सैंपल या पूरे डेटा का ऐक्सेस मिलेगा.
- कारोबार के एट्रिब्यूट और टाइप के आधार पर, BigQuery SQL क्वेरी को बेहतर बनाने के लिए, फ़िल्टर पैरामीटर के रेफ़रंस की समीक्षा करें.
- अपने सीआरएम या सेल्स राउटिंग ऐप्लिकेशन में, Places API की डाइनैमिक लुकअप सुविधा लागू करें. इससे जनरेट हुई नई लीड के लिए, संपर्क जानकारी को अप-टू-डेट और नीति के मुताबिक दिखाया जा सकेगा.
योगदानकर्ता
- हेनरिक वॉल्व | DevX इंजीनियर