
개요
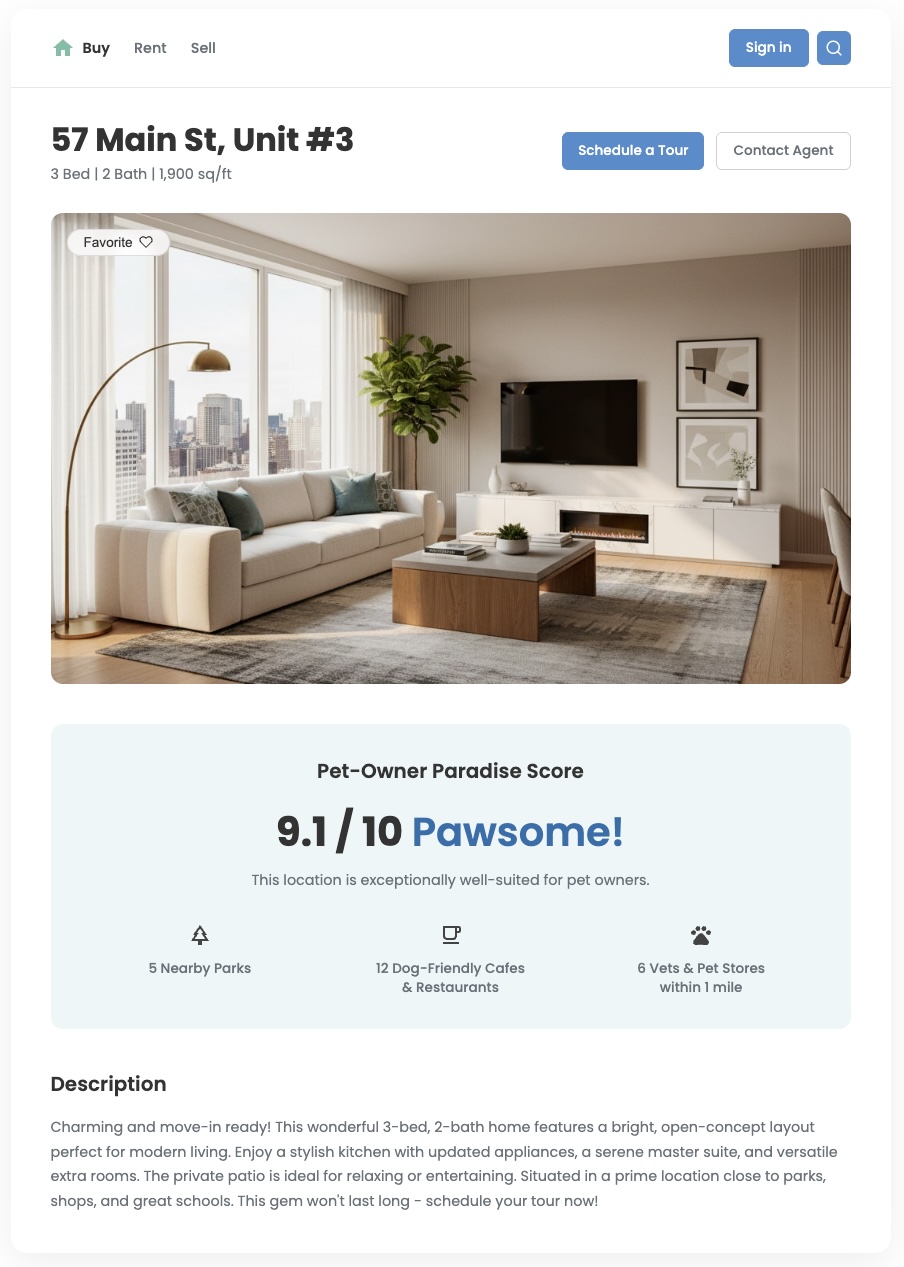
표준 위치 데이터는 주변에 무엇이 있는지 알려주지만, '이 지역이 나에게 얼마나 적합한가?'라는 더 중요한 질문에는 답하지 못하는 경우가 많습니다. 사용자의 요구사항은 미묘합니다. 어린 자녀가 있는 가족은 강아지를 키우는 젊은 전문직 종사자와 비교할 때 우선순위가 다릅니다. 고객이 확신을 가지고 결정을 내릴 수 있도록 이러한 구체적인 요구사항을 반영하는 유용한 정보를 제공해야 합니다. 맞춤 위치 점수는 이러한 가치를 제공하고 차별화된 사용자 환경을 만드는 강력한 도구입니다.
이 문서에서는 BigQuery의 장소 통계 데이터 세트를 사용하여 맞춤 다각적 위치 점수를 만드는 방법을 설명합니다. POI 데이터를 의미 있는 측정항목으로 변환하면 부동산, 소매 또는 여행 애플리케이션을 개선하고 사용자에게 필요한 관련 정보를 제공할 수 있습니다. BigQuery의 생성형 AI를 사용하여 위치 점수를 계산하는 강력한 방법도 제공됩니다.
맞춤 점수로 비즈니스 가치 창출
다음 예에서는 원시 위치 데이터를 강력한 사용자 중심 측정항목으로 변환하여 애플리케이션을 개선하는 방법을 보여줍니다.
- 부동산 개발자는 구매자와 임차인이 자신의 라이프스타일에 맞는 완벽한 동네를 선택할 수 있도록 '가족 친화도 점수' 또는 '통근자에게 이상적인 점수'를 만들어 사용자 참여도를 높이고, 고품질 리드를 확보하고, 전환을 빠르게 유도할 수 있습니다.
- 여행 및 숙박 엔지니어는 '나이트라이프 점수' 또는 '관광객의 천국 점수'를 빌드하여 여행자가 휴가 스타일에 맞는 호텔을 선택하도록 지원하고 예약률과 고객 만족도를 높일 수 있습니다.
- 소매 분석가는 '피트니스 및 웰니스 점수'를 생성하여 주변의 보완적인 비즈니스를 기반으로 새로운 헬스장이나 건강 식품 매장의 최적 위치를 파악하여 적절한 사용자 인구통계를 타겟팅할 가능성을 극대화할 수 있습니다.
이 가이드에서는 BigQuery에서 직접 Places 데이터를 사용하여 모든 종류의 맞춤 위치 점수를 빌드하는 유연한 3부 방법론을 알아봅니다. 가족 친화도 점수와 반려동물 소유자 천국 점수라는 두 가지 별개의 점수를 만들어 이 패턴을 설명하겠습니다. 이 접근 방식을 사용하면 장소 수를 넘어 Places Insights 데이터 세트 내의 풍부하고 상세한 속성을 활용할 수 있습니다. 영업시간, 아동 친화적인 장소인지, 반려동물 동반이 가능한지 등의 정보를 사용하여 사용자를 위한 정교하고 의미 있는 측정항목을 만들 수 있습니다.
솔루션 워크플로
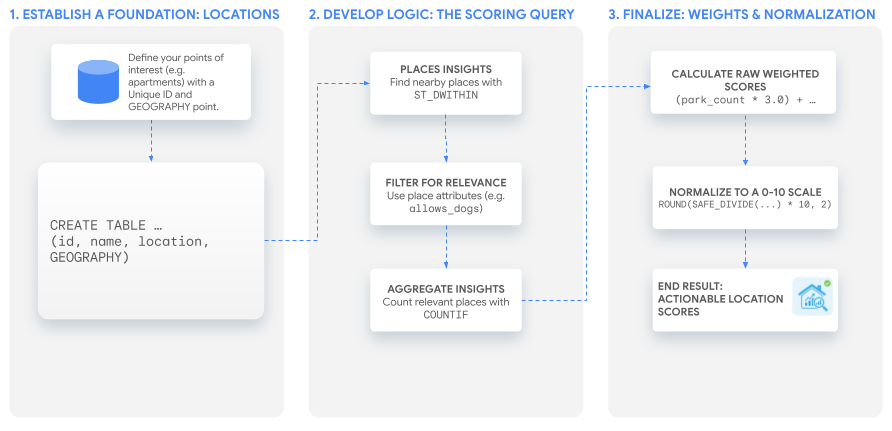
이 튜토리얼에서는 강력한 단일 SQL 쿼리를 사용하여 모든 사용 사례에 맞게 조정할 수 있는 맞춤 점수를 빌드합니다. 가상의 아파트 목록에 대한 두 가지 예시 점수를 빌드하여 이 프로세스를 살펴보겠습니다.
대화형 환경에서 이 워크플로를 살펴보려면 다음 노트북을 실행하세요. BigQuery 내에서 AI.GENERATE 함수를 사용하여 위치 점수를 만드는 방법을 보여줍니다.
 GitHub에서 소스 보기
GitHub에서 소스 보기
기본 요건
시작하기 전에 이 안내에 따라 장소 통계를 설정하세요.
1. 기반 구축: 관심 있는 위치
점수를 만들려면 분석할 위치 목록이 필요합니다. 첫 번째 단계는 이 데이터가 BigQuery에 테이블로 존재하는지 확인하는 것입니다.
각 위치에 고유 식별자가 있고 좌표를 저장하는 GEOGRAPHY 열이 있어야 합니다.
다음과 같은 쿼리를 사용하여 점수를 매길 위치 테이블을 만들고 채울 수 있습니다.
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
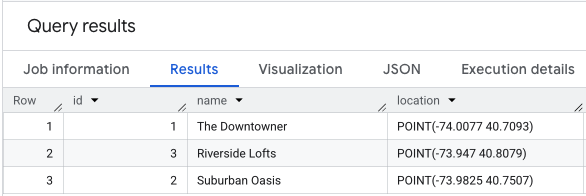
위치 데이터에 SELECT *를 실행하면 다음과 같이 표시됩니다.
2. 핵심 로직 개발: 점수 매기기 쿼리
위치를 설정했으므로 다음 단계는 맞춤 점수와 관련된 주변 장소를 찾고, 필터링하고, 수를 세는 것입니다. 이 모든 작업은 단일 SELECT 문 내에서 실행됩니다.
지리 공간 검색으로 주변 정보 찾기
먼저 Places Insights 데이터 세트에서 각 위치로부터 특정 거리 내에 있는 모든 장소를 찾아야 합니다. BigQuery 함수 ST_DWITHIN가 이 경우에 적합합니다. apartment_listings 테이블과 places_insights 테이블 간에 JOIN를 실행하여 반경 800미터 이내의 모든 장소를 찾습니다. LEFT JOIN를 사용하면 근처에 일치하는 장소가 없더라도 모든 원래 위치가 결과에 포함됩니다.
고급 속성으로 관련성 필터링
여기에서 점수의 추상적 개념을 구체적인 데이터 필터로 변환합니다. 두 가지 예시 점수의 경우 기준이 다릅니다.
- '가족 친화성 점수'의 경우 어린이에게 적합한 공원, 박물관, 레스토랑을 중시합니다.
- '반려동물 소유자 천국 점수'의 경우 공원, 동물 병원, 반려동물 전문점, 개를 허용하는 음식점이나 카페가 중요합니다.
쿼리의 WHERE 절에서 이러한 특정 속성을 직접 필터링할 수 있습니다.
각 위치의 통계 집계
마지막으로 각 아파트에 대해 관련 장소를 몇 개 찾았는지 세야 합니다. GROUP BY 절은 결과를 집계하고 COUNTIF 함수는 각 점수에 대한 특정 기준과 일치하는 장소를 계산합니다.
아래 쿼리는 이러한 세 단계를 결합하여 단일 패스에서 두 점수의 원시 개수를 계산합니다.
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
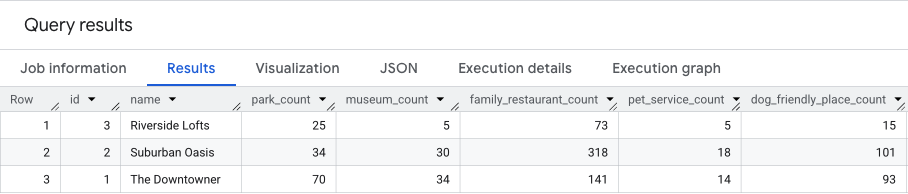
이 쿼리의 결과는 다음과 유사합니다.
다음 섹션에서는 이러한 결과를 기반으로 빌드합니다.
3. 점수 만들기
이제 각 위치의 장소 수와 각 장소 유형의 가중치가 있으므로 맞춤 위치 점수를 생성할 수 있습니다. 이 섹션에서는 BigQuery에서 자체 맞춤 계산을 사용하거나 BigQuery의 생성형 인공지능 (AI) 함수를 사용하는 두 가지 옵션을 설명합니다.
옵션 1: BigQuery에서 자체 맞춤 계산 사용
이전 단계의 원시 개수는 유용하지만, 목표는 사용자 친화적인 단일 점수입니다. 마지막 단계는 가중치를 사용하여 이러한 개수를 결합한 다음 결과를 0~10 스케일로 정규화하는 것입니다.
맞춤 가중치 적용 가중치를 선택하는 것은 예술이자 과학입니다. 비즈니스 우선순위 또는 사용자에게 가장 중요하다고 생각하는 사항을 반영해야 합니다. '가족 친화성' 점수의 경우 공원이 박물관보다 두 배 더 중요하다고 판단할 수 있습니다. 가장 적절한 가정으로 시작하고 Google의 사용자 의견을 기반으로 반복하세요.
점수 정규화 아래 쿼리는 두 개의 공통 테이블 표현식(CTE)을 사용합니다. 첫 번째는 이전과 같이 원시 개수를 계산하고 두 번째는 가중 점수를 계산합니다. 그런 다음 최종 SELECT 문이 가중치 점수에 최소-최대 정규화를 실행합니다. 지도에서 데이터를 시각화할 수 있도록 예시 apartment_listings 표의 location 열이 출력됩니다.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
쿼리 결과는 아래와 유사합니다. 마지막 두 열은 정규화된 점수입니다.

정규화된 점수 이해하기
이 최종 정규화 단계가 왜 그렇게 유용한지 이해하는 것이 중요합니다.
원시 가중치 점수는 위치의 도시 밀도에 따라 0부터 매우 큰 수까지 다양할 수 있습니다. 500 점수는 컨텍스트가 없는 사용자에게는 의미가 없습니다.
정규화는 이러한 추상적인 숫자를 상대적 순위로 변환합니다. 결과를 0~10으로 조정하면 각 위치가 특정 데이터 세트의 다른 위치와 어떻게 비교되는지 명확하게 알 수 있습니다.
- 10점은 원시 점수가 가장 높은 위치에 할당되어 현재 세트에서 가장 좋은 옵션으로 표시됩니다.
- 0점은 원시 점수가 가장 낮은 위치에 할당되어 비교 기준이 됩니다. 이것은 위치에 편의시설이 없다는 의미가 아니라 평가 중인 다른 옵션에 비해 가장 적합하지 않다는 의미입니다.
- 기타 모든 점수는 그 사이에 비례적으로 표시되므로 사용자가 한눈에 옵션을 비교할 수 있습니다.
옵션 2: AI.GENERATE 함수 (Gemini) 사용
고정된 수학 공식을 사용하는 대신 BigQuery AI.GENERATE 함수를 사용하여 SQL 워크플로 내에서 직접 맞춤 위치 점수를 계산할 수 있습니다.
옵션 1은 편의시설 수를 기반으로 한 순수 정량적 점수 매기기에 적합하지만 정성적 데이터를 쉽게 고려할 수는 없습니다. AI.GENERATE 함수를 사용하면 Places Insights 쿼리의 숫자와 아파트 목록의 텍스트 설명 (예: '이 위치는 가족에게 적합하며 밤에는 조용합니다') 또는 특정 사용자 프로필 환경설정 (예: '이 사용자는 가족을 위해 예약하며 중심부에 있는 조용한 지역을 선호합니다')과 같은 구조화되지 않은 데이터를 결합할 수 있습니다. 이를 통해 엄격한 개수에서 놓칠 수 있는 미묘한 차이를 감지하는 더 미묘한 점수를 생성할 수 있습니다. 예를 들어 편의 시설 밀도가 높지만 '아이들에게는 너무 시끄러움'이라고 설명된 위치가 있습니다.
프롬프트 구성
이 함수를 사용하려면 집계 결과 (2단계)가 자연어 프롬프트로 형식이 지정됩니다. 모델에 대한 안내와 데이터 열을 연결하여 SQL에서 동적으로 이 작업을 수행할 수 있습니다.
아래 쿼리에서는 insight_counts이 아파트의 텍스트 설명과 결합되어 각 행의 프롬프트를 만듭니다. 타겟 사용자 프로필도 스코어링을 안내하기 위해 정의됩니다.
SQL로 점수 생성
다음 쿼리는 BigQuery에서 전체 작업을 실행합니다. 담고 있습니다.
- 2단계에 설명된 대로 장소 수를 집계합니다.
- 각 위치에 대한 프롬프트를 구성합니다.
AI.GENERATE함수를 호출하여 Gemini 모델을 사용하여 프롬프트를 분석합니다.- 결과를 애플리케이션에서 사용할 수 있는 구조화된 형식으로 파싱합니다.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
구성 이해
- 비용 인식: 이 함수는 입력을 Gemini 모델에 전달하며 호출될 때마다 Vertex AI에서 요금이 발생합니다. 분석할 위치가 많은 경우 (예: 아파트 목록 수천 개) 먼저 데이터 세트를 가장 관련성 높은 후보로 필터링하는 것이 좋습니다. 비용 최소화에 대한 자세한 내용은 권장사항을 참고하세요.
endpoint: 이 예에서는 속도와 비용 효율성을 우선시하기 위해gemini-flash-latest이 지정됩니다. 하지만 필요에 가장 적합한 모델을 선택할 수 있습니다. Gemini 모델 문서를 참고하여 다양한 버전 (예: 더 복잡한 추론 작업을 위한 Gemini Pro)을 실험하고 사용 사례에 가장 적합한 버전을 찾아보세요.output_schema: 원시 텍스트를 파싱하는 대신 스키마가 적용됩니다(점수의 경우FLOAT64, 이유의 경우STRING). 이렇게 하면 후처리 없이 애플리케이션이나 시각화 도구에서 출력을 즉시 사용할 수 있습니다.
출력 예시
쿼리는 맞춤 점수와 모델의 추론이 포함된 표준 BigQuery 테이블을 반환합니다.
| id | 이름 | family_friendliness_score | 추론 |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | 양적 지표를 충족하는 우수한 편의시설 수 (공원, 레스토랑) 하지만 정성적 데이터에 따르면 주말 소음이 과도하고 야간 활동에 중점을 두어 타겟 사용자의 조용한 환경에 대한 요구사항과 직접적으로 충돌합니다. |
| 2 | Suburban Oasis | 9.8 | 타겟 가족 프로필과 완벽하게 일치하는 설명 ('조용하고 나무가 늘어선 거리')과 함께 뛰어난 정량적 데이터가 제공됩니다. 긍정적 수정자가 많으면 거의 완벽한 점수가 나옵니다. |
이 절차를 사용하면 단일 SQL 쿼리 내에서 이해하기 쉽고 각 개별 사용자에게 맞춤설정된 고도로 개인화된 점수를 제공할 수 있습니다.
4. 지도에서 점수 시각화
BigQuery Studio에는 GEOGRAPHY 열이 포함된 쿼리 결과를 위한 통합 지도 시각화가 포함되어 있습니다. 쿼리에서 location 열을 출력하므로 점수를 즉시 시각화할 수 있습니다.
Visualization 탭을 클릭하면 지도가 표시되고 Data Column 드롭다운을 통해 시각화할 위치 점수를 제어할 수 있습니다. 이 예시에서는 옵션 1 예시에서 normalized_pet_score이 시각화됩니다. 이 예시에서는 apartment_listings 테이블에 위치가 더 추가되었습니다.
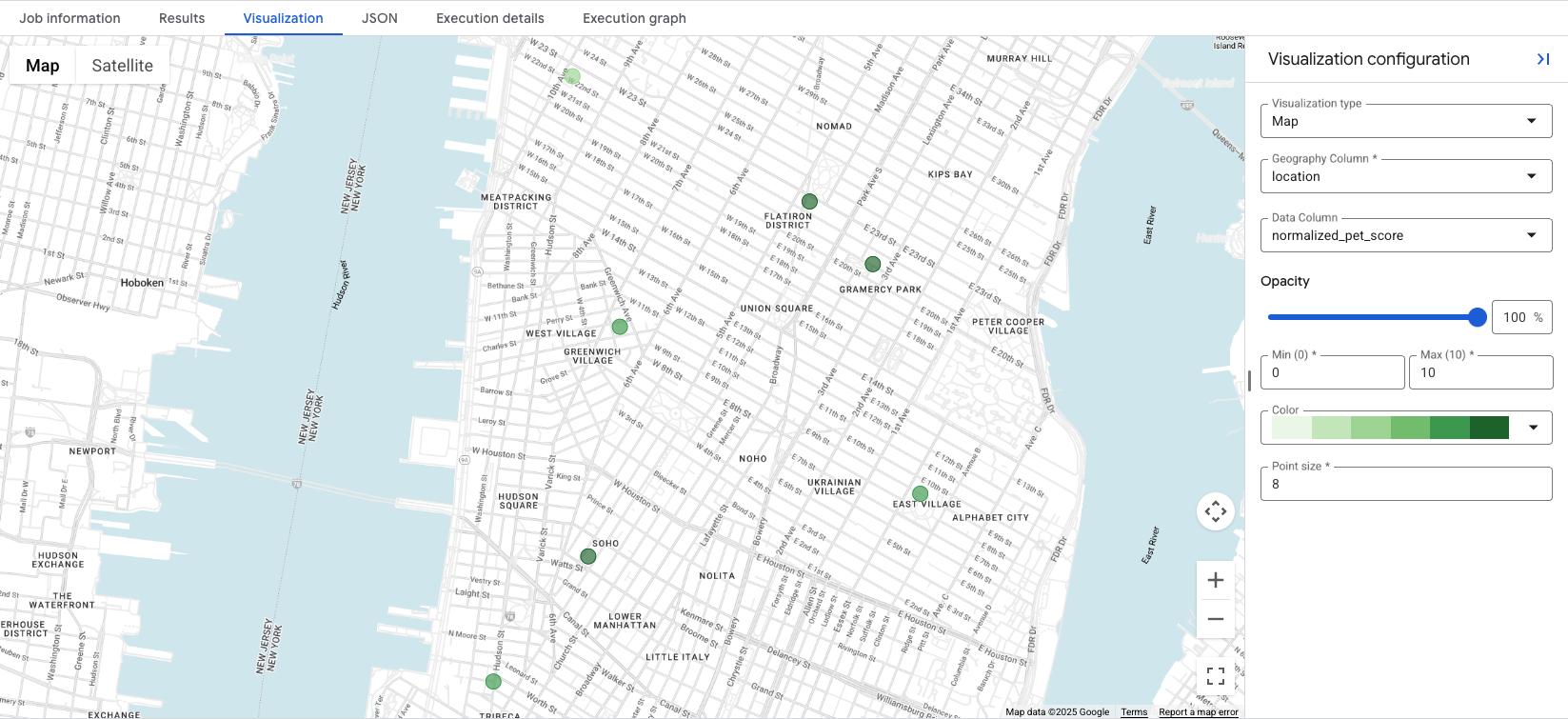
데이터를 시각화하면 생성된 점수에 가장 적합한 위치를 한눈에 확인할 수 있습니다. 이 경우 normalized_pet_score가 높은 위치는 더 어두운 녹색 원으로 표시됩니다. 추가 장소 통계 데이터 시각화 옵션은 쿼리 결과 시각화를 참고하세요.
결론
이제 미묘한 위치 점수를 만들 수 있는 강력하고 반복 가능한 방법론을 갖게 되었습니다. 위치를 시작으로 BigQuery에서 ST_DWITHIN가 있는 주변 장소를 찾고, good_for_children 및 allows_dogs와 같은 고급 속성으로 필터링하고, COUNTIF로 결과를 집계하는 단일 SQL 쿼리를 빌드했습니다. 맞춤 가중치를 적용하고 결과를 정규화하여 실행 가능한 심층적인 통계를 제공하는 단일의 사용자 친화적인 점수를 생성했습니다. 이 패턴을 직접 적용하여 원시 위치 데이터를 상당한 경쟁 우위로 변환할 수 있습니다.
다음 작업
이제 여러분이 빌드할 차례입니다. 이 튜토리얼에서는 템플릿을 제공합니다. Places Insights 스키마에서 제공되는 풍부한 데이터를 사용하여 사용 사례에 가장 필요한 점수를 만들 수 있습니다. 다음과 같은 다른 점수를 고려해 보세요.
- '나이트라이프 점수':
primary_type(bar,night_club),price_level, 심야 영업시간 필터를 결합하여 어두워진 후 가장 활기찬 지역을 찾습니다. - '피트니스 및 웰니스 점수': 근처의
gyms,parks,health_food_stores를 계산하고serves_vegetarian_food가 있는 음식점을 필터링하여 건강을 중시하는 사용자를 위해 위치에 점수를 매깁니다. - '통근자의 꿈 점수': 교통 이용을 중시하는 사용자를 위해 근처에
transit_station및parking장소가 밀집된 위치를 찾습니다.
참여자
헨리크 밸브 | DevX 엔지니어