
Places Insights를 사용하면 Google 지도의 풍부한 장소 데이터에 대한 고급 통계 분석을 수행할 수 있습니다. 수백만 개의 관심 장소 (POI) 데이터 포인트에 대한 집계된 수와 밀도 정보를 제공하여 강력한 지리 공간 인텔리전스를 지원합니다.
주요 기능:
- 지리 공간 인텔리전스: 특정 지리적 영역에서 다양한 카테고리의 관심 장소 (예: 소매, 음식점, 서비스)의 밀도와 분포를 '조감도'로 확인할 수 있습니다.
- 안전한 데이터 액세스: 데이터는 데이터 보호가 적용된 BigQuery 데이터 교환 등록정보를 사용하여 배포되므로 데이터 공유 및 분석을 위한 안전하고 보호된 환경을 지원합니다.
- 실행 가능한 세부정보: Places 통계는 집계된 추세에 중점을 두지만, 출력된 장소 ID를 사용하여 다른 Google Maps Platform API를 통해 세부정보를 드릴다운하고 개별 장소 정보를 가져와 통계적 통찰력에서 세부적인 작업으로 이동할 수 있습니다.
장소 데이터 정보
Google 지도는 전 세계 수백만 개의 시설에 대한 장소 데이터를 관리합니다. Places Insights는 BigQuery에서 이 포괄적인 장소 데이터를 사용할 수 있도록 지원하므로 장소 유형, 평점, 영업시간, 휠체어 접근성 등 다양한 속성을 기반으로 Google 지도 장소 데이터에 관한 집계된 유용한 정보를 도출할 수 있습니다.
Places Insights를 사용하려면 BigQuery에서 장소 데이터에 관한 통계적 인사이트를 반환하는 SQL 쿼리를 작성하세요. 이러한 통계를 통해 다음과 같은 질문에 답할 수 있습니다.
- 잠재적인 신규 매장 위치 근처에 유사한 비즈니스가 몇 개 운영되고 있나요?
- 가장 성공적인 매장 근처에 어떤 종류의 비즈니스가 가장 많이 있나요?
- 타겟 고객을 유치할 수 있는 보완적인 비즈니스가 밀집된 지역은 어디인가요?
- 마드리드에서 오후 8시에 영업하고, 휠체어 이용 가능 주차장이 있으며, 테이크아웃을 제공하는 별 5개 스시 레스토랑은 몇 개야?
- 캘리포니아에서 전기 자동차 충전소가 가장 많이 집중된 우편번호는 무엇인가요?
장소 통계는 다음과 같은 여러 사용 사례를 지원합니다.
- 부지 선정: 새로운 비즈니스 또는 실제 자산 배치에 가장 적합한 위치를 평가하고 선택합니다. 주변 관심 장소의 밀도와 혼합을 분석하면 경쟁 및 보완 비즈니스 환경 내에서 잠재적 사이트가 최적으로 배치되도록 할 수 있습니다. 이러한 데이터 기반 접근 방식을 사용하면 새 위치에 투자할 때 발생하는 위험을 줄일 수 있습니다.
- 위치 실적 평가: 슈퍼마켓이나 이벤트 장소와 같은 특정 유형의 관심 장소와의 근접성과 같은 지리 공간 변수가 기존 위치의 긍정적 또는 부정적 실적과 어떤 상관관계가 있는지 파악합니다. 이 데이터를 사용하면 사용 사례에 가장 적합한 지리 공간적 특성을 공유하는 잠재적 사이트를 식별할 수 있습니다. 이 정보를 사용하여 주변 관심 장소 컨텍스트를 기반으로 새 위치의 미래 실적을 예측하는 예측 모델을 배포할 수도 있습니다.
- 지역 타겟팅 마케팅: 특정 지역에서 성공할 수 있는 마케팅 캠페인 또는 광고 유형을 파악합니다. Places Insights는 상업 활동을 이해하는 데 필요한 컨텍스트를 제공하므로 관련 비즈니스 또는 활동의 집중도에 따라 메시지를 맞춤설정할 수 있습니다.
- 판매 예측: 예상 위치에서 향후 판매를 예측합니다. 주변 지리 공간 특성의 영향을 모델링하면 투자 결정을 내릴 수 있는 강력한 예측 모델을 만들 수 있습니다.
- 시장 조사: 비즈니스 또는 서비스를 다음으로 확장할 지역을 파악합니다. 기존 시장 포화도와 관심 장소 밀도를 분석하여 가장 큰 기회를 제공하는 서비스가 부족하거나 밀도가 높은 타겟 시장을 파악합니다. 이 분석은 전략적 성장 및 확장 이니셔티브를 뒷받침하는 증거를 제공합니다.
Places Insights 데이터 세트를 직접 쿼리하거나 장소 수 함수를 사용할 수 있습니다.
브랜드 데이터 정보
장소 데이터와 함께 Places Insights에는 동일한 브랜드 이름으로 운영되는 여러 위치가 있는 브랜드 또는 매장에 관한 데이터가 포함됩니다.
브랜드를 사용하여 다음과 같은 질문에 답할 수 있습니다.
- 특정 지역의 브랜드별 모든 매장 수는 얼마인가요?
- 이 지역에서 상위 3개 경쟁업체 브랜드의 수는 얼마야?
- 이 지역에서 다음 브랜드를 제외한 모든 커피숍의 수는 얼마인가요?
BigQuery 정보
BigQuery 등록정보에서 데이터를 사용할 수 있도록 하면 Places Insights를 통해 다음 작업을 할 수 있습니다.
- 데이터를 Places Insights 데이터와 안전하게 결합하세요.
- 유연한 SQL 쿼리를 작성하여 특정 비즈니스 요구사항에 대한 집계된 통계를 파악합니다.
- 비공개 데이터 및 워크플로와 함께 이미 사용 중인 BigQuery 도구를 사용합니다.
- BigQuery의 확장성과 성능을 활용하여 대규모 데이터 세트를 손쉽게 분석할 수 있습니다.
사용 사례
이 예에서는 BigQuery에서 내 데이터를 Places Insights 데이터와 조인하여 집계 정보를 도출합니다. 이 예에서는 뉴욕시에 여러 위치를 보유한 호텔 소유자라고 가정합니다. 이제 호텔 위치 데이터를 장소 통계 데이터와 결합하여 호텔 근처에 사전 정의된 비즈니스 유형이 얼마나 집중되어 있는지 파악하려고 합니다.
기본 요건
이 예에서는 미국의 장소 통계 데이터 세트를 구독합니다.
호텔 데이터 세트의 이름은 mydata이며 뉴욕시에 있는 두 호텔의 위치를 정의합니다. 다음 SQL은 이 데이터 세트를 만듭니다.
CREATE OR REPLACE TABLE `mydata.hotels` ( name STRING, location GEOGRAPHY ); INSERT INTO `mydata.hotels` VALUES( 'Hotel 1', ST_GEOGPOINT(-73.9933, 40.75866) ); INSERT INTO `mydata.hotels` VALUES( 'Hotel 2', ST_GEOGPOINT(-73.977713, 40.752124) );
해당 지역의 음식점 수 가져오기
고객에게 호텔 근처에 영업 중인 식당의 밀도를 알려주기 위해 각 호텔에서 1, 000m 이내에 있는 식당 수를 반환하는 SQL 쿼리를 작성합니다.
SELECT WITH AGGREGATION_THRESHOLD h.name, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` AS r, `mydata.hotels` AS h WHERE ST_DWITHIN(h.location, r.point, 1000) AND r.primary_type = 'restaurant' AND business_status = "OPERATIONAL" GROUP BY 1
이 이미지는 이 질문에 대한 출력의 예를 보여줍니다.

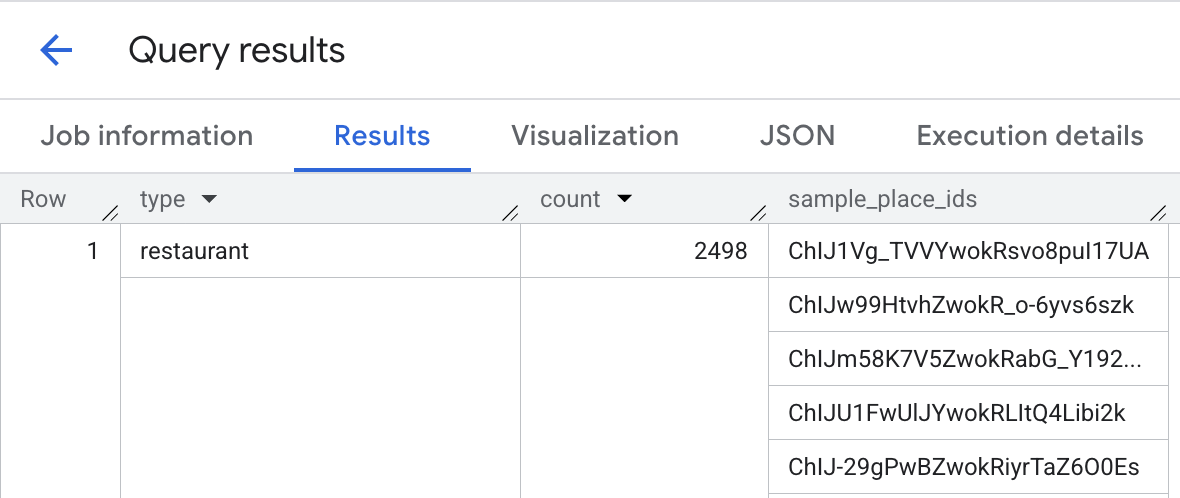
장소 개수 함수를 사용하여 해당 지역의 음식점 개수와 장소 ID를 가져옵니다.
위치 근처의 음식점 수를 찾습니다. 장소 개수 함수를 사용하면 개별 장소에 관한 세부정보를 조회하는 데 사용할 수 있는 장소 ID 목록을 가져올 수 있습니다.
DECLARE geo GEOGRAPHY; SET geo = ST_GEOGPOINT(-73.9933, 40.75866); -- Location of hotel 1 SELECT * FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE`( JSON_OBJECT( 'types', ["restaurant", "cafe", "bar"], 'geography', geo, 'geography_radius', 1000 -- Radius in meters ) );
이 이미지는 이 질문에 대한 출력의 예를 보여줍니다.
해당 지역의 음식점 및 바 개수 가져오기
각 호텔에서 1,000m 이내에 있는 레스토랑과 함께 바를 포함하도록 쿼리를 수정합니다.
SELECT WITH AGGREGATION_THRESHOLD h.name, r.primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` AS r, `mydata.hotels` AS h WHERE ST_DWITHIN(h.location, r.point, 1000) AND r.primary_type IN UNNEST(['restaurant','bar']) AND business_status = "OPERATIONAL" GROUP BY 1, 2
이 이미지는 이 질문에 대한 출력의 예를 보여줍니다.

이 지역의 적당한 가격의 레스토랑과 바의 수를 가져옵니다.
다음으로 바와 레스토랑에서 어떤 고객 인구통계를 타겟팅하는지 알아야 합니다. 호텔이 적당한 가격대를 타겟팅하므로 해당 가격대이고 리뷰가 좋은 인근 시설의 존재만 광고하고 싶습니다.
PRICE_LEVEL_MODERATE 가격대이고 평점이 별 4개 이상인 경우에만 바와 레스토랑을 반환하도록 쿼리를 제한합니다. 이 쿼리는 각 호텔 주변의 반경을 1,500미터로 확장하기도 합니다.
SELECT WITH AGGREGATION_THRESHOLD h.name, r.primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` AS r, `mydata.hotels` AS h WHERE ST_DWITHIN(h.location, r.point, 1500) AND r.primary_type IN UNNEST(['restaurant', 'bar']) AND rating >= 4 AND business_status = "OPERATIONAL" AND price_level = 'PRICE_LEVEL_MODERATE' GROUP BY 1, 2
이 이미지는 이 질문에 대한 출력의 예를 보여줍니다.
