
이 문서에서는 장소 통계의 샘플 장소 ID 데이터를 장소 수 함수와 함께 사용하여 타겟 장소 세부정보 조회를 통해 결과에 대한 신뢰도를 높이는 방법을 알아봅니다.
이 패턴의 자세한 참조 구현은 이 설명 노트북을 참고하세요.
 GitHub 소스 보기
GitHub 소스 보기
건축 패턴
이 건축 패턴은 고급 통계 분석과 실제 검증 간의 격차를 해소하는 반복 가능한 워크플로를 제공합니다. BigQuery의 규모와 Places API의 정확성을 결합하여 분석 결과를 확실하게 검증할 수 있습니다. 이는 데이터에 대한 신뢰가 가장 중요한 사이트 선택, 경쟁업체 분석, 시장 조사에 특히 유용합니다.
이 패턴의 핵심에는 네 가지 주요 단계가 포함됩니다.
- 대규모 분석 실행: BigQuery의 장소 통계에서 장소 수 함수를 사용하여 도시 또는 지역 전체와 같은 넓은 지리적 영역의 장소 데이터를 분석합니다.
- 샘플 격리 및 추출: 집계된 결과에서 관심 영역 (예: 밀도가 높은 '핫스팟')을 식별하고 함수에서 제공하는
sample_place_ids를 추출합니다. - 실제 세부정보 검색: 추출된 장소 ID를 사용하여 장소 세부정보 API를 타겟 호출하여 각 장소의 풍부한 실제 세부정보를 가져옵니다.
- 결합된 시각화 만들기: 초기 고급 통계 지도 위에 세부 장소 데이터를 레이어링하여 집계된 수가 실제 상황을 반영하는지 시각적으로 검증합니다.
솔루션 워크플로
이 워크플로를 사용하면 거시적 추세와 미시적 사실 간의 격차를 해소할 수 있습니다. 광범위한 통계 뷰로 시작하여 구체적인 실제 예시로 데이터를 전략적으로 드릴다운하여 검증합니다.
장소 통계로 대규모 장소 밀도 분석
첫 번째 단계는 환경을 고급 수준에서 파악하는 것입니다. 수천 개의 개별 관심 장소 (POI)를 가져오는 대신 단일 쿼리를 실행하여 통계 요약을 가져올 수 있습니다.
장소 통계 PLACES_COUNT_PER_H3
함수
가 이 작업에 적합합니다. POI 수를 육각형 그리드 시스템
(H3)으로 집계하여 특정 기준 (예: 영업 중이며 평점이 높은 음식점)에 따라 밀도가 높거나 낮은 영역을 빠르게 식별할 수 있습니다.
쿼리 예시는 다음과 같습니다. 검색 영역 지리를 제공해야 합니다. Overture Maps Data BigQuery 공개 데이터 세트와 같은 공개 데이터 세트를 사용하여 지리적 경계 데이터를 검색할 수 있습니다.
자주 사용되는 공개 데이터 세트 경계의 경우 자체 프로젝트의 테이블로 구체화하는 것이 좋습니다. 이렇게 하면 BigQuery 비용이 크게 절감되고 쿼리 성능이 향상됩니다.
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
브랜드 ID로 필터링 및 검증
특정 브랜드의 수와 샘플 장소 ID를 검증하려면 brand_ids 필터를 사용하여 브랜드 ID 목록을 제공합니다.
타겟 브랜드의 브랜드 ID를 가져오려면 BigQuery에서 brands 테이블을 쿼리합니다.
SELECT id, name
FROM `YOUR_PROJECT.places_insights___us.brands`
WHERE LOWER(name) LIKE "%starbucks%";
타겟 브랜드 ID (예: "1413758728321880760"
스타벅스의 경우)를 가져온 후 brand_ids 필터 배열 내에 전달합니다.
SELECT *
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'brand_ids', ["1413758728321880760"]
)
);
3단계인 실제 검증 중에 장소가 일반 카테고리와 일치하는지 확인하는 대신 정규 표현식 일치를 사용하여 장소 세부정보 API에서 반환된 표시 이름을 예상 브랜드 이름과 프로그래매틱 방식으로 비교할 수 있습니다. 예를 들어 response.display_name.text 필드를 비교할 수 있습니다.
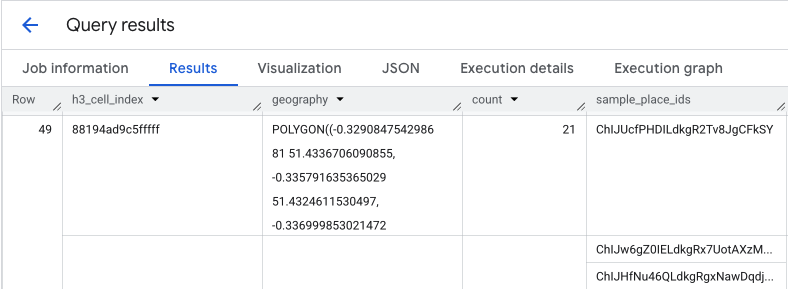
이 쿼리의 출력은 H3 셀 테이블과 각 셀 내의 장소 수를 제공하여 밀도 히트맵의 기반을 형성합니다.
핫스팟 격리 및 샘플 장소 ID 추출
PLACES_COUNT_PER_H3 함수의 결과는 응답의 요소당 최대 250개의 장소 ID인 sample_place_ids 배열도 반환합니다. 이러한 ID는 집계된 통계에서 통계에 기여하는 개별 장소로 연결되는 링크입니다.
시스템은 먼저 초기 쿼리에서 가장 관련성이 높은 셀을 식별할 수 있습니다.
예를 들어 수가 가장 많은 상위 20개 셀을 선택할 수 있습니다. 그런 다음 이러한 핫스팟에서 sample_place_ids를 단일 목록으로 통합합니다.
이 목록은 가장 관련성이 높은 영역에서 가장 흥미로운 POI의 선별된 샘플을 나타내므로 타겟 검증을 준비할 수 있습니다.
pandas DataFrame을 사용하여 Python에서 BigQuery 결과를 처리하는 경우 이러한 ID를 추출하는 논리는 간단합니다.
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
다른 프로그래밍 언어를 사용하는 경우에도 유사한 논리를 적용할 수 있습니다.
Places API로 실제 세부정보 검색
통합된 장소 ID 목록을 사용하여 이제 대규모 분석에서 특정 데이터 검색으로 전환합니다. 이러한 ID를 사용하여 장소 세부정보 API를 쿼리하여 각 샘플 위치에 대한 세부정보를 가져옵니다.
이는 중요한 검증 단계입니다. 장소 통계는 특정 지역에 있는 음식점의 수 를 알려주지만 Places API는 음식점의 이름, 정확한 주소, 위도/경도, 사용자 평점, Google 지도에서 음식점 위치로 연결되는 직접 링크까지 제공하여 어떤 음식점인지 알려줍니다. 이렇게 하면 샘플 데이터가 풍부해지고 추상 ID가 구체적이고 검증 가능한 장소로 바뀝니다.
장소 세부정보 API에서 사용할 수 있는 데이터의 전체 목록과 검색과 관련된 비용은 API 문서를 검토하세요.
Python 클라이언트 라이브러리를 사용하여 특정 ID에 대한 Places API 요청은 다음과 같습니다. 자세한 내용은 Places API (신규) 클라이언트 라이브러리 예시 를 참고하세요.
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
이 요청의 필드는 두 개의 서로 다른 결제 SKU에서 데이터를 가져옵니다.
formattedAddress및location은 장소 세부정보 Essentials SKU의 일부입니다.displayName및googleMapsUri는 장소 세부정보 Pro SKU의 일부입니다.
단일 장소 세부정보 요청에 여러 SKU의 필드가 포함된 경우 전체 요청은 최상위 SKU의 요율로 청구됩니다. 따라서 이 특정 호출은 장소 세부정보 Pro 요청으로 청구됩니다.
비용을 관리하려면 항상 FieldMask를 사용하여 애플리케이션에 필요한 필드만 요청하세요.
검증을 위한 결합된 시각화 만들기
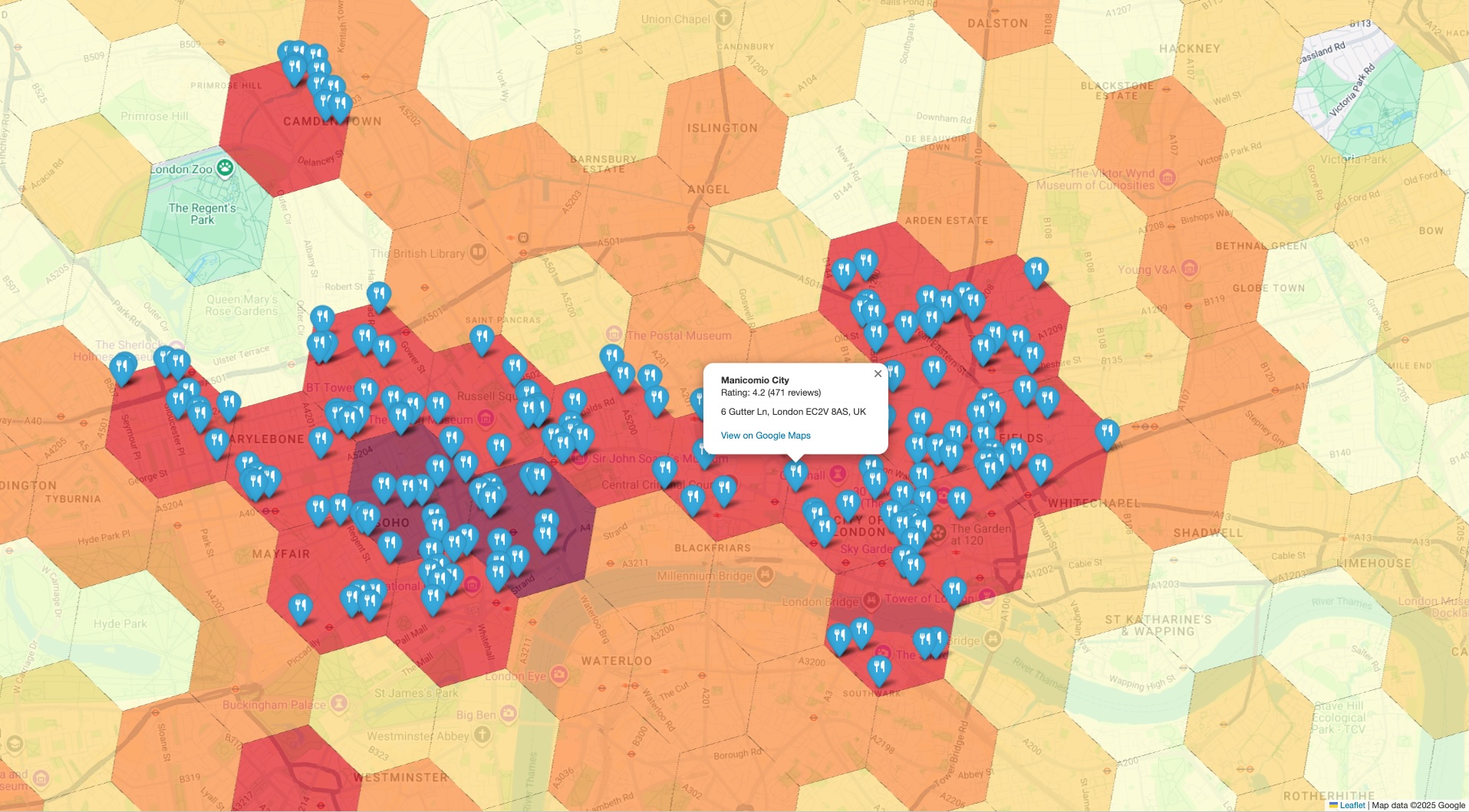
마지막 단계는 두 데이터 세트를 단일 뷰로 통합하는 것입니다. 이렇게 하면 초기 분석을 즉각적이고 직관적으로 스팟 체크할 수 있습니다. 시각화에는 두 개의 레이어가 있어야 합니다.
- 기본 레이어: 초기
PLACES_COUNT_PER_H3결과에서 생성된 등치선도 또는 히트맵으로, 지리적 영역 전체의 장소 밀도를 보여줍니다. - 상위 레이어: 각 샘플 POI의 개별 마커 세트로, 이전 단계에서 Places API에서 가져온 정확한 좌표를 사용하여 표시됩니다.
이 결합된 뷰를 빌드하는 논리는 이 의사코드 예시에 표현되어 있습니다.
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
고급 밀도 지도에 구체적인 실제 마커를 오버레이하면 핫스팟으로 식별된 영역에 실제로 분석 중인 장소가 많이 포함되어 있는지 즉시 확인할 수 있습니다. 이러한 시각적 확인은 데이터 기반 결론에 대한 상당한 신뢰를 구축합니다.
결론
이 건축 패턴은 대규모 지리정보 통계를 검증하는 강력하고 효율적인 방법을 제공합니다. 광범위하고 확장 가능한 분석을 위해 장소 통계를 활용하고 타겟 실제 검증을 위해 장소 세부정보 API를 활용하여 강력한 의견 루프를 만듭니다. 이렇게 하면 소매점 사이트 선택 또는 물류 계획과 같은 전략적 결정이 통계적으로 유의미할 뿐만 아니라 검증 가능한 정확한 데이터를 기반으로 이루어집니다.
다음 단계
- 다른 장소 수 함수 를 살펴보고 다양한 분석 질문에 어떻게 답변할 수 있는지 알아보세요.
- Places API 문서 를 검토하여 분석을 더욱 풍부하게 하기 위해 요청할 수 있는 다른 필드를 알아보세요.
참여자
헨리크 밸브 | DevX 엔지니어