

为什么一个网站的业绩蒸蒸日上,而另一个网站的业绩却不尽如人意,尽管这两个网站的人员配备、库存和运营实践都保持一致?拥有多个营业地点的商家往往难以解释其投资组合中存在的这种效果差异。答案通常隐藏在外部环境中。通过利用地图注点 (POI) 数据,我们可以摆脱道听途说的解释,准确量化本地竞争密度和社区特征如何决定站点的成功。
本指南演示了如何使用 地点数据分析 和 BigQuery ML 来量化本地周边环境对网站成功的影响。您将结合使用自有网站性能数据与外部地理空间信号来诊断性能驱动因素。
我们将使用伦敦的网站数据集构建一个线性回归模型。此工作流利用 H3 空间索引,该系统将城市划分为均匀的六边形单元格。通过将环境数据汇总到这些单元格中,您可以训练模型来预测城市中任何社区(而不仅仅是现有地点)的潜在表现。
您将学会:
- 工程师功能:汇总您网站 500 米半径范围内的健身房、学校和公交站等地图注点 (POI) 的数量。
- 训练模型:使用 BigQuery ML 构建一个回归模型,将这些环境特征与您的内部效果指标相关联。
- 为城市评分:将训练好的模型应用于伦敦的整个 H3 网格,以确定未来扩张的高潜力热点。
如果您是 BigQuery ML 的新手,请参阅 BigQuery ML 简介,了解核心概念和支持的模型类型。
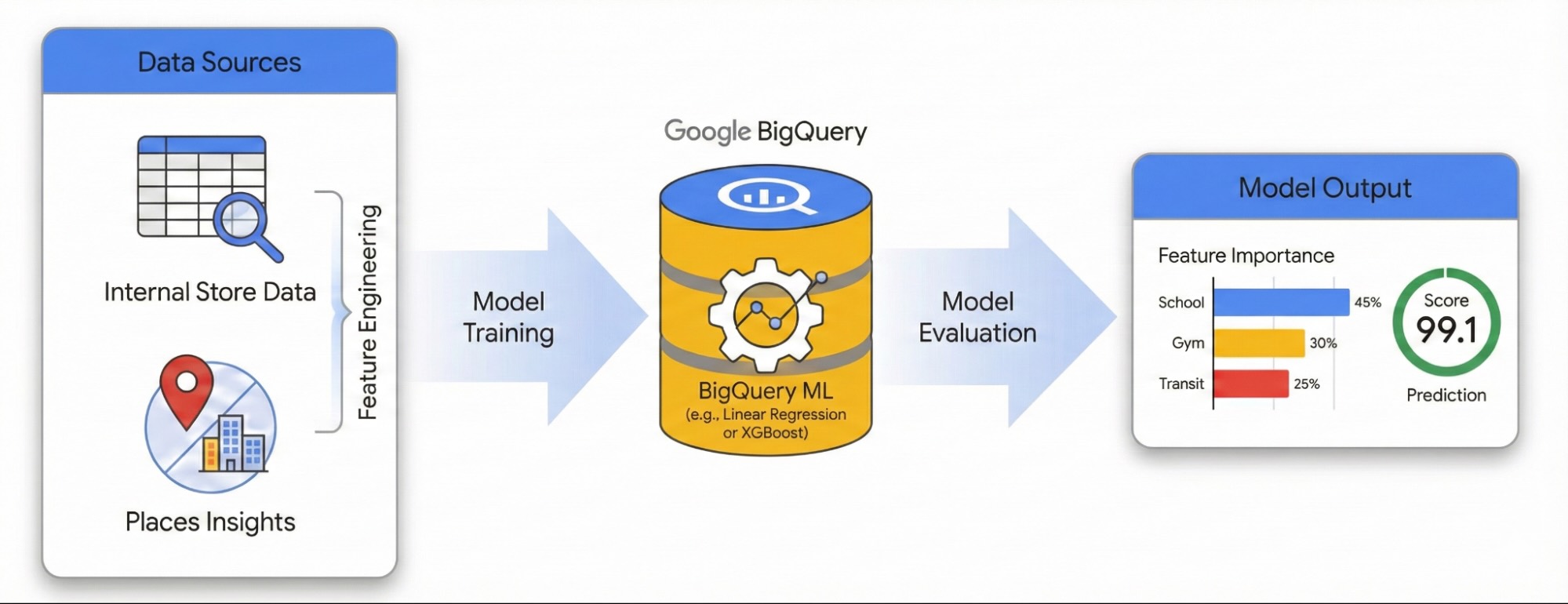
如需在交互式环境中探索此工作流,请运行以下笔记本。该笔记本展示了如何使用 BigQuery ML 构建预测模型,以及如何使用 H3 空间索引直观呈现城市级机遇。
 在 GitHub 上查看源代码
在 GitHub 上查看源代码
前提条件
在开始之前,请确保您满足以下条件:
Google Cloud 项目:
- 启用了结算功能的 Google Cloud 项目。
数据访问权限:
Google Maps Platform:
- API 密钥。
- 您的密钥已启用以下 API:
Python 环境和库:
- Python 环境,例如 Google Cloud 控制台中的 Colab Enterprise。
- 已安装以下库:
媒体库 说明 pandas-gbq与 BigQuery 交互。 geopandas处理地理空间数据操作。 folium创建互动式地图。 shapely几何图形操作。
IAM 权限:
- 确保您的用户账号或服务账号具有以下 IAM 角色:
角色 ID BigQuery Data Editor roles/bigquery.dataEditorBigQuery User roles/bigquery.user
- 确保您的用户账号或服务账号具有以下 IAM 角色:
费用意识:
- 本教程使用 Google Cloud 的收费组件。请注意与以下方面相关的潜在费用:
- BigQuery ML:按使用的计算槽收费。请参阅 BigQuery ML 价格。
- 地点数据分析:根据查询使用情况收费。
- 本教程使用 Google Cloud 的收费组件。请注意与以下方面相关的潜在费用:
利用地点数据分析进行特征工程
为了隔离影响网站性能的外部因素,您必须将原始 POI 数据转换为可量化的特征。您将计算每个地点 500 米半径范围内的特定便利设施或场所类型(例如健身房、学校和公交站)的密度。您选择的设施将取决于您认为哪些设施可能与您的业务最相关。
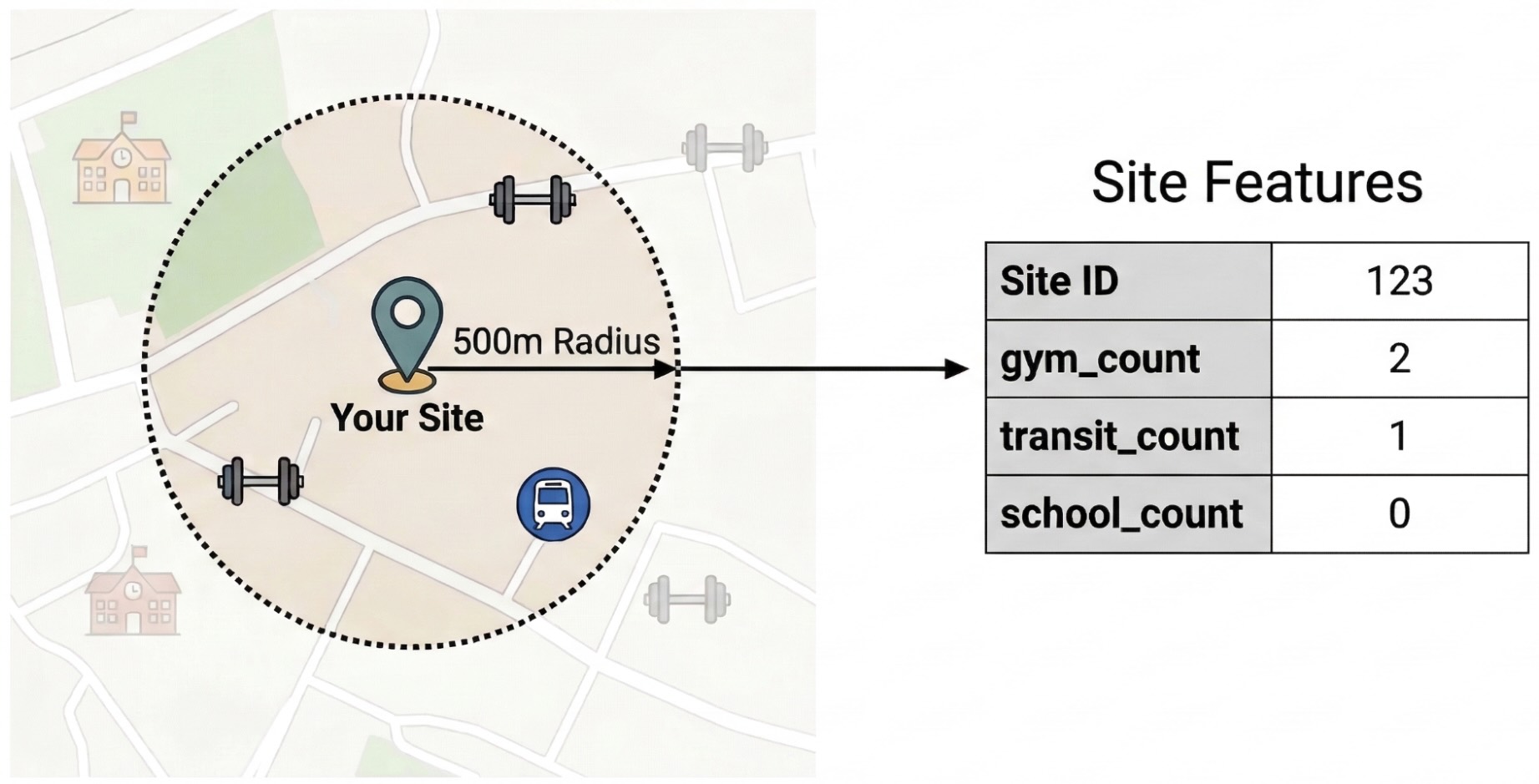
在此步骤中,我们将使用 Python 和 pandas-gbq 库。此方法可让您执行访问地点数据分析数据集所需的 SELECT WITH AGGREGATION_THRESHOLD 查询,并将结果保存到项目中的新表中。如需详细了解如何使用地点数据分析数据,请参阅直接查询数据集。
运行特征工程查询
在您的环境中(例如 Colab Enterprise)运行以下 Python 脚本。此脚本会将您的内部网站数据与地点数据分析数据集相关联。
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
了解查询
ST_DWITHIN:此地理空间函数会在每个地点位置周围创建一个 500 米的缓冲区,并识别落在该半径范围内的所有地点数据分析点。COUNTIF:此函数用于计算每个地点的特定场所类型(例如“健身房”“学校”)的密度。这些计数将成为机器学习模型的输入特征 (X)。pandas_gbq.to_gbq:此函数会将查询结果持久保存到新表 (site_features) 中。此永久表将作为 BigQuery ML 模型的干净训练数据集。
如需更高级的实际应用,不妨考虑计算多个距离(例如 250 米、500 米、1 公里)的特征,并探索其他地点数据分析属性,例如 rating、price_level 或 regular_opening_hours。如需查看地点数据分析属性的完整列表,请参阅支持的地点类型和核心架构参考。
使用 BigQuery ML 训练模型
将工程化特征保存到 site_features 表中后,您现在可以训练线性回归模型了。
此模型会学习每个环境特征 (X) 的最佳权重 (β),以预测网站的性能 (Y)。
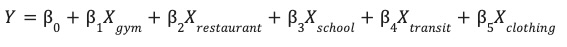
使用稳健缩放处理离群值
地理空间数据通常包含可能会扭曲标准线性模型的极端离群值。例如,伦敦西区的某个地点方圆 500 米内可能有 200 家餐厅,而郊区的某个地点方圆 500 米内可能只有 2 家餐厅。如果您使用标准缩放(平均值/标准差),则离群值 (200) 会使分布出现偏差,并迫使模型优先拟合该极值。
为解决此问题,我们在模型定义中使用了稳健缩放 (ML.ROBUST_SCALER)。此技术会根据中位数和四分位距 (IQR) 缩放特征,使模型能够应对离群值,并确保模型从网站的典型分布中学习。
创建模型
在 BigQuery 中运行以下 SQL 查询,以创建和训练模型。
我们使用 TRANSFORM 子句对所有输入特征应用稳健缩放。我们还设置了 optimize_strategy = 'NORMAL_EQUATION',因为对于相对较小的数据集(例如典型的商店位置组合),这是最有效的训练方法。最后,我们滤除表现出色的离群点 (store_performance <
75),以便模型专注于预测典型的增长模式。
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
评估模型性能
在信任模型对网站性能驱动因素的分析洞见之前,您必须验证其预测是否准确。
训练完成后,使用 ML.EVALUATE 函数根据训练期间未使用的“留出”数据集评估模型的预测结果。
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
检查 R2 分数 (r2_score) 和平均绝对误差 (mean_absolute_error),以确定模型是否已准备好用于生产环境:
- R2 得分用于衡量有多少性能方差实际上是由外部环境因素(附近的 POI)解释的。R2 得分为 0.70 表示网站成功的 70% 与当地环境有关。该值越接近 1.0,环境便利设施与网站性能之间的相关性就越强。
- 平均绝对误差 (MAE) 可告知您平均误差(以点为单位)。例如,如果 MAE 为 1.5,则表示模型的预测值通常与实际表现得分相差不超过 +/- 1.5 分。
排查得分偏低的问题
如果 R2 得分较低,请考虑进行以下改进:
- 扩展功能类型:向查询中添加不同的地点类型(例如
tourist_attraction、subway_station)。 - 调整集水区半径:更改
ST_DWITHIN距离。500 米的半径对于咖啡店来说可能太广,但对于家具店来说可能太小。 - 增加数据量:确保您使用足够多的商店位置进行训练,以便找到具有统计显著性的模式。
使用 H3 空间索引为城市评分
我们使用 H3 空间索引将伦敦市划分为一个均匀的六边形网格(分辨率为 8,面积约为 0.7 平方公里)。通过将地点数据分析数据汇总到这些单元格中,我们可以将训练好的模型应用于每个社区,从而识别出与效果最佳的营业场所的环境特征相匹配的高潜力区域。
运行潜在客户开发查询
为了生成此网格,我们使用了 地点数据分析 数据集提供的 PLACES_COUNT_PER_H3 函数(详细了解如何使用 Places Count 函数查询 地点数据分析)。此函数用于在一次操作中计算 H3 网格单元的 POI 数量。
运行以下 SQL 查询,以在一次执行中完成三个步骤:
- H3 索引和计数:我们称
PLACES_COUNT_PER_H3使用 JSON 配置对象来查找伦敦市中心方圆 25 公里内的所有营业地点。我们会针对每种便利设施类型(健身房、学校等)分别查询此数据,然后使用UNION ALL将它们合并。 - 透视(特征工程):由于我们的机器学习模型需要不同的特征列(例如
gym_count和restaurant_count),因此我们对单元格进行分组,并使用条件聚合(SUM(IF(...)))将数据透视为正确的架构。 - 预测:我们将这些透视后的网格特征直接馈送到
ML.PREDICT函数中,以生成每个社区的性能得分。
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
解读结果
该查询会返回一个表格,其中每行代表伦敦的一个六边形区域。
h3_index:六边形单元格的唯一标识符。predicted_store_performance:仅根据周围环境,模型对位于此单元格中的地点的估计得分。h3_geography:单元格的多边形几何图形,我们将在下一步中将其用于可视化。
高值表示学校、健身房和公交的密度与您最成功的现有网站周围的模式相匹配的区域。
直观呈现潜在客户开发地图
为了让数据发挥实际作用,请在地图上直观呈现结果。虽然表格输出会提供原始得分,但地图会显示列表无法直观呈现的高潜力空间聚类和走廊。
在随附的笔记本中,我们使用 geopandas 库解析 H3 多边形几何图形,并使用 folium 渲染交互式地图。
结果是一张分级统计图,其中每个六边形单元格都根据其预测得分着色。
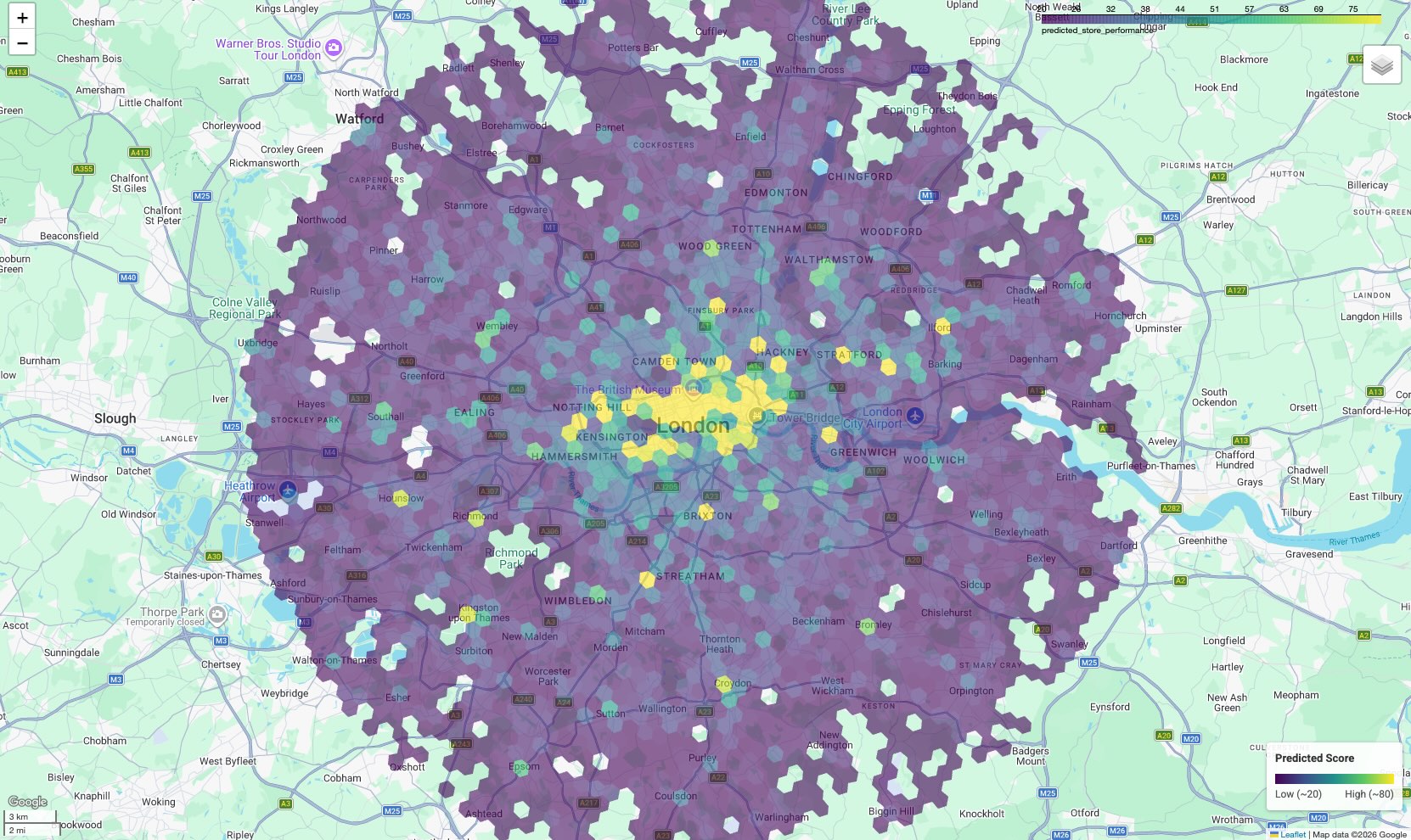
解读地图:
- 热点(黄色/绿色):这些区域的预测效果得分较高。这些位置拥有与成功网站相关的最佳学校、健身房和公交密度。这些是新选址的主要候选对象。
- 冷点(紫色):这些区域缺乏在表现出色的地点附近发现的支持性环境特征。
- 互动式检查:在笔记本环境中,您可以将鼠标悬停在任何单元格上,查看促成该特定得分的设施的具体数量(例如“健身房:12”)。
总结
您已成功将内部运营数据与地点数据分析相结合,以诊断网站性能。通过分析模型权重,您确定了与现有指标相关的特定社区特征。通过使用 H3 空间索引,您将此分析从数百个地点扩展到了伦敦数千个潜在社区。
后续操作
- 扩展特征工程:在查询中添加更具体的地点类型,以捕获小众的实体店客流量驱动因素。
- 探索高级模型:虽然线性回归具有清晰的可解释性,但您可以尝试在 BigQuery ML 中使用
BOOSTED_TREE_REGRESSOR并结合适当的交叉验证策略来捕获非线性关系。 - 将地图投入使用:使用 Maps JavaScript API 将 H3 网格结果导出到自定义信息中心,以便与团队分享这些数据洞见。
贡献者
- Henrik Valve | DevX 工程师
- Gennadii Donchyts | 资深客户工程师