

Neden bir site gelişirken diğeri tutarlı personel, envanter ve operasyonel uygulamalara rağmen düşük performans gösteriyor? Birden fazla konumu olan işletmeler, portföylerindeki bu performans farklılığını açıklamakta genellikle zorlanır. Cevap genellikle dış ortamda gizlidir. İlgilenilen yer (POI) verilerinden yararlanarak anekdot niteliğindeki açıklamaların ötesine geçebilir ve yerel rekabet yoğunluğu ile mahalle özelliklerinin bir sitenin başarısını tam olarak nasıl etkilediğini ölçebiliriz.
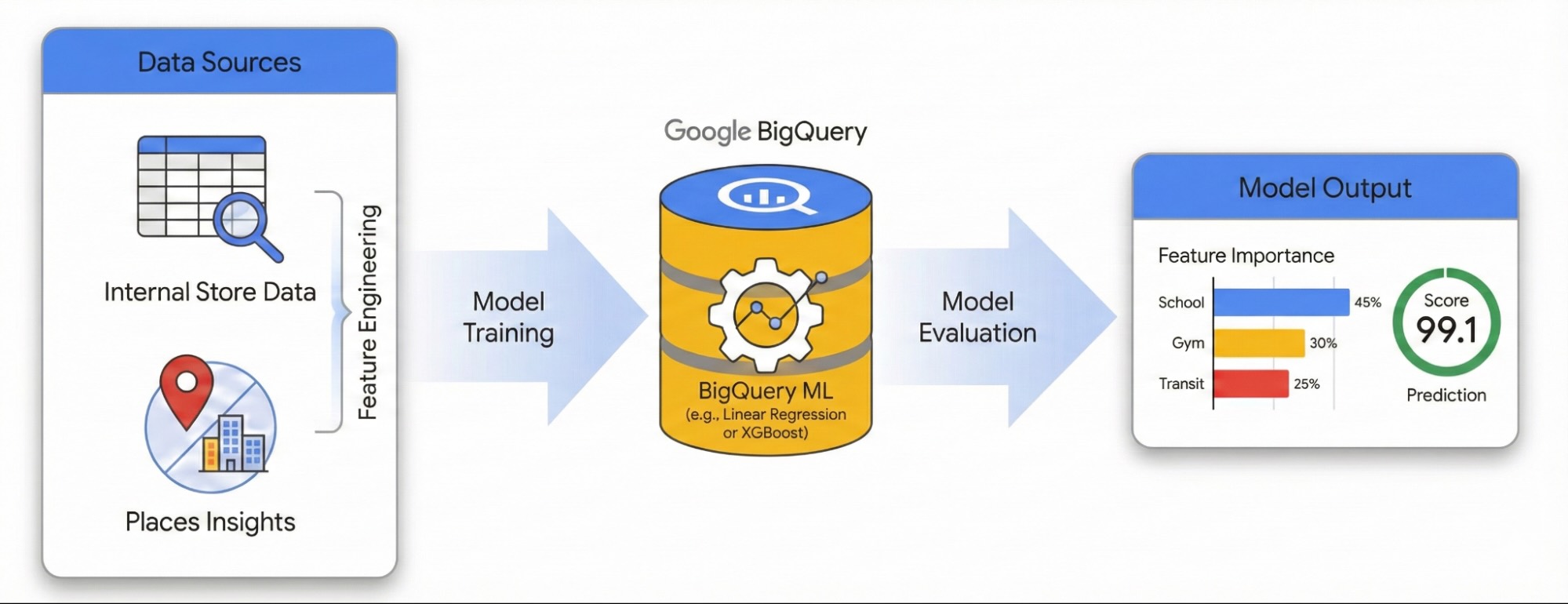
Bu kılavuzda, Places Insights ve BigQuery ML kullanarak yerel çevrenin site başarısı üzerindeki etkisini nasıl ölçebileceğiniz gösterilmektedir. Performansı etkileyen unsurları teşhis etmek için tescilli site performansı verilerinizi harici coğrafi sinyallerle birleştirirsiniz.
Doğrusal regresyon modeli oluşturmak için Londra'daki sitelerden oluşan bir veri kümesi kullanacağız. Bu iş akışında, şehri tek tip altıgen hücrelere bölen H3 Spatial Indexing sistemi kullanılır. Çevresel verileri bu hücrelerde toplayarak, yalnızca mevcut siteleriniz için değil, şehirdeki tüm mahallelerin performans potansiyelini tahmin edecek bir model eğitebilirsiniz.
Öğrenecekleriniz:
- Mühendislik Özellikleri: Sitelerinizin 500 metre yarıçapındaki spor salonları, okullar ve toplu taşıma istasyonları gibi önemli yerlerin (ÖY) toplam sayısı.
- Model Eğitme: Bu çevresel özellikleri dahili performans metriklerinizle ilişkilendiren bir regresyon modeli oluşturmak için BigQuery ML'yi kullanın.
- Şehre puan verin: Gelecekteki genişleme için yüksek potansiyelli önemli noktaları belirlemek amacıyla eğitimli modeli Londra'nın H3 ızgarasının tamamına uygulayın.
BigQuery ML'i yeni kullanmaya başladıysanız temel kavramlar ve desteklenen model türleri hakkında bilgi edinmek için BigQuery ML'e Giriş başlıklı makaleyi inceleyin.
Bu iş akışını etkileşimli bir ortamda keşfetmek için aşağıdaki not defterini çalıştırın. Bu codelab'de, BigQuery ML ile nasıl tahmini model oluşturulacağı ve H3 mekansal indeksleme kullanılarak şehir genelindeki fırsatların nasıl görselleştirileceği gösterilmektedir.
 Kaynağı GitHub'da görüntüle
Kaynağı GitHub'da görüntüle
Ön koşullar
Başlamadan önce aşağıdakilere sahip olduğunuzdan emin olun:
Google Cloud projesi:
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
Veri Erişimi:
- BigQuery'de Places Insights aboneliği.
- Performans metriği (ör. gelir) içeren kendi site konumları tablonuz. Örnek veri kümesini eğitim kaynaklarında bulabilirsiniz.
Google Haritalar Platformu:
- API anahtarı.
- Anahtarınız için aşağıdaki API'ler etkinleştirildi:
Python Ortamı ve Kitaplıkları:
- Google Cloud Console'da Colab Enterprise gibi bir Python ortamı.
- Aşağıdaki kitaplıklar yüklü olmalıdır:
Kitaplık Açıklama pandas-gbqBigQuery ile etkileşim kurma. geopandasCoğrafi veri işlemlerini gerçekleştirme foliumEtkileşimli haritalar oluşturma shapelyGeometrik manipülasyonlar.
IAM İzinleri:
- Kullanıcı veya hizmet hesabınızın aşağıdaki IAM rollerine sahip olduğundan emin olun:
Rol Kimlik BigQuery Veri Düzenleyicisi roles/bigquery.dataEditorBigQuery Kullanıcısı roles/bigquery.user
- Kullanıcı veya hizmet hesabınızın aşağıdaki IAM rollerine sahip olduğundan emin olun:
Maliyet Bilinci:
- Bu eğitimde, faturalandırılabilir Google Cloud bileşenleri kullanılmaktadır. Aşağıdakilerle ilgili
olası maliyetlere dikkat edin:
- BigQuery ML: Kullanılan işlem slotları için ücret alınır. BigQuery ML fiyatlandırmasına bakın.
- Places Insights: Sorgu kullanımına göre ücretlendirilir.
- Bu eğitimde, faturalandırılabilir Google Cloud bileşenleri kullanılmaktadır. Aşağıdakilerle ilgili
olası maliyetlere dikkat edin:
Places Insights ile Özellik Mühendisliği
Site performansını etkileyen harici faktörleri belirlemek için ham ÖY verilerini ölçülebilir özelliklere dönüştürmeniz gerekir. Her bir sitenin 500 metre yarıçapındaki belirli olanakların veya yer türlerinin (ör. spor salonları, okullar ve toplu taşıma istasyonları) yoğunluğunu hesaplarsınız. Seçtiğiniz olanaklar, işletmeniz için en alakalı olabileceğini düşündüğünüz öğelere bağlıdır.
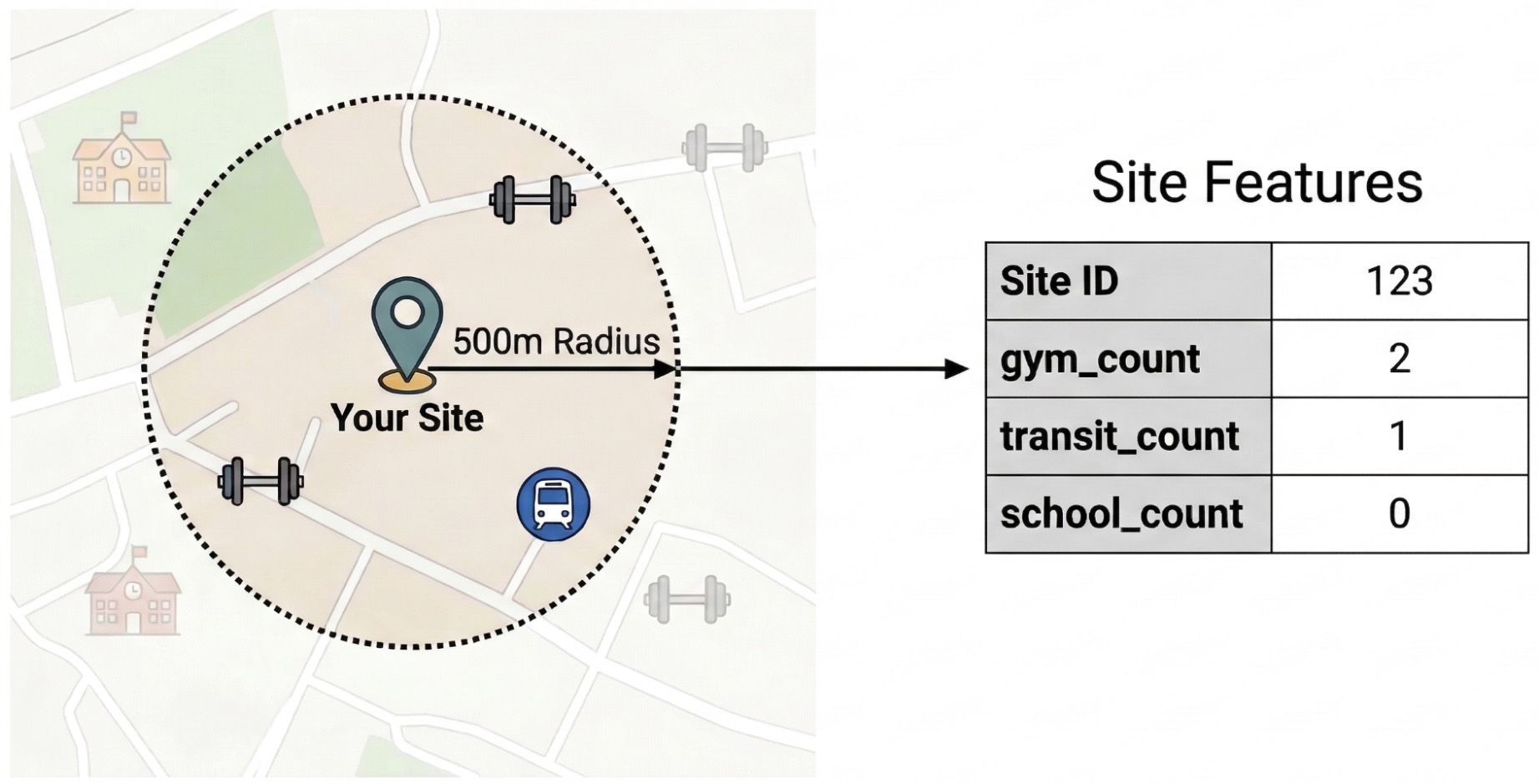
Bu adımda Python ve pandas-gbq kitaplığını kullanıyoruz. Bu yaklaşım, Places Insights veri kümesine erişmek için gereken SELECT WITH AGGREGATION_THRESHOLD sorgusunu yürütmenize ve sonuçları projenizdeki yeni bir tabloya kaydetmenize olanak tanır. Places Insights verileriyle çalışma hakkında daha fazla bilgi için Veri kümesini doğrudan sorgulama başlıklı makaleyi inceleyin.
Özellik Mühendisliği Sorgusunu Çalıştırma
Ortamınızda (ör. Colab Enterprise) aşağıdaki Python komut dosyasını çalıştırın. Bu komut dosyası, dahili site verilerinizi Places Insights veri kümesine bağlar.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Sorguyu Anlama
ST_DWITHIN: Bu coğrafi işlev, her site konumunun çevresinde 500 metrelik bir arabellek oluşturur ve bu yarıçap içinde kalan tüm Places Insights noktalarını tanımlar.COUNTIF: Bu işlev, her alan için belirli yer türlerinin (ör. "spor salonu", "okul") yoğunluğunu hesaplar. Bu sayımlar, makine öğrenimi modelinin giriş özellikleri (X) haline gelir.pandas_gbq.to_gbq: Bu işlev, sorgu sonuçlarını yeni bir tabloya (site_features) kalıcı olarak kaydeder. Bu kalıcı tablo, BigQuery ML modeli için temiz eğitim veri kümesi olarak kullanılır.
Daha gelişmiş gerçek dünya uygulamaları için özellikleri birden fazla mesafede (ör. 250 m, 500 m, 1 km) hesaplamayı ve rating, price_level veya regular_opening_hours gibi diğer Places Insights özelliklerini keşfetmeyi düşünebilirsiniz. Places Insights özelliklerinin tam listesi için desteklenen yer türleri ve çekirdek şema referansı bölümüne bakın.
BigQuery ML ile modeli eğitme
site_features tablonuza kaydedilen mühendislik ürünü özelliklerle artık doğrusal regresyon modelini eğitebilirsiniz.
Bu model, sitenizin performansını (Y) tahmin etmek için her bir çevresel özellik (X) için optimum ağırlıkları (β) öğrenir.
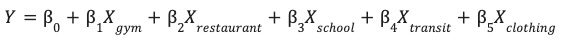
Aykırı Değerleri Güçlü Ölçeklendirme ile İşleme
Coğrafi veriler genellikle standart doğrusal modelleri bozabilecek aşırı aykırı değerler içerir. Örneğin, Londra'nın West End bölgesindeki bir sitede 500 metre içinde 200 restoran bulunurken banliyödeki bir sitede yalnızca 2 restoran olabilir. Standart ölçeklendirme (ortalama/standart sapma) kullanıyorsanız aykırı değer (200) dağılımı çarpıtır ve modeli bu uç değeri uydurmaya öncelik vermeye zorlar.
Bu sorunu çözmek için model tanımında Robust Scaling (ML.ROBUST_SCALER) kullanırız. Bu teknik, özellikleri medyan ve çeyrekler arası aralığa (IQR) göre ölçeklendirerek modeli aykırı değerlere karşı dayanıklı hale getirir ve sitelerinizin tipik dağılımından öğrenmesini sağlar.
Modeli oluşturma
Modeli oluşturup eğitmek için BigQuery'de aşağıdaki SQL sorgusunu çalıştırın.
Tüm giriş özelliklerine güçlü ölçeklendirme uygulamak için
TRANSFORM
ifadesini kullanırız. Ayrıca, tipik bir mağaza konumları portföyü gibi nispeten küçük veri kümeleri için en verimli eğitim yöntemi olduğundan optimize_strategy = 'NORMAL_EQUATION' değerini de ayarladık. Son olarak, modeli tipik büyüme kalıplarını tahmin etmeye odaklamak için yüksek performanslı aykırı değerleri (store_performance <
75) filtreleriz.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Model performansını değerlendirme
Modelin site performansını etkileyen faktörlerle ilgili analizlerine güvenebilmeniz için tahminlerinin doğru olduğunu doğrulamanız gerekir.
Eğitimden sonra, modelin tahminlerini eğitim sırasında kullanılmayan bir "ayrılmış" veri kümesine göre değerlendirmek için ML.EVALUATE işlevini kullanın.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Modelinizin üretime hazır olup olmadığını belirlemek için R2
Puanı
(r2_score) ve Ortalama Mutlak Hata'yı
(mean_absolute_error) kontrol edin:
- R2 puanı, performans varyansının ne kadarının aslında dış çevresel faktörlerle (yakındaki ÖY'ler) açıklandığını ölçer. 0,70 R2 puanı, bir sitenin başarısının% 70'inin yerel ortamla ilişkili olduğu anlamına gelir. 1, 0'a ne kadar yakın olursa çevresel olanaklar ile site performansı arasındaki korelasyon o kadar güçlü olur.
- MAE, puanlardaki ortalama hatayı gösterir. Örneğin, 1,5'lik bir MAE, modelin tahminlerinin genellikle gerçek performans puanının +/- 1,5 puanı içinde olduğu anlamına gelir.
Düşük puanlarla ilgili sorunları giderme
R2 puanınız düşükse aşağıdaki iyileştirmeleri yapabilirsiniz:
- Özellik Türlerini Genişletme: Sorgunuza farklı Yer Türleri ekleyin (ör.
tourist_attraction,subway_station). - Kapsama Alanı Yarıçapını Ayarlama:
ST_DWITHINmesafesini değiştirin. 500 metrelik bir yarıçap, kafe için çok geniş, mobilya mağazası için ise çok küçük olabilir. - Veri boyutunu artırın: İstatistiksel olarak anlamlı bir kalıp bulmak için yeterli sayıda mağaza konumunda eğitim yaptığınızdan emin olun.
H3 Mekansal Dizinleme ile Şehri Puanlama
Londra şehrini altıgen hücrelerden oluşan tek tip bir ızgaraya (Çözünürlük 8, yaklaşık 0, 7 km²) bölmek için H3 Spatial Indexing'i kullanırız. Places Insights verilerini bu hücrelerde toplayarak eğitimli modelimizi her mahalleye uygulayabilir, en iyi performans gösteren sitelerinizin çevresel profiline uyan yüksek potansiyelli alanları belirleyebiliriz.
Potansiyel müşteri kazanma sorgusunu çalıştırma
Bu ızgarayı oluşturmak için Places Insights veri kümesi tarafından sağlanan PLACES_COUNT_PER_H3 fonksiyonunu kullanırız (Yer Sayısı fonksiyonlarını kullanarak Places Insights'ı sorgulama hakkında daha fazla bilgi edinin).
Bu işlev, tek bir işlemde H3 ızgara hücreleri için ÖY sayısını hesaplar.
Tek bir yürütmede üç adım gerçekleştirmek için aşağıdaki SQL sorgusunu çalıştırın:
- H3 Indexing & Counting: Londra'nın merkezine 25 km uzaklıkta bulunan tüm operasyonel yerleri bulmak için JSON yapılandırma nesnesi kullanarak
PLACES_COUNT_PER_H3çağrısı yapıyoruz. Bunu her olanak türü (ör. spor salonları, okullar) için ayrı ayrı sorgulayıpUNION ALLkullanarak birleştiririz. - Döndürme (Özellik Mühendisliği): Makine öğrenimi modelimiz farklı özellik sütunları (ör.
gym_countverestaurant_count) beklediğinden, hücreleri gruplandırır ve verileri doğru şemaya döndürmek için koşullu toplama(SUM(IF(...)))kullanırız. - Tahmin: Her mahalle için performans puanı oluşturmak amacıyla bu döndürülmüş ızgara özelliklerini doğrudan
ML.PREDICTişlevine aktarırız.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Sonuçları yorumlama
Sorgu, her satırın Londra'daki altıgen bir alanı temsil ettiği bir tablo döndürür.
h3_index: Altıgen hücrenin benzersiz tanımlayıcısı.predicted_store_performance: Yalnızca çevredeki ortama dayalı olarak bu hücrede bulunan bir site için modelin tahmini puanı.h3_geography: Hücrenin çokgen geometrisi. Bunu, sonraki adımda görselleştirme için kullanacağız.
Yüksek değerler, okul, spor salonu ve toplu taşıma yoğunluğunun en başarılı mevcut sitelerinizdeki kalıplarla eşleştiği alanları gösterir.
Potansiyel müşteri haritasını görselleştirme
Verileri uygulanabilir hale getirmek için sonuçları haritada görselleştirin. Tablo biçimindeki çıktı ham puanları sağlarken harita, listede açıkça görülmeyen yüksek potansiyelli mekansal kümeleri ve koridorları ortaya çıkarır.
Ekteki not defterinde, H3 çokgen geometrisini ayrıştırmak için geopandas kitaplığını, etkileşimli bir harita oluşturmak için ise folium kitaplığını kullanıyoruz.
Sonuç, her altıgen hücrenin tahmini puanına göre renklendirildiği bir renk tonlu haritadır.
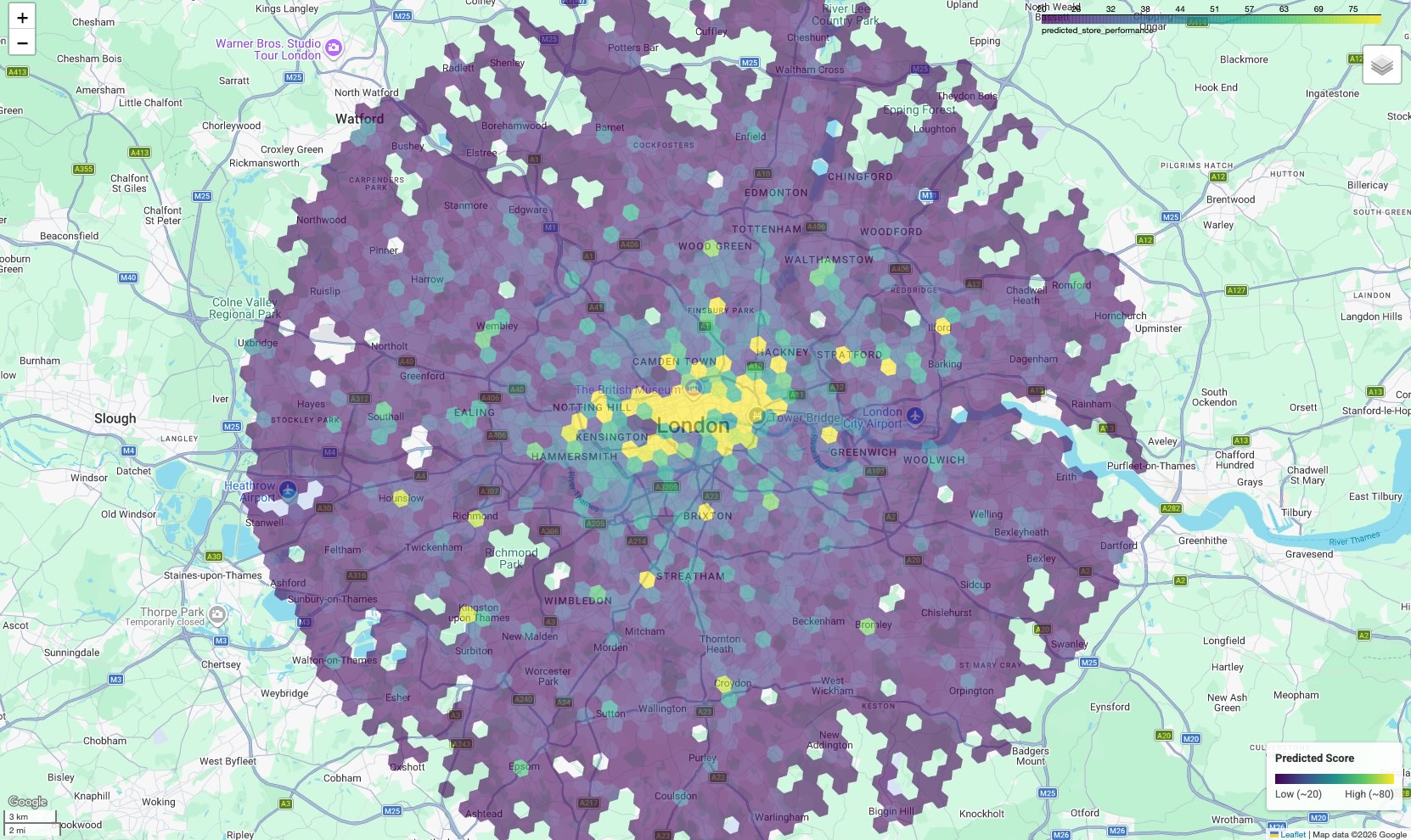
Haritayı yorumlama:
- Yoğun ilgi gören yerler (Sarı/Yeşil): Bu alanların performans puanlarının yüksek olması beklenir. Başarılı sitelerinizle ilişkili olan optimum okul, spor salonu ve toplu taşıma yoğunluğuna sahiptirler. Bunlar, yeni site seçimi için uygun adaylardır.
- Soğuk noktalar (mor): Bu alanlarda, en iyi performans gösteren ürünlerinizin yakınında bulunan destekleyici çevresel özellikler yoktur.
- Etkileşimli İnceleme: Not defteri ortamında, belirli bir puana katkıda bulunan olanakların (ör. "Spor salonları: 12") sayısını görmek için herhangi bir hücrenin üzerine gelebilirsiniz.
Sonuç
Site performansını teşhis etmek için dahili operasyonel verileri Places Insights ile başarıyla birleştirdiniz. Model ağırlıklarını analiz ederek mevcut metriklerinizle ilişkili olan belirli mahalle özelliklerini belirlediniz. H3 uzamsal indekslemeyi kullanarak bu analizi birkaç yüz siteden Londra genelindeki binlerce potansiyel mahalleye ölçeklendirdiniz.
Sonraki İşlemler
- Genişletilmiş Özellik Mühendisliği: Yaya trafiğinin niş sürücülerini yakalamak için sorgunuza daha spesifik Yer Türleri ekleyin.
- Gelişmiş Modelleri Keşfedin: Doğrusal regresyon net bir açıklanabilirlik sağlarken doğrusal olmayan ilişkileri yakalamak için uygun bir çapraz doğrulama stratejisiyle birlikte BigQuery ML'de
BOOSTED_TREE_REGRESSORile denemeler yapın. - Haritayı kullanıma sunma: Bu analizleri ekibinizle paylaşmak için H3 ızgara sonuçlarını Maps JavaScript API'yi kullanarak özel bir kontrol paneline aktarın.
Katkıda bulunanlar
- Henrik Valve | DevX Engineer
- Gennadii Donchyts | Staff Customer Engineer