

เหตุใดเว็บไซต์หนึ่งจึงเติบโตได้ดีในขณะที่อีกเว็บไซต์หนึ่งมีประสิทธิภาพต่ำแม้ว่าจะมี การจัดสรรบุคลากร สินค้าคงคลัง และแนวทางปฏิบัติในการดำเนินงานที่สอดคล้องกัน ธุรกิจที่มี หลายสาขามักอธิบายความแตกต่างของประสิทธิภาพนี้ใน พอร์ตโฟลิโอได้ยาก โดยปกติแล้ว คำตอบมักจะซ่อนอยู่ในสภาพแวดล้อมภายนอก การใช้ประโยชน์จากข้อมูลจุดที่น่าสนใจ (POI) ช่วยให้เราอธิบายได้มากกว่าแค่เรื่องเล่า และระบุปริมาณได้อย่างแม่นยำว่าความหนาแน่นของการแข่งขันในพื้นที่และลักษณะของย่าน เป็นตัวกำหนดความสำเร็จของสถานที่ตั้งได้อย่างไร
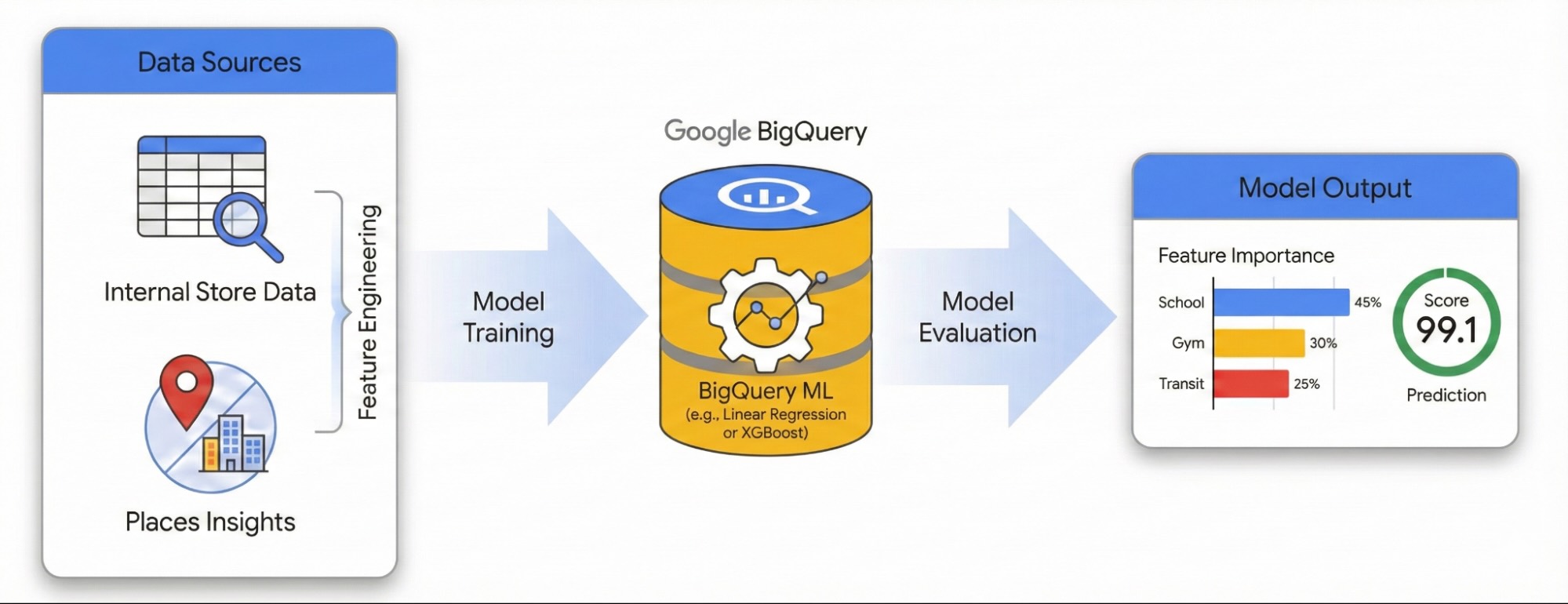
คู่มือนี้แสดงวิธีวัดผลกระทบของสภาพแวดล้อมในพื้นที่ต่อความสําเร็จของสถานที่ตั้งโดยใช้ ข้อมูลเชิงลึกเกี่ยวกับสถานที่ และ BigQuery ML คุณจะรวมข้อมูลประสิทธิภาพเว็บไซต์ที่เป็นกรรมสิทธิ์เข้ากับสัญญาณเชิงพื้นที่ภายนอก เพื่อวิเคราะห์ปัจจัยที่ขับเคลื่อนประสิทธิภาพ
เราจะใช้ชุดข้อมูลของสถานที่ตั้งในลอนดอนเพื่อสร้างโมเดลการถดถอยเชิงเส้น เวิร์กโฟลว์นี้ใช้การจัดทำดัชนีเชิงพื้นที่ H3 ระบบนี้จะแบ่งเมืองออกเป็นเซลล์หกเหลี่ยมที่สม่ำเสมอ การรวบรวม ข้อมูลด้านสิ่งแวดล้อมไว้ในเซลล์เหล่านี้ช่วยให้คุณฝึกโมเดลเพื่อคาดการณ์ ศักยภาพด้านประสิทธิภาพของย่านใดก็ได้ในเมือง ไม่ใช่แค่ไซต์ที่มีอยู่ เท่านั้น
คุณจะได้เรียนรู้วิธีต่อไปนี้
- ฟีเจอร์วิศวกร: รวบรวมจำนวนจุดที่น่าสนใจ (POI) เช่น ยิม โรงเรียน และสถานีขนส่งภายในรัศมี 500 เมตรจากเว็บไซต์ของคุณ
- ฝึกโมเดล: ใช้ BigQuery ML เพื่อสร้างโมเดลการถดถอยที่เชื่อมโยงฟีเจอร์ด้านสิ่งแวดล้อมเหล่านี้กับเมตริกประสิทธิภาพภายใน
- ให้คะแนนเมือง: ใช้โมเดลที่ฝึกแล้วกับตาราง H3 ทั้งหมดของลอนดอน เพื่อระบุฮอตสปอตที่มีศักยภาพสูงสำหรับการขยายธุรกิจในอนาคต
หากเพิ่งเริ่มใช้ BigQuery ML โปรดดูข้อมูลเบื้องต้นเกี่ยวกับ BigQuery ML เพื่อเรียนรู้ เกี่ยวกับแนวคิดหลักและประเภทโมเดลที่รองรับ
หากต้องการสำรวจเวิร์กโฟลว์นี้ในสภาพแวดล้อมแบบอินเทอร์แอกทีฟ ให้เรียกใช้สมุดบันทึกต่อไปนี้ โดยจะแสดงวิธีสร้างโมเดลการคาดการณ์ด้วย BigQuery ML และแสดงภาพโอกาสทั่วทั้งเมืองโดยใช้การจัดทำดัชนีเชิงพื้นที่ H3
 ดูแหล่งที่มาใน GitHub
ดูแหล่งที่มาใน GitHub
ข้อกำหนดเบื้องต้น
ก่อนเริ่มต้น โปรดตรวจสอบว่าคุณมีสิ่งต่อไปนี้
โปรเจ็กต์ Google Cloud:
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
การเข้าถึงข้อมูล:
- การสมัครใช้บริการข้อมูลเชิงลึกเกี่ยวกับสถานที่ ใน BigQuery
- ตารางสถานที่ตั้งของเว็บไซต์ของคุณเองที่มีเมตริกประสิทธิภาพ (เช่น รายได้) ชุดข้อมูลตัวอย่างอยู่ในแหล่งข้อมูล บทแนะนำ
Google Maps Platform:
- คีย์ API
- API ต่อไปนี้เปิดใช้สำหรับคีย์ของคุณ
สภาพแวดล้อมและไลบรารีของ Python:
- สภาพแวดล้อม Python เช่น Colab Enterprise ใน Google Cloud Console
- ติดตั้งไลบรารีต่อไปนี้
คลัง คำอธิบาย pandas-gbqการโต้ตอบกับ BigQuery geopandasการจัดการการดำเนินการข้อมูลเชิงพื้นที่ foliumการสร้างแผนที่แบบอินเทอร์แอกทีฟ shapelyการดัดแปลงทางเรขาคณิต
สิทธิ์ IAM:
- ตรวจสอบว่าบัญชีผู้ใช้หรือบัญชีบริการมีบทบาท IAM ต่อไปนี้
บทบาท รหัส ผู้แก้ไขข้อมูล BigQuery roles/bigquery.dataEditorผู้ใช้ BigQuery roles/bigquery.user
- ตรวจสอบว่าบัญชีผู้ใช้หรือบัญชีบริการมีบทบาท IAM ต่อไปนี้
การรับรู้ต้นทุน:
- บทแนะนำนี้ใช้คอมโพเนนต์ Google Cloud ที่เรียกเก็บเงินได้ โปรดทราบว่า
ค่าใช้จ่ายที่อาจเกิดขึ้นเกี่ยวข้องกับสิ่งต่อไปนี้
- BigQuery ML: ระบบจะเรียกเก็บเงินสำหรับสล็อตการประมวลผลที่ใช้ ดูราคาของ BigQuery ML
- ข้อมูลเชิงลึกเกี่ยวกับสถานที่: เรียกเก็บเงินตามการใช้งานการค้นหา
- บทแนะนำนี้ใช้คอมโพเนนต์ Google Cloud ที่เรียกเก็บเงินได้ โปรดทราบว่า
ค่าใช้จ่ายที่อาจเกิดขึ้นเกี่ยวข้องกับสิ่งต่อไปนี้
Feature Engineering ด้วยข้อมูลเชิงลึกเกี่ยวกับสถานที่
หากต้องการแยกปัจจัยภายนอกที่ขับเคลื่อนประสิทธิภาพของเว็บไซต์ คุณต้องเปลี่ยนข้อมูล POI ดิบ ให้เป็นฟีเจอร์ที่วัดปริมาณได้ คุณจะคำนวณความหนาแน่นของสิ่งอำนวยความสะดวกหรือประเภทสถานที่ที่เฉพาะเจาะจง เช่น ยิม โรงเรียน และสถานีขนส่ง ภายในรัศมี 500 เมตรของแต่ละสถานที่ตั้ง สิ่งอำนวยความสะดวกที่คุณเลือกจะขึ้นอยู่กับสิ่งที่คุณเชื่อว่าอาจเกี่ยวข้องกับธุรกิจของคุณมากที่สุด
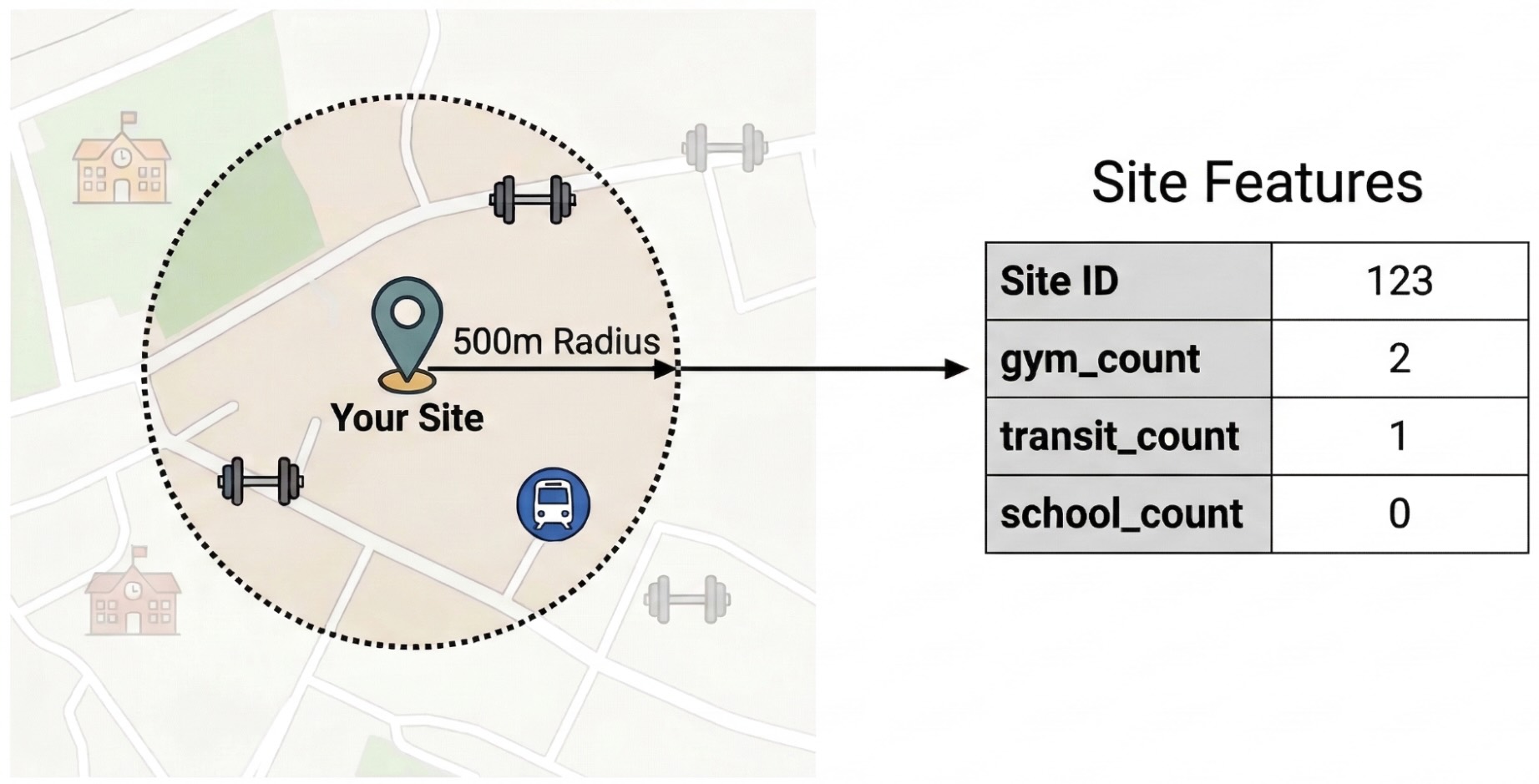
เราใช้ Python และไลบรารี pandas-gbq สำหรับขั้นตอนนี้ แนวทางนี้ช่วยให้คุณ
เรียกใช้SELECT WITH AGGREGATION_THRESHOLDคำค้นหา ซึ่งจำเป็นต่อการ
เข้าถึงชุดข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่ และบันทึกผลลัพธ์ลงในตารางใหม่ใน
โปรเจ็กต์ ดูข้อมูลเพิ่มเติมเกี่ยวกับ
การทำงานกับข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่ได้ที่ค้นหาชุดข้อมูล
โดยตรง
เรียกใช้การค้นหา Feature Engineering
เรียกใช้สคริปต์ Python ต่อไปนี้ในสภาพแวดล้อมของคุณ (เช่น Colab Enterprise) สคริปต์นี้จะเชื่อมต่อข้อมูลเว็บไซต์ภายในกับชุดข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
ทำความเข้าใจคำค้นหา
ST_DWITHIN: ฟังก์ชันเชิงพื้นที่นี้สร้างบัฟเฟอร์ 500 เมตรโดยรอบ สถานที่ตั้งแต่ละแห่ง และระบุจุดข้อมูลเชิงลึกเกี่ยวกับสถานที่ทั้งหมดที่อยู่ ภายในรัศมีนั้นCOUNTIF: ฟังก์ชันนี้จะคำนวณความหนาแน่นของสถานที่ประเภทหนึ่งๆ (เช่น "ยิม" "โรงเรียน") สำหรับแต่ละสถานที่ตั้ง จำนวนเหล่านี้จะกลายเป็นฟีเจอร์ อินพุต (X) สำหรับโมเดลแมชชีนเลิร์นนิงpandas_gbq.to_gbq: ฟังก์ชันนี้จะบันทึกผลการค้นหาลงในตารางใหม่ (site_features) ตารางถาวรนี้ทำหน้าที่เป็นชุดข้อมูลการฝึกที่สะอาดสำหรับโมเดล BigQuery ML
สำหรับการใช้งานจริงที่ซับซ้อนมากขึ้น ให้ลองคำนวณฟีเจอร์ที่
ระยะทางหลายระดับ (เช่น 250 ม., 500 ม., 1 กม.) และสำรวจข้อมูลเชิงลึกเกี่ยวกับสถานที่อื่นๆ
เช่น rating, price_level หรือ regular_opening_hours ดูรายการแอตทริบิวต์ข้อมูลเชิงลึกเกี่ยวกับสถานที่ทั้งหมดได้ที่ประเภทสถานที่ที่รองรับและข้อมูลอ้างอิงของสคีมาหลัก
ฝึกโมเดลด้วย BigQuery ML
เมื่อบันทึกฟีเจอร์ที่ออกแบบไว้ในตาราง site_features แล้ว คุณก็สามารถฝึกโมเดลการถดถอยเชิงเส้นได้
โมเดลนี้จะเรียนรู้น้ำหนักที่เหมาะสม (β) สำหรับฟีเจอร์ด้านสิ่งแวดล้อมแต่ละรายการ (X) เพื่อคาดการณ์ประสิทธิภาพของเว็บไซต์ (Y)
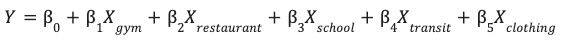
จัดการค่าผิดปกติด้วยการปรับขนาดที่มีประสิทธิภาพ
ข้อมูลเชิงพื้นที่มักมีค่าผิดปกติที่มากเกินไปซึ่งอาจบิดเบือนโมเดลเชิงเส้นมาตรฐาน ตัวอย่างเช่น สถานที่ตั้งในเวสต์เอนด์ของลอนดอนอาจมีร้านอาหาร 200 แห่ง ภายในรัศมี 500 เมตร ในขณะที่สถานที่ตั้งในย่านชานเมืองมีเพียง 2 แห่ง หากคุณใช้การปรับขนาดมาตรฐาน (ค่าเฉลี่ย/ส่วนเบี่ยงเบนมาตรฐาน) ค่าผิดปกติ (200) จะทำให้การกระจายเบ้และบังคับให้โมเดลจัดลําดับความสําคัญของการปรับค่าสุดขั้วนั้น
เราจึงใช้การปรับขนาด
ที่เสถียร
(ML.ROBUST_SCALER) ภายในคำจำกัดความของโมเดลเพื่อแก้ปัญหานี้ เทคนิคนี้จะปรับขนาดฟีเจอร์ตามค่ามัธยฐานและช่วงควอไทล์ (IQR) ซึ่งจะช่วยให้โมเดลทนทานต่อค่าผิดปกติและมั่นใจได้ว่าโมเดลจะเรียนรู้จากการกระจายทั่วไปของเว็บไซต์
สร้างโมเดล
เรียกใช้การค้นหา SQL ต่อไปนี้ใน BigQuery เพื่อสร้างและฝึกโมเดล
เราใช้
TRANSFORM
เพื่อใช้การปรับขนาดที่แข็งแกร่งกับฟีเจอร์อินพุตทั้งหมด นอกจากนี้ เรายังตั้งค่า
optimize_strategy = 'NORMAL_EQUATION' เนื่องจากเป็นวิธีการฝึกที่มีประสิทธิภาพมากที่สุด
สำหรับชุดข้อมูลขนาดเล็ก เช่น พอร์ตโฟลิโอทั่วไปของที่ตั้งร้านค้า สุดท้าย เราจะกรองค่าผิดปกติที่มีประสิทธิภาพสูง (store_performance <
75) เพื่อให้โมเดลมุ่งเน้นที่การคาดการณ์รูปแบบการเติบโตทั่วไป
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
ประเมินประสิทธิภาพของโมเดล
ก่อนที่จะเชื่อมั่นในข้อมูลเชิงลึกของโมเดลเกี่ยวกับสิ่งที่ขับเคลื่อนประสิทธิภาพของเว็บไซต์ คุณต้องยืนยันว่าการคาดการณ์ของโมเดลนั้นถูกต้อง
หลังจากการฝึก ให้ใช้ฟังก์ชัน ML.EVALUATE เพื่อประเมินการคาดการณ์ของโมเดล
เทียบกับชุดข้อมูล "Holdout" ที่ไม่ได้ใช้ในระหว่างการฝึก
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
ตรวจสอบคะแนน R2
(r2_score) และค่าความคลาดเคลื่อนสัมบูรณ์เฉลี่ย
(mean_absolute_error) เพื่อดูว่าโมเดลพร้อมใช้งานจริงหรือไม่
- คะแนน R2 จะวัดว่าความแปรปรวนของประสิทธิภาพที่เกิดขึ้นจริงนั้น อธิบายได้ด้วยปัจจัยด้านสภาพแวดล้อมภายนอก (จุดที่น่าสนใจใกล้เคียง) มากน้อยเพียงใด คะแนน R2 ที่ 0.70 หมายความว่าความสำเร็จของเว็บไซต์ 70% เชื่อมโยงกับสภาพแวดล้อมในพื้นที่ ยิ่งค่าเข้าใกล้ 1.0 มากเท่าใด ความสัมพันธ์ระหว่างสิ่งอำนวยความสะดวกด้านสิ่งแวดล้อมกับประสิทธิภาพของสถานที่ตั้งก็จะยิ่งแข็งแกร่งมากขึ้นเท่านั้น
- MAE จะบอกข้อผิดพลาดเฉลี่ยเป็นคะแนน ตัวอย่างเช่น MAE ที่ 1.5 หมายความว่าโดยปกติแล้วการคาดการณ์ของโมเดลจะอยู่ภายใน +/- 1.5 คะแนนของคะแนนประสิทธิภาพจริง
การแก้ปัญหาคะแนนต่ำ
หากคะแนน R2 ต่ำ ให้พิจารณาปรับปรุงสิ่งต่อไปนี้
- ขยายประเภทฟีเจอร์: เพิ่มประเภทสถานที่
ต่างๆ ลงในคำค้นหา (เช่น
tourist_attraction,subway_station) - ปรับรัศมีพื้นที่ครอบคลุม: เปลี่ยน
ST_DWITHINระยะทาง รัศมี 500 เมตรอาจกว้างเกินไปสำหรับร้านกาแฟ แต่เล็กเกินไปสำหรับร้านเฟอร์นิเจอร์ - เพิ่มขนาดข้อมูล: ตรวจสอบว่าคุณฝึกโมเดลในสถานที่ตั้งของร้านค้ามากพอที่จะ ค้นหารูปแบบที่มีนัยสำคัญทางสถิติ
ให้คะแนนเมืองด้วยการจัดทำดัชนีเชิงพื้นที่ H3
เราใช้การจัดทำดัชนีเชิงพื้นที่ H3 เพื่อแบ่งเมืองลอนดอนออกเป็นตารางกริดสม่ำเสมอของเซลล์หกเหลี่ยม (ความละเอียด 8 ประมาณ 0.7 กม.²) การรวบรวมข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่จาก Places Insights ลงในเซลล์เหล่านี้ช่วยให้เราใช้โมเดลที่ฝึกแล้วกับทุกย่านได้ โดยจะระบุพื้นที่ที่มีศักยภาพสูงซึ่งตรงกับโปรไฟล์ด้านสิ่งแวดล้อมของเว็บไซต์ที่มีประสิทธิภาพสูงสุด
เรียกใช้การค้นหาการหาลูกค้าใหม่
เราใช้ฟังก์ชัน
PLACES_COUNT_PER_H3
ที่ได้จากชุดข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่เพื่อสร้างตารางกริดนี้ (ดูข้อมูลเพิ่มเติมเกี่ยวกับการค้นหา
ข้อมูลเชิงลึกเกี่ยวกับสถานที่โดยใช้ฟังก์ชัน
Places Count)
ฟังก์ชันนี้จะคำนวณจำนวนจุดที่น่าสนใจสำหรับเซลล์ตารางกริด H3 ในการดำเนินการครั้งเดียว
เรียกใช้การค้นหาด้วย SQL ต่อไปนี้เพื่อดำเนินการ 3 ขั้นตอนในการดำเนินการครั้งเดียว
- การจัดทำดัชนีและการนับ H3: เราเรียกใช้
PLACES_COUNT_PER_H3โดยใช้ออบเจ็กต์การกำหนดค่า JSON เพื่อค้นหาสถานที่ที่เปิดให้บริการทั้งหมดภายในรัศมี 25 กม. จากใจกลางลอนดอน เราจะค้นหาข้อมูลนี้แยกกันสำหรับสิ่งอำนวยความสะดวกแต่ละประเภท (ยิม โรงเรียน ฯลฯ) แล้วรวมเข้าด้วยกันโดยใช้UNION ALL - การหมุน (การออกแบบฟีเจอร์): เนื่องจากโมเดลแมชชีนเลิร์นนิงของเรา คาดหวังคอลัมน์ฟีเจอร์ที่แตกต่างกัน (เช่น
gym_countและrestaurant_count) เราจึงจัดกลุ่มเซลล์และใช้การรวมแบบมีเงื่อนไข(SUM(IF(...)))เพื่อหมุน ข้อมูลเป็นสคีมาที่ถูกต้อง - การคาดการณ์: เราป้อนฟีเจอร์ตารางที่หมุนเหล่านี้ลงในฟังก์ชัน
ML.PREDICTโดยตรงเพื่อสร้างคะแนนประสิทธิภาพสำหรับทุก ย่าน
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
ตีความผลลัพธ์
การค้นหาจะแสดงตารางที่แต่ละแถวแสดงพื้นที่หกเหลี่ยมในลอนดอน
h3_index: ตัวระบุที่ไม่ซ้ำกันสำหรับเซลล์หกเหลี่ยมpredicted_store_performance: คะแนนโดยประมาณของโมเดลสำหรับสถานที่ตั้ง ที่อยู่ในเซลล์นี้ โดยอิงตามสภาพแวดล้อมโดยรอบเท่านั้นh3_geography: รูปเรขาคณิตของรูปหลายเหลี่ยมของเซลล์ ซึ่งเราจะใช้สำหรับการแสดงภาพในขั้นตอนถัดไป
ค่าสูงแสดงถึงพื้นที่ที่มีความหนาแน่นของโรงเรียน ยิม และระบบขนส่ง ตรงกับรูปแบบที่พบรอบๆ สถานที่ที่มีอยู่ซึ่งประสบความสำเร็จมากที่สุด
แสดงภาพแผนที่การหาลูกค้าใหม่
หากต้องการให้ข้อมูลนำไปใช้ได้จริง ให้แสดงภาพผลลัพธ์บนแผนที่ แม้ว่าเอาต์พุตแบบตารางจะให้คะแนนดิบ แต่แผนที่จะแสดงคลัสเตอร์เชิงพื้นที่และเส้นทางที่มีศักยภาพสูงซึ่งไม่ชัดเจนในรายการ
ใน Notebook ที่มาพร้อมกันนี้ เราใช้ไลบรารี geopandas เพื่อแยกวิเคราะห์รูปเรขาคณิตของรูปหลายเหลี่ยม H3
และใช้ folium เพื่อแสดงแผนที่แบบอินเทอร์แอกทีฟ
ผลลัพธ์ที่ได้คือแผนที่โคโรเพลท ซึ่งเซลล์หกเหลี่ยมทุกเซลล์จะมีสีตามคะแนนที่คาดการณ์
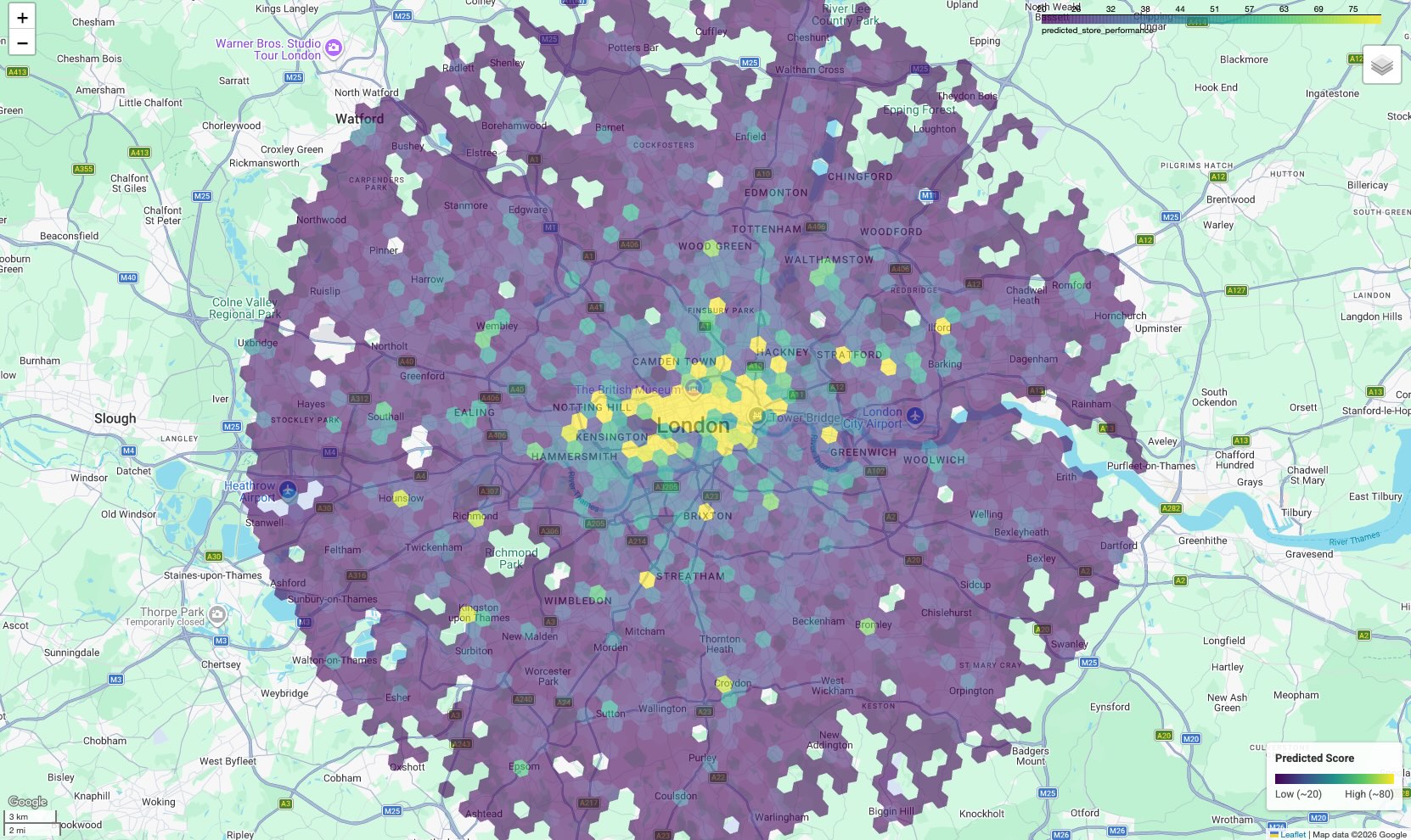
อ่านแผนที่:
- ฮอตสปอต (สีเหลือง/เขียว): พื้นที่เหล่านี้มีคะแนนประสิทธิภาพที่คาดการณ์ไว้สูง โดยมีโรงเรียน ยิม และระบบขนส่งที่มีความหนาแน่นเหมาะสม ซึ่ง สอดคล้องกับสถานที่ตั้งที่ประสบความสำเร็จ ซึ่งเป็นตัวเลือกที่ยอดเยี่ยมสำหรับการเลือก สถานที่ใหม่
- จุดที่ประสิทธิภาพต่ำ (สีม่วง): พื้นที่เหล่านี้ไม่มีฟีเจอร์ด้านสิ่งแวดล้อมที่สนับสนุน ซึ่งพบได้ในพื้นที่ที่มีประสิทธิภาพสูงสุด
- การตรวจสอบแบบอินเทอร์แอกทีฟ: ในสภาพแวดล้อมของ Notebook คุณสามารถวางเมาส์เหนือเซลล์ใดก็ได้เพื่อดูจำนวนสิ่งอำนวยความสะดวกที่เฉพาะเจาะจง (เช่น "ยิม: 12") ซึ่งมีส่วนทำให้เกิดคะแนนที่เฉพาะเจาะจงนั้น
บทสรุป
คุณรวมข้อมูลการดำเนินงานภายในกับข้อมูลเชิงลึกเกี่ยวกับสถานที่เรียบร้อยแล้วเพื่อวินิจฉัยประสิทธิภาพของเว็บไซต์ การวิเคราะห์น้ำหนักของโมเดลช่วยให้คุณระบุลักษณะเฉพาะของย่านที่สัมพันธ์กับเมตริกที่มีอยู่ได้ การใช้การจัดทำดัชนีเชิงพื้นที่ H3 ช่วยให้คุณขยายการวิเคราะห์นี้จากเว็บไซต์ 2-300 แห่งเป็นย่านที่มีศักยภาพหลายพันแห่งทั่วลอนดอน
การดำเนินการถัดไป
- ขยาย Feature Engineering: เพิ่มประเภทสถานที่ที่เฉพาะเจาะจงมากขึ้น ลงในคำค้นหา เพื่อดึงดูดการเข้าชมหน้าร้านจริงเฉพาะกลุ่ม
- สํารวจโมเดลขั้นสูง: แม้ว่าการถดถอยเชิงเส้นจะให้ความสามารถในการอธิบายที่ชัดเจน แต่ให้ทดลองใช้
BOOSTED_TREE_REGRESSORใน BigQuery ML ร่วมกับกลยุทธ์การตรวจสอบแบบไขว้ที่เหมาะสมเพื่อจับความสัมพันธ์ที่ไม่ใช่เชิงเส้น - นำแผนที่ไปใช้จริง: ส่งออกผลลัพธ์ของตารางกริด H3 ไปยังแดชบอร์ดที่กำหนดเอง โดยใช้ Maps JavaScript API เพื่อแชร์ ข้อมูลเชิงลึกเหล่านี้กับทีม
ผู้ร่วมให้ข้อมูล
- Henrik Valve | วิศวกร DevX
- Gennadii Donchyts | วิศวกรลูกค้าอาวุโส