

ऐसा क्यों होता है कि एक साइट अच्छा परफ़ॉर्म करती है, जबकि दूसरी साइट अच्छा परफ़ॉर्म नहीं करती है. भले ही, दोनों साइटों पर स्टाफ़, इन्वेंट्री, और ऑपरेशन से जुड़ी प्रोसेस एक जैसी हों? एक से ज़्यादा जगहों पर मौजूद कारोबारों को अक्सर, अपने पोर्टफ़ोलियो में परफ़ॉर्मेंस में अंतर के बारे में बताने में मुश्किल होती है. जवाब आम तौर पर बाहरी माहौल में छिपा होता है. दिलचस्पी वाली जगहों (पीओआई) के डेटा का इस्तेमाल करके, हम अनुमानित जानकारी से आगे बढ़कर यह पता लगा सकते हैं कि किसी साइट की सफलता के लिए, स्थानीय प्रतिस्पर्धा और आस-पास के इलाके की विशेषताएं कितनी अहम होती हैं.
इस गाइड में बताया गया है कि Places Insights और BigQuery ML का इस्तेमाल करके, किसी साइट की सफलता पर आस-पास के इलाके का असर कैसे मापा जाता है. आपको अपनी साइट की परफ़ॉर्मेंस के डेटा को बाहरी जियोस्पेशल सिग्नल के साथ जोड़ना होगा, ताकि परफ़ॉर्मेंस को बेहतर बनाने वाले फ़ैक्टर का पता लगाया जा सके.
हम लंदन की साइटों के डेटासेट का इस्तेमाल करके, लीनियर रिग्रेशन मॉडल बनाएंगे. इस वर्कफ़्लो में H3 Spatial Indexing का इस्तेमाल किया जाता है. यह सिस्टम, शहर को एक जैसे षट्कोणीय सेल में बांटता है. इन सेल में पर्यावरण से जुड़े डेटा को इकट्ठा करके, किसी मॉडल को ट्रेनिंग दी जा सकती है. इससे शहर के किसी भी इलाके की परफ़ॉर्मेंस का अनुमान लगाया जा सकता है. ऐसा सिर्फ़ आपकी मौजूदा साइटों के लिए नहीं किया जा सकता.
आपको इनके बारे में जानकारी मिलेगी:
- इंजीनियरिंग से जुड़ी सुविधाएं: आपकी साइटों के 500 मीटर के दायरे में मौजूद दिलचस्पी की जगहों (पीओआई) की कुल संख्या. जैसे, जिम, स्कूल, और बस/मेट्रो स्टेशन.
- मॉडल को ट्रेन करें: BigQuery ML का इस्तेमाल करके, रिग्रेशन मॉडल बनाएं. यह मॉडल, परफ़ॉर्मेंस से जुड़ी इन सुविधाओं को आपकी परफ़ॉर्मेंस की इंटरनल मेट्रिक से जोड़ता है.
- शहर के हिसाब से स्कोर करना: लंदन के पूरे H3 ग्रिड पर ट्रेन किए गए मॉडल को लागू करें, ताकि आने वाले समय में कारोबार बढ़ाने के लिए ज़्यादा संभावना वाले हॉटस्पॉट की पहचान की जा सके.
अगर BigQuery ML आपके लिए नया है, तो BigQuery ML के बारे में जानकारी लेख पढ़ें. इससे आपको मुख्य कॉन्सेप्ट और काम करने वाले मॉडल टाइप के बारे में जानने में मदद मिलेगी.
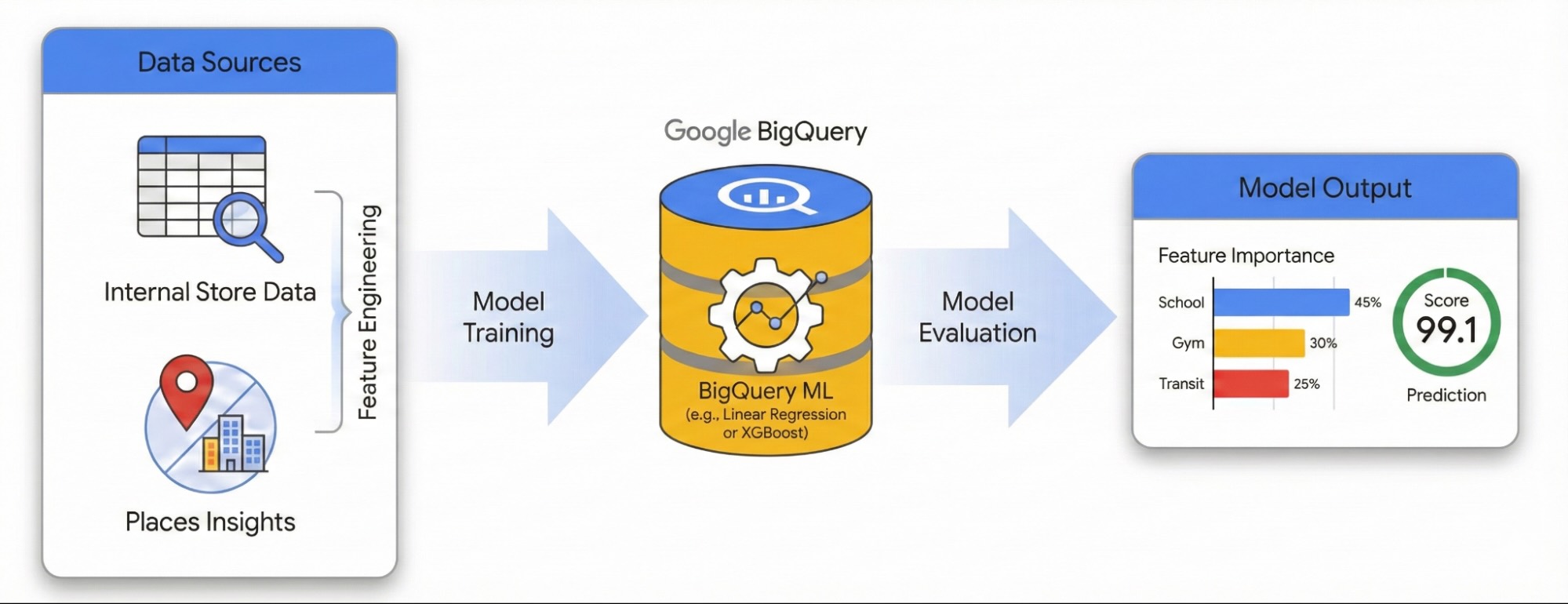
इंटरैक्टिव एनवायरमेंट में इस वर्कफ़्लो को एक्सप्लोर करने के लिए, यहां दिया गया नोटबुक चलाएं. इसमें बताया गया है कि BigQuery ML की मदद से अनुमान लगाने वाला मॉडल कैसे बनाया जाता है. साथ ही, H3 स्पैटियल इंडेक्सिंग का इस्तेमाल करके, पूरे शहर में मौजूद अवसरों को कैसे विज़ुअलाइज़ किया जाता है.
 GitHub पर सोर्स देखें
GitHub पर सोर्स देखें
ज़रूरी शर्तें
शुरू करने से पहले, पक्का करें कि आपके पास ये चीज़ें हों:
Google Cloud प्रोजेक्ट:
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
डेटा ऐक्सेस:
- BigQuery में Places Insights की सदस्यता.
- साइट की जगहों की अपनी टेबल, जिसमें परफ़ॉर्मेंस मेट्रिक (जैसे, रेवेन्यू) शामिल हो. उदाहरण के लिए, डेटासेट ट्यूटोरियल संसाधन में मौजूद है.
Google Maps Platform:
- एक एपीआई पासकोड.
- आपकी कुंजी के लिए ये एपीआई चालू किए गए हैं:
Python एनवायरमेंट और लाइब्रेरी:
- Google Cloud Console में Colab Enterprise जैसा Python एनवायरमेंट.
- ये लाइब्रेरी इंस्टॉल की गई हैं:
लाइब्रेरी ब्यौरा pandas-gbqBigQuery के साथ इंटरैक्ट करना. geopandasजियोस्पेशल डेटा से जुड़ी कार्रवाइयों को मैनेज करना. foliumइंटरैक्टिव मैप बनाना. shapelyज्यामितीय बदलाव.
IAM अनुमतियां:
- पक्का करें कि आपके उपयोगकर्ता या सेवा खाते के पास ये IAM
भूमिकाएं हों:
भूमिका आईडी BigQuery डेटा एडिटर roles/bigquery.dataEditorBigQuery यूज़र roles/bigquery.user
- पक्का करें कि आपके उपयोगकर्ता या सेवा खाते के पास ये IAM
भूमिकाएं हों:
लागत के बारे में जानकारी:
- इस ट्यूटोरियल में, बिल किए जाने वाले Google Cloud कॉम्पोनेंट का इस्तेमाल किया गया है. इनसे जुड़े संभावित खर्चों के बारे में जानें:
- BigQuery ML: इस्तेमाल किए गए कंप्यूट स्लॉट के लिए शुल्क लिया जाता है. BigQuery ML की कीमत देखें.
- Places Insights: क्वेरी के इस्तेमाल के आधार पर शुल्क लिया जाता है.
- इस ट्यूटोरियल में, बिल किए जाने वाले Google Cloud कॉम्पोनेंट का इस्तेमाल किया गया है. इनसे जुड़े संभावित खर्चों के बारे में जानें:
Places Insights की मदद से फ़ीचर इंजीनियरिंग
साइट की परफ़ॉर्मेंस पर असर डालने वाले बाहरी फ़ैक्टर का पता लगाने के लिए, आपको रॉ पीओएस डेटा को मेज़र की जा सकने वाली सुविधाओं में बदलना होगा. आपको हर साइट के 500 मीटर के दायरे में मौजूद, खास सुविधाओं या जगहों के घनत्व का हिसाब लगाना होगा. जैसे, जिम, स्कूल, और ट्रांज़िट स्टेशन. चुनी गई सुविधाएं इस बात पर निर्भर करेंगी कि आपको अपने कारोबार के लिए कौनसी सुविधाएं सबसे ज़्यादा काम की लगती हैं.
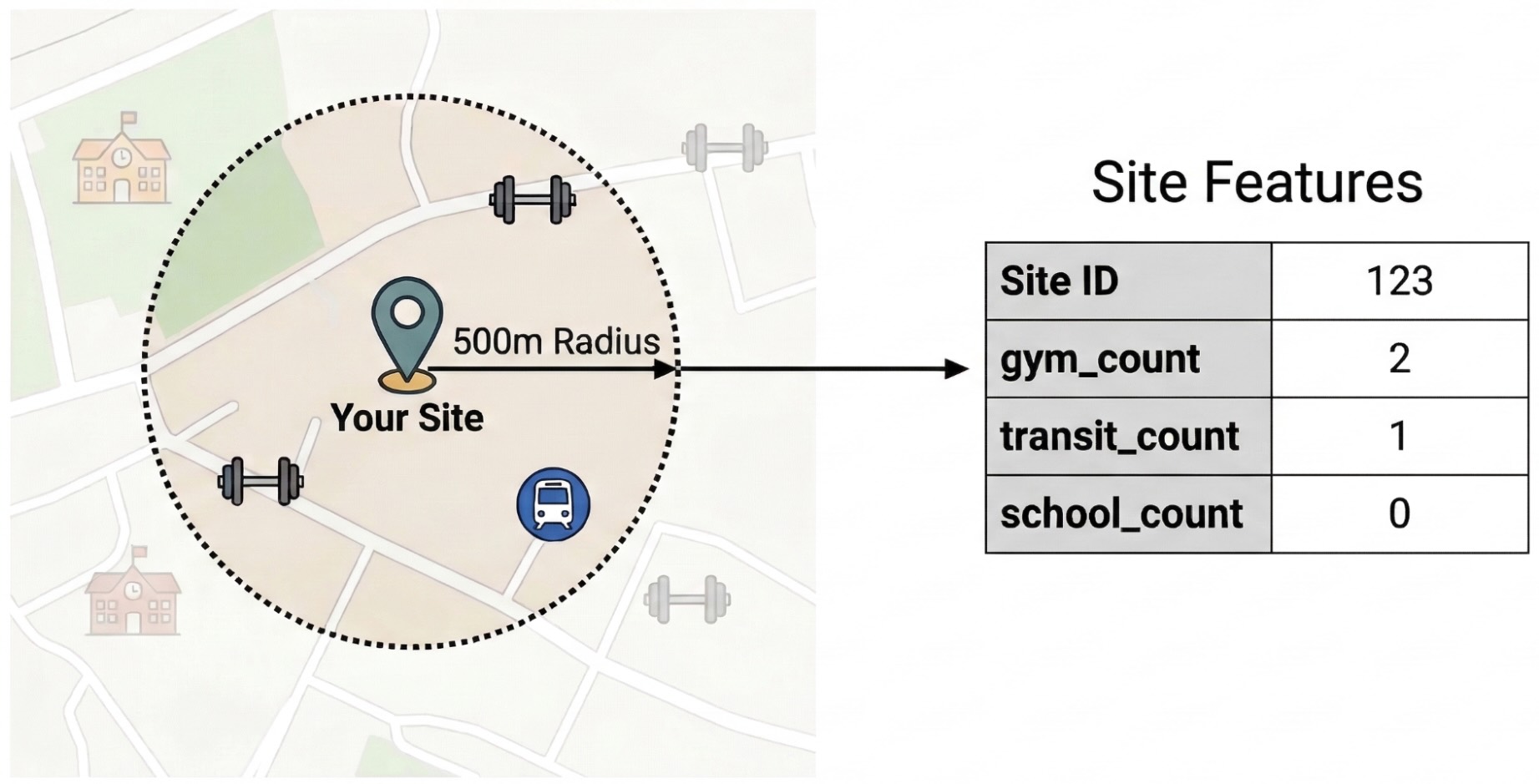
इस चरण के लिए, हम Python और pandas-gbq लाइब्रेरी का इस्तेमाल करते हैं. इस तरीके से, SELECT WITH AGGREGATION_THRESHOLD क्वेरी को लागू किया जा सकता है. Places Insights डेटासेट को ऐक्सेस करने के लिए, यह क्वेरी ज़रूरी है. साथ ही, नतीजों को अपने प्रोजेक्ट की नई टेबल में सेव किया जा सकता है. Places Insights के डेटा के साथ काम करने के बारे में ज़्यादा जानने के लिए, डेटासेट को सीधे तौर पर क्वेरी करना लेख पढ़ें.
फ़ीचर इंजीनियरिंग क्वेरी चलाना
अपने एनवायरमेंट (जैसे, Colab Enterprise) में यहां दी गई Python स्क्रिप्ट चलाएं. यह स्क्रिप्ट, आपकी साइट के इंटरनल डेटा को जगहों की अहम जानकारी वाले डेटासेट से कनेक्ट करती है.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
क्वेरी को समझना
ST_DWITHIN: यह जियोस्पेशियल फ़ंक्शन, हर साइट की जगह के आस-पास 500 मीटर का बफ़र बनाता है. साथ ही, उन सभी जगहों की अहम जानकारी वाले पॉइंट की पहचान करता है जो उस दायरे में आते हैं.COUNTIF: यह फ़ंक्शन, हर साइट के लिए किसी खास जगह के टाइप (जैसे, 'जिम', 'स्कूल') की डेंसिटी का हिसाब लगाता है. ये संख्याएं, मशीन लर्निंग मॉडल के लिए इनपुट फ़ीचर (X) बन जाती हैं.pandas_gbq.to_gbq: यह फ़ंक्शन, क्वेरी के नतीजों को नई टेबल (site_features) में सेव करता है. यह परमानेंट टेबल, BigQuery ML मॉडल के लिए साफ़-सुथरे ट्रेनिंग डेटासेट के तौर पर काम करती है.
ज़्यादा बेहतर तरीके से रीयल-वर्ल्ड ऐप्लिकेशन इस्तेमाल करने के लिए, अलग-अलग दूरी (जैसे, 250 मीटर, 500 मीटर, 1 किलोमीटर) पर सुविधाओं का हिसाब लगाएं.साथ ही, Places Insights के अन्य एट्रिब्यूट एक्सप्लोर करें. जैसे, rating, price_level या regular_opening_hours. जगह की अहम जानकारी के एट्रिब्यूट की पूरी सूची देखने के लिए, जगह के टाइप और कोर स्कीमा रेफ़रंस देखें.
BigQuery ML की मदद से मॉडल को ट्रेन करना
site_features टेबल में सेव की गई, इंजीनियरिंग की गई सुविधाओं की मदद से, अब लीनियर रिग्रेशन मॉडल को ट्रेन किया जा सकता है.
यह मॉडल, आपकी साइट की परफ़ॉर्मेंस (Y) का अनुमान लगाने के लिए, हर एनवायरमेंटल फ़ीचर (X) के लिए सबसे सही वेट (β) का पता लगाता है.
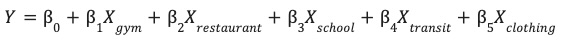
रोबस्ट स्केलिंग की मदद से, आउटलायर को मैनेज करना
जियोस्पेशल डेटा में अक्सर ऐसे आउटलायर शामिल होते हैं जो स्टैंडर्ड लीनियर मॉडल को खराब कर सकते हैं. उदाहरण के लिए, लंदन के वेस्ट एंड में मौजूद किसी साइट के 500 मीटर के दायरे में 200 रेस्टोरेंट हो सकते हैं. वहीं, शहर के बाहरी इलाके में मौजूद किसी साइट के 500 मीटर के दायरे में सिर्फ़ दो रेस्टोरेंट हो सकते हैं. स्टैंडर्ड स्केलिंग (औसत/स्टैंडर्ड डेविएशन) का इस्तेमाल करने पर, आउटलायर (200) डिस्ट्रिब्यूशन को बदल देता है. साथ ही, मॉडल को उस एक्सट्रीम वैल्यू को प्राथमिकता देने के लिए मजबूर करता है.
इस समस्या को हल करने के लिए, हम मॉडल की परिभाषा में रोबस्ट स्केलिंग (ML.ROBUST_SCALER) का इस्तेमाल करते हैं. इस तकनीक में, मीडियन और इंटरक्वार्टाइल रेंज (आईक्यूआर) के आधार पर सुविधाओं को स्केल किया जाता है. इससे मॉडल, आउटलायर के लिए ज़्यादा बेहतर हो जाता है. साथ ही, यह पक्का किया जाता है कि मॉडल आपकी साइटों के सामान्य डिस्ट्रिब्यूशन से सीखे.
मॉडल बनाना
मॉडल बनाने और उसे ट्रेन करने के लिए, BigQuery में यह SQL क्वेरी चलाएं.
हम सभी इनपुट सुविधाओं पर बेहतर स्केलिंग लागू करने के लिए, TRANSFORM क्लॉज़ का इस्तेमाल करते हैं. हम optimize_strategy = 'NORMAL_EQUATION' भी सेट करते हैं, क्योंकि यह छोटे डेटासेट के लिए ट्रेनिंग का सबसे असरदार तरीका है. जैसे, स्टोर की जगहों का सामान्य पोर्टफ़ोलियो. आखिर में, हम बेहतर परफ़ॉर्म करने वाले आउटलायर (store_performance <
75) को फ़िल्टर कर देते हैं, ताकि मॉडल सामान्य ग्रोथ पैटर्न का अनुमान लगाने पर फ़ोकस कर सके.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
मॉडल की परफ़ॉर्मेंस का आकलन करना
साइट की परफ़ॉर्मेंस को बेहतर बनाने वाले फ़ैक्टर के बारे में मॉडल की अहम जानकारी पर भरोसा करने से पहले, आपको यह पुष्टि करनी होगी कि मॉडल के अनुमान सटीक हैं.
ट्रेनिंग के बाद, ML.EVALUATE फ़ंक्शन का इस्तेमाल करके, मॉडल के अनुमानों का आकलन करें. इसके लिए, "होल्डआउट" डेटा सेट का इस्तेमाल करें. इस डेटा सेट का इस्तेमाल ट्रेनिंग के दौरान नहीं किया गया था.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
R2 स्कोर
(r2_score) और औसत निरपेक्ष त्रुटि
(mean_absolute_error) की जांच करके पता लगाएं कि आपका मॉडल प्रोडक्शन के लिए तैयार है या नहीं:
- R2 स्कोर से यह पता चलता है कि परफ़ॉर्मेंस में बदलाव की कितनी वजहें, बाहरी पर्यावरणीय कारकों (आस-पास के पीओएस) से जुड़ी हैं. R2 स्कोर 0.70 का मतलब है कि किसी साइट की 70% सफलता, स्थानीय माहौल से जुड़ी है. यह स्कोर 1.0 के जितना करीब होगा, पर्यावरण से जुड़ी सुविधाओं और साइट की परफ़ॉर्मेंस के बीच का संबंध उतना ही मज़बूत होगा.
- MAE से आपको पॉइंट में औसत गड़बड़ी के बारे में पता चलता है. उदाहरण के लिए, 1.5 के MAE का मतलब है कि मॉडल के अनुमान, आम तौर पर परफ़ॉर्मेंस के असल स्कोर से +/- 1.5 पॉइंट के बीच होते हैं.
कम स्कोर की समस्या हल करना
अगर आपका R2 स्कोर कम है, तो इन सुधारों को लागू करें:
- सुविधा के टाइप बढ़ाएं: अपनी क्वेरी में अलग-अलग जगह के टाइप जोड़ें. जैसे,
tourist_attraction,subway_station. - कैचमेंट रेडियस में बदलाव करना:
ST_DWITHINदूरी में बदलाव करें. कॉफ़ी शॉप के लिए 500 मीटर का दायरा बहुत बड़ा हो सकता है, लेकिन फ़र्नीचर की दुकान के लिए यह बहुत छोटा हो सकता है. - डेटा का साइज़ बढ़ाएं: पक्का करें कि आंकड़ों के हिसाब से अहम पैटर्न ढूंढने के लिए, स्टोर की काफ़ी जगहों के डेटा का इस्तेमाल किया जा रहा हो.
H3 स्पैटियल इंडेक्सिंग की मदद से शहर को स्कोर करना
हम H3 स्पैटियल इंडेक्सिंग का इस्तेमाल करके, लंदन शहर को हेक्सागोनल सेल (रिज़ॉल्यूशन 8, करीब 0.7 कि॰मी॰²) के एक जैसे ग्रिड में बांटते हैं. इन सेल में Places Insights का डेटा इकट्ठा करके, हम अपने ट्रेनिंग मॉडल को हर मोहल्ले पर लागू कर सकते हैं. इससे हमें उन इलाकों की पहचान करने में मदद मिलती है जिनमें आपके सबसे अच्छा परफ़ॉर्म करने वाले साइटों की एनवायरमेंटल प्रोफ़ाइल से मेल खाने की ज़्यादा संभावना होती है.
संभावित ग्राहकों को टारगेट करने वाली क्वेरी चलाना
इस ग्रिड को जनरेट करने के लिए, हम Places Insights डेटासेट से मिले PLACES_COUNT_PER_H3 फ़ंक्शन का इस्तेमाल करते हैं. Places Count फ़ंक्शन का इस्तेमाल करके, Places Insights को क्वेरी करने के बारे में ज़्यादा जानें.
यह फ़ंक्शन, एक ही ऑपरेशन में H3 ग्रिड सेल के लिए पीओआई की गिनती करता है.
एक ही बार में तीन चरणों को पूरा करने के लिए, यह एसक्यूएल क्वेरी चलाएं:
- H3 इंडेक्सिंग और गिनती: हम JSON कॉन्फ़िगरेशन ऑब्जेक्ट का इस्तेमाल करके
PLACES_COUNT_PER_H3को कॉल करते हैं, ताकि सेंट्रल लंदन के 25 कि॰मी॰ के दायरे में मौजूद सभी जगहों का पता लगाया जा सके. हम हर तरह की सुविधा (जिम, स्कूल वगैरह) के लिए, इस क्वेरी को अलग-अलग करते हैं. इसके बाद,UNION ALLका इस्तेमाल करके, इन क्वेरी को एक साथ जोड़ते हैं. - पिवटिंग (फ़ीचर इंजीनियरिंग): हमारा मशीन लर्निंग मॉडल, अलग-अलग फ़ीचर कॉलम (जैसे कि
gym_countऔरrestaurant_count) का इस्तेमाल करता है. इसलिए, हम सेल को ग्रुप करते हैं और डेटा को सही स्कीमा में पिवट करने के लिए, शर्त के साथ एग्रीगेशन(SUM(IF(...)))का इस्तेमाल करते हैं. - अनुमान: हम इन पिवट की गई ग्रिड सुविधाओं को सीधे
ML.PREDICTफ़ंक्शन में फ़ीड करते हैं, ताकि हर मोहल्ले के लिए परफ़ॉर्मेंस स्कोर जनरेट किया जा सके.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
नतीजों को समझना
क्वेरी, एक ऐसी टेबल दिखाती है जिसमें हर लाइन, लंदन के हेक्सागोनल एरिया को दिखाती है.
h3_index: यह हेक्सागोनल सेल का यूनीक आइडेंटिफ़ायर होता है.predicted_store_performance: इस सेल में मौजूद किसी साइट के लिए मॉडल का अनुमानित स्कोर. यह स्कोर सिर्फ़ आस-पास के माहौल के आधार पर तय किया जाता है.h3_geography: सेल की पॉलीगॉन ज्यामिति. इसका इस्तेमाल हम अगले चरण में विज़ुअलाइज़ेशन के लिए करेंगे.
ज़्यादा वैल्यू का मतलब है कि उन इलाकों में स्कूल, जिम, और ट्रांज़िट की डेंसिटी, आपकी सबसे सफल मौजूदा साइटों के आस-पास मौजूद पैटर्न से मेल खाती है.
संभावित ग्राहकों को टारगेट करने वाले मैप को विज़ुअलाइज़ करना
डेटा को कार्रवाई में बदलने के लिए, नतीजों को मैप पर दिखाएं. टेबल के फ़ॉर्मैट में मिले आउटपुट में रॉ स्कोर मिलते हैं. वहीं, मैप से ज़्यादा संभावना वाले स्पैटियल क्लस्टर और कॉरिडोर का पता चलता है. ये जानकारी, सूची में साफ़ तौर पर नहीं दिखती.
साथ में दी गई नोटबुक में, हमने H3 पॉलीगॉन ज्यामिति को पार्स करने के लिए geopandas लाइब्रेरी का इस्तेमाल किया है. साथ ही, इंटरैक्टिव मैप रेंडर करने के लिए folium का इस्तेमाल किया है.
नतीजा, कोरोप्लेथ मैप के तौर पर दिखता है. इसमें हर षट्कोणीय सेल को उसके अनुमानित स्कोर के हिसाब से रंग दिया जाता है.
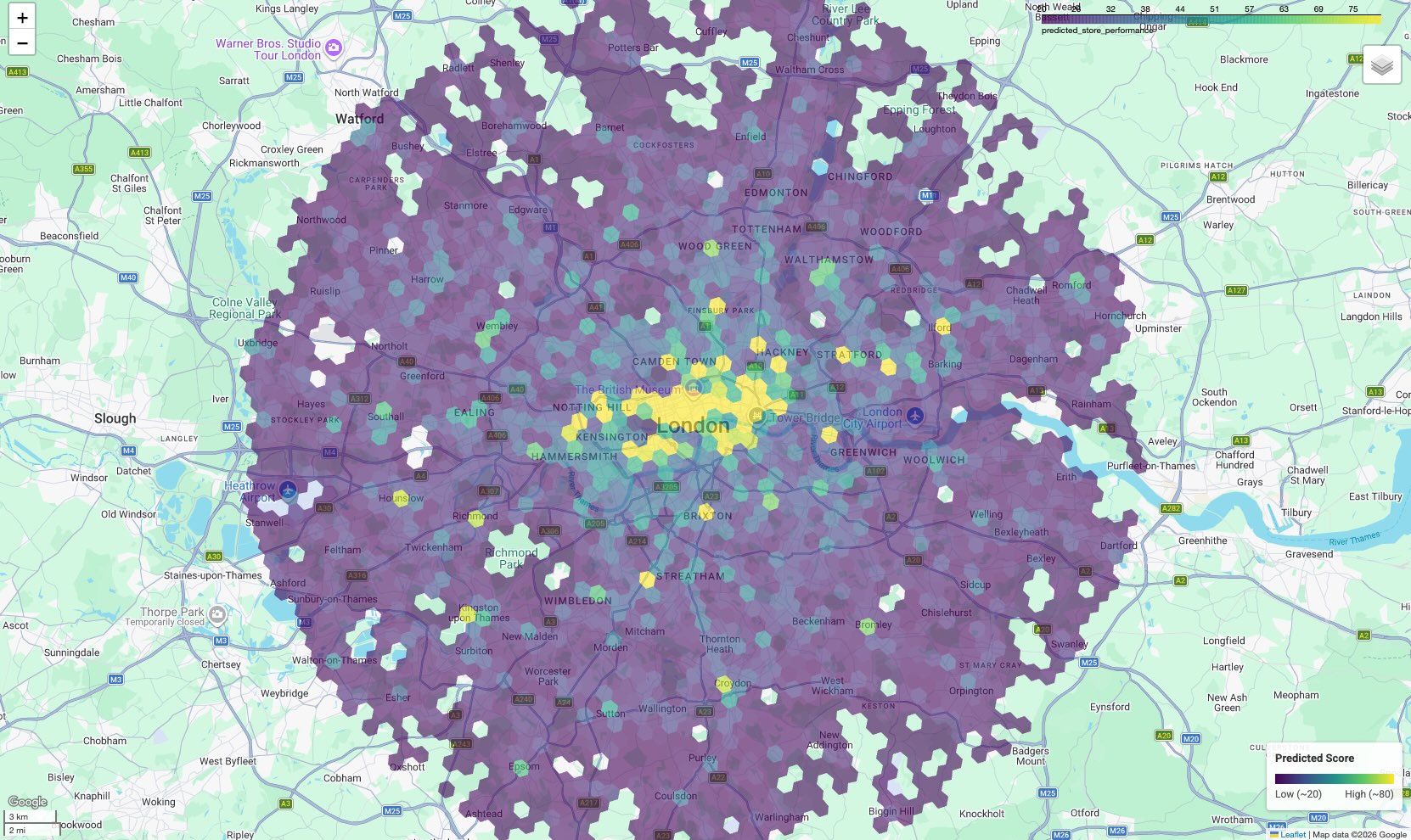
मैप को समझना:
- हॉटस्पॉट (पीला/हरा): इन इलाकों में परफ़ॉर्मेंस के अनुमानित स्कोर ज़्यादा होते हैं. इनमें स्कूलों, जिम, और ट्रांज़िट की सबसे ज़्यादा डेंसिटी होती है. यह आपकी सफल साइटों से जुड़ी होती है. ये नई साइट चुनने के लिए सबसे अच्छे विकल्प हैं.
- कोल्डस्पॉट (बैंगनी): इन इलाकों में, आपके सबसे अच्छा परफ़ॉर्म करने वाले प्रॉडक्ट के आस-पास मौजूद पर्यावरण से जुड़ी सुविधाओं की कमी होती है.
- इंटरैक्टिव जांच: नोटबुक एनवायरमेंट में, किसी भी सेल पर कर्सर घुमाकर सुविधाओं की खास संख्या देखी जा सकती है.उदाहरण के लिए, "जिम: 12". इससे यह पता चलता है कि किस सुविधा की वजह से स्कोर बढ़ा है.
नतीजा
आपने साइट की परफ़ॉर्मेंस का पता लगाने के लिए, इंटरनल ऑपरेशनल डेटा को Places Insights के साथ जोड़ दिया है. मॉडल के वेट का विश्लेषण करके, आपने आस-पास के इलाके की उन खास विशेषताओं की पहचान की है जो आपकी मौजूदा मेट्रिक से जुड़ी हैं. आपने H3 स्पैटियल इंडेक्सिंग का इस्तेमाल करके, इस विश्लेषण को कुछ सौ साइटों से बढ़ाकर लंदन के हज़ारों संभावित इलाकों तक पहुंचाया.
अगली कार्रवाइयां
- फ़ीचर इंजीनियरिंग को बेहतर बनाएं: अपनी क्वेरी में ज़्यादा सटीक जगह के टाइप जोड़ें, ताकि पैदल आने वाले लोगों की संख्या बढ़ाने वाले खास ड्राइवर को कैप्चर किया जा सके.
- ऐडवांस मॉडल एक्सप्लोर करें: लीनियर रिग्रेशन से साफ़ तौर पर जानकारी मिलती है. हालांकि, नॉन-लीनियर रिलेशनशिप कैप्चर करने के लिए, BigQuery ML में
BOOSTED_TREE_REGRESSORका इस्तेमाल करें. साथ ही, क्रॉस-वैलिडेशन की सही रणनीति अपनाएं. - मैप का इस्तेमाल करना: H3 ग्रिड के नतीजों को Maps JavaScript API का इस्तेमाल करके, अपनी पसंद के मुताबिक बनाए गए डैशबोर्ड में एक्सपोर्ट करें, ताकि इन अहम जानकारी को अपनी टीम के साथ शेयर किया जा सके.
योगदानकर्ता
- हेनरिक वॉल्व | DevX इंजीनियर
- गेनाडी डोंचिट्स | स्टाफ़ कस्टमर इंजीनियर