

למה אתר אחד מצליח ואתר אחר לא, למרות ששניהם נהנים מאותם תנאים מבחינת כוח אדם, מלאי ושיטות הפעלה? לעסקים עם כמה מיקומים קשה להסביר את השונות בביצועים בין המיקומים. התשובה בדרך כלל חבויה בסביבה החיצונית. בעזרת נתונים של נקודות עניין (POI), אנחנו יכולים לצאת מההסברים האנקדוטליים ולכמת בדיוק את מידת ההשפעה של צפיפות התחרות המקומית ומאפייני השכונה על הצלחת האתר.
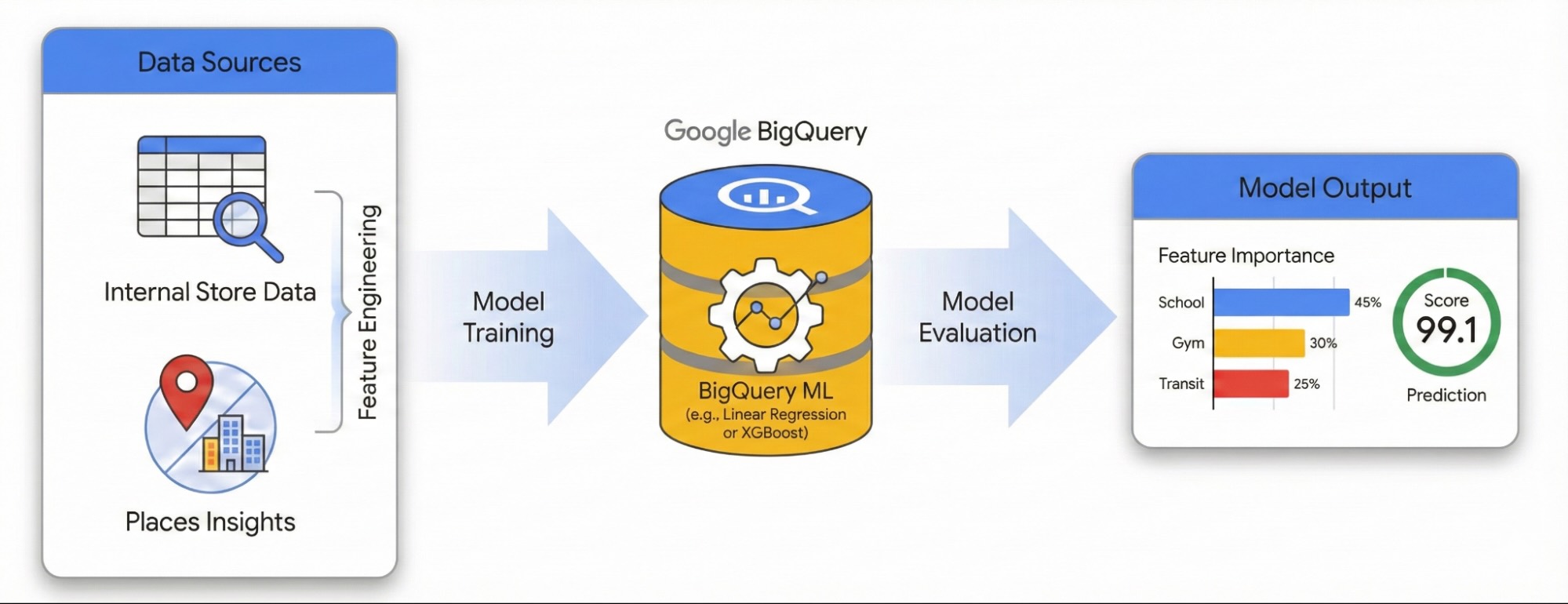
במדריך הזה נסביר איך לכמת את ההשפעה של הסביבה המקומית על הצלחת האתר באמצעות Places Insights ו-BigQuery ML. תשלבו את נתוני ביצועי האתר הקנייניים שלכם עם אותות גיאוגרפיים חיצוניים כדי לאבחן את הגורמים שמשפיעים על הביצועים.
נשתמש במערך נתונים של אתרים בלונדון כדי ליצור מודל רגרסיה לינארית. בתהליך העבודה הזה נעשה שימוש באינדוקס מרחבי H3. המערכת הזו מחלקת את העיר לתאים משושים אחידים. על ידי צבירה של נתונים סביבתיים בתאים האלה, אפשר לאמן מודל שינבא את פוטנציאל הביצועים של כל שכונה בעיר, לא רק של האתרים הקיימים שלכם.
תלמדו:
- תכונות הנדסיות: ספירה מצטברת של נקודות עניין (POI) כמו מכוני כושר, בתי ספר ותחנות תחבורה ציבורית ברדיוס של 500 מטר מהאתרים שלכם.
- אימון מודל: משתמשים ב-BigQuery ML כדי ליצור מודל רגרסיה שמתאם בין הפיצ'רים הסביבתיים האלה לבין מדדי הביצועים הפנימיים.
- דירוג העיר: החלת המודל שאומן על כל רשת H3 של לונדון כדי לזהות אזורים חמים עם פוטנציאל גבוה להתרחבות עתידית.
משתמשים מתחילים ב-BigQuery ML יכולים לקרוא את המבוא ל-BigQuery ML כדי להבין את מושגי הליבה ואת סוגי המודלים הנתמכים.
כדי לנסות את תהליך העבודה הזה בסביבה אינטראקטיבית, מריצים את ה-notebook הבא. ב-Codelab הזה נדגים איך ליצור מודל חיזוי באמצעות BigQuery ML ואיך להציג הזדמנויות ברחבי העיר באמצעות אינדקס מרחבי H3.
 הצגת המקור ב-GitHub
הצגת המקור ב-GitHub
דרישות מוקדמות
לפני שמתחילים, חשוב לוודא שיש לכם:
פרויקט Google Cloud:
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
גישה לנתונים:
- מינוי ל-Places Insights ב-BigQuery.
- טבלה משלכם עם מיקומי האתר ומדד לבדיקת ביצועים (למשל, הכנסות). מערך נתונים לדוגמה נמצא במשאבי ההדרכה.
Google Maps Platform:
- מפתח API.
- ממשקי ה-API הבאים מופעלים עבור המפתח:
סביבת Python וספריות:
- סביבת Python, כמו Colab Enterprise במסוף Google Cloud.
- הספריות הבאות הותקנו:
ספרייה תיאור pandas-gbqאינטראקציה עם BigQuery. geopandasטיפול בפעולות על נתונים גיאו-מרחביים. foliumיצירת מפות אינטראקטיביות. shapelyמניפולציות גיאומטריות.
הרשאות IAM:
- מוודאים שלמשתמש או לחשבון השירות יש את תפקידי ה-IAM הבאים:
תפקיד מזהה עריכה של נתוני BigQuery roles/bigquery.dataEditorמשתמש BigQuery roles/bigquery.user
- מוודאים שלמשתמש או לחשבון השירות יש את תפקידי ה-IAM הבאים:
הבנת העלויות:
- במדריך הזה נעשה שימוש ברכיבים של Google Cloud שחלים עליהם חיובים. חשוב להכיר את העלויות האפשריות שקשורות ל:
- BigQuery ML: תשלום על משבצות מחשוב שנעשה בהן שימוש. מחירון BigQuery ML
- Places Insights: החיוב מתבצע על סמך השימוש בשאילתות.
- במדריך הזה נעשה שימוש ברכיבים של Google Cloud שחלים עליהם חיובים. חשוב להכיר את העלויות האפשריות שקשורות ל:
הנדסת פיצ'רים (feature engineering) באמצעות Places Insights
כדי לבודד את הגורמים החיצוניים שמשפיעים על ביצועי האתר, צריך להפוך נתונים גולמיים של נקודות עניין לתכונות שניתנות לכימות. תחשבו את הצפיפות של שירותי המלון ספציפיים או סוגים של מקומות כמו מכוני כושר, בתי ספר ותחנה של תחבורה ציבורית ברדיוס של 500 מטרים מכל אתר. השירותים שתבחרו יהיו תלויים במה שלדעתכם הכי רלוונטי לעסק שלכם.
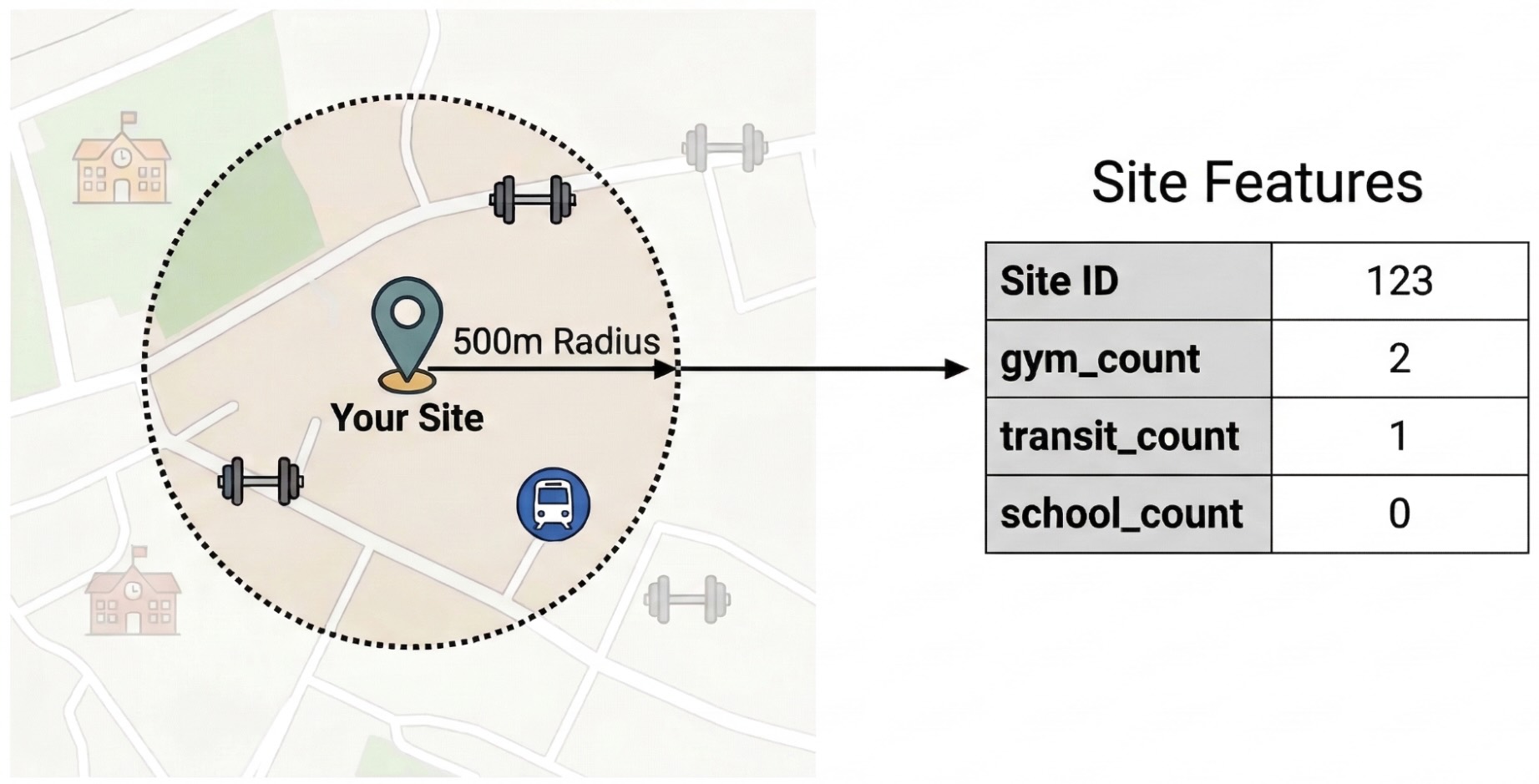
אנחנו משתמשים ב-Python ובספרייה pandas-gbq בשלב הזה. הגישה הזו מאפשרת לכם להריץ את שאילתת SELECT WITH AGGREGATION_THRESHOLD, שנדרשת כדי לגשת למערך הנתונים של Places Insights, ולשמור את התוצאות בטבלה חדשה בפרויקט. מידע נוסף על עבודה עם נתונים של Places Insights זמין במאמר בנושא הרצת שאילתה ישירות במערך הנתונים.
הרצת שאילתת הנדסת הפיצ'רים
מריצים את סקריפט Python הבא בסביבה שלכם (לדוגמה, Colab Enterprise). הסקריפט הזה מקשר בין נתוני האתר הפנימיים לבין מערך הנתונים של Places Insights.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
הסבר על השאילתה
ST_DWITHIN: הפונקציה הגיאו-מרחבית הזו יוצרת אזור חיץ ברדיוס של 500 מטרים סביב כל מיקום באתר, ומזהה את כל הנקודות של Places Insights שנמצאות ברדיוס הזה.-
COUNTIF: הפונקציה הזו מחשבת את הצפיפות של סוגים ספציפיים של מקומות (למשל, 'חדר כושר', 'בית ספר') לכל אתר. המספרים האלה הופכים לתכונות הקלט (X) של מודל למידת המכונה. -
pandas_gbq.to_gbq: הפונקציה הזו שומרת את תוצאות השאילתה בטבלה חדשה (site_features). הטבלה הקבועה הזו משמשת כמערך נתונים נקי לאימון המודל של BigQuery ML.
כדי לקבל יישומים מתקדמים יותר בעולם האמיתי, כדאי לחשב תכונות במרחקים שונים (למשל, 250 מ', 500 מ', קילומטר אחד) ולבדוק מאפיינים אחרים של Places Insights, כמו rating, price_level או regular_opening_hours. רשימה מלאה של מאפייני Places Insights זמינה במאמרים בנושא סוגי מקומות נתמכים והפניה לסכימה הבסיסית.
אימון המודל באמצעות BigQuery ML
אחרי ששומרים את התכונות המהונדסות בטבלת site_features, אפשר לאמן מודל Linear
Regression.
המודל לומד את המשקלים האופטימליים (β) של כל תכונה סביבתית (X) כדי לחזות את הביצועים של האתר (Y).
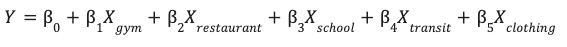
טיפול בערכים חריגים באמצעות שינוי קנה מידה חזק
נתונים גיאוספציאליים מכילים לעיתים קרובות חריגים קיצוניים שיכולים לעוות מודלים לינאריים רגילים. לדוגמה, באתר בווסט אנד בלונדון יכולות להיות 200 מסעדות במרחק של 500 מטרים, בעוד שבאתר בפרברים יש רק 2. אם משתמשים בהתאמה רגילה (ממוצע/סטיית תקן), הערך החריג (200) משפיע על הפיזור ומאלץ את המודל לתת עדיפות להתאמת הערך הקיצוני הזה.
כדי לפתור את הבעיה, אנחנו משתמשים ב-Robust Scaling (ML.ROBUST_SCALER) בהגדרת המודל. בטכניקה הזו משנים את קנה המידה של התכונות על סמך החציון והטווח הבין-רבעוני (IQR), וכך המודל עמיד בפני חריגים ומבטיח שהוא לומד מההתפלגות האופיינית של האתרים שלכם.
יצירת המודל
מריצים את שאילתת ה-SQL הבאה ב-BigQuery כדי ליצור את המודל ולאמן אותו.
אנחנו משתמשים בסעיף
TRANSFORM
כדי להחיל שינוי גודל חזק על כל תכונות הקלט. אנחנו גם מגדירים את
optimize_strategy = 'NORMAL_EQUATION' כי זו שיטת האימון היעילה ביותר למערכי נתונים קטנים יחסית, כמו תיק טיפוסי של מיקומי חנויות. לבסוף, אנחנו מסננים חריגים עם ביצועים גבוהים (store_performance <
75) כדי שהמודל יתמקד בחיזוי דפוסי צמיחה אופייניים.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
הערכת ביצועי המודל
כדי שתוכלו לסמוך על התובנות של המודל לגבי הגורמים שמשפיעים על ביצועי האתר, אתם צריכים לוודא שהתחזיות שלו מדויקות.
אחרי האימון, משתמשים בפונקציה ML.EVALUATE כדי להעריך את התחזיות של המודל בהשוואה לקבוצת נתונים שלא נעשה בה שימוש במהלך האימון.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
כדי לקבוע אם המודל מוכן להעברה לסביבת הייצור, בודקים את ציון R2 (r2_score) ואת השגיאה הממוצעת המוחלטת (mean_absolute_error):
- ציון R2 מודד כמה מהשונות בביצועים מוסברת בפועל על ידי גורמים סביבתיים חיצוניים (נקודות עניין סמוכות). ציון R2 של 0.70 אומר ש-70% מההצלחה של אתר קשורים לסביבה המקומית. ככל שהערך קרוב יותר ל-1.0, כך המתאם בין התנאים הסביבתיים לבין ביצועי האתר חזק יותר.
- השגיאה הממוצעת מציינת את השגיאה הממוצעת בנקודות. לדוגמה, אם שגיאת החיזוי הממוצעת היא 1.5, המשמעות היא שהתחזיות של המודל בדרך כלל חורגות ב-1.5 נקודות לכל היותר מהציון בפועל.
פתרון בעיות שקשורות לציונים נמוכים
אם ציון R2 נמוך, כדאי לשקול את השיפורים הבאים:
- הרחבת סוגי התכונות: מוסיפים סוגי מקומות שונים לשאילתה (לדוגמה,
tourist_attraction,subway_station). - שינוי רדיוס האזור: משנים את המרחק
ST_DWITHIN. רדיוס של 500 מטרים יכול להיות רחב מדי לבית קפה, אבל קטן מדי לחנות רהיטים. - הגדלת כמות הנתונים: חשוב לוודא שאתם מאמנים את המודל על מספיק מיקומי חנויות כדי למצוא דפוס בעל מובהקות סטטיסטית.
דירוג העיר באמצעות אינדקס מרחבי H3
אנחנו משתמשים באינדקס מרחבי H3 כדי לחלק את העיר לונדון לרשת אחידה של תאים משושים (רזולוציה 8, בערך 0.7 קמ"ר). על ידי צבירת נתונים של Places Insights בתאים האלה, אנחנו יכולים להחיל את המודל המאומן שלנו על כל שכונה, ולזהות אזורים עם פוטנציאל גבוה שתואמים לפרופיל הסביבתי של האתרים עם הביצועים הכי טובים.
הרצת השאילתה לחיפוש לקוחות פוטנציאליים
כדי ליצור את הרשת הזו, אנחנו משתמשים בפונקציה PLACES_COUNT_PER_H3 שמופיעה בקבוצת הנתונים Places Insights (מידע נוסף על שליחת שאילתות ב-Places Insights באמצעות פונקציות של ספירת מקומות).
הפונקציה הזו מחשבת את מספר נקודות העניין בתאי רשת H3 בפעולה אחת.
מריצים את שאילתת ה-SQL הבאה כדי לבצע שלושה שלבים בהרצה אחת:
- אינדוקס וספירה של H3: אנחנו קוראים ל-
PLACES_COUNT_PER_H3באמצעות אובייקט תצורת JSON כדי למצוא את כל המקומות שפתוחים לעסקים ברדיוס של 25 ק "מ ממרכז לונדון. אנחנו שולחים שאילתה נפרדת לכל סוג של מתקן (חדרי כושר, בתי ספר וכו') ומשלבים אותם באמצעותUNION ALL. - שינוי ציר (הנדסת תכונות): מכיוון שמודל למידת המכונה שלנו מצפה לעמודות תכונות נפרדות (כמו
gym_countו-restaurant_count), אנחנו מקבצים את התאים ומשתמשים בצבירה מותנית(SUM(IF(...)))כדי לשנות את ציר הנתונים לסכימה הנכונה. - תחזית: אנחנו מזינים את התכונות האלה של הרשת המסתובבת ישירות לפונקציה
ML.PREDICTכדי ליצור ציון ביצועים לכל שכונה.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
פירוש התוצאות
השאילתה מחזירה טבלה שבה כל שורה מייצגת אזור משושה בלונדון.
-
h3_index: המזהה הייחודי של התא המשושה. -
predicted_store_performance: הציון המשוער של המודל לאתר שנמצא בתא הזה, על סמך הסביבה שמסביב בלבד. -
h3_geography: גיאומטריית הפוליגון של התא, שבה נשתמש להדמיה בשלב הבא.
ערכים גבוהים מציינים אזורים שבהם צפיפות בתי הספר, מכוני הכושר והתחבורה הציבורית תואמת לדפוסים שנמצאו סביב האתרים הקיימים הכי מוצלחים שלכם.
תצוגה חזותית של מפת איתור הלקוחות הפוטנציאליים
כדי להפוך את הנתונים לפרקטיים, כדאי להציג את התוצאות במפה. הפלט הטבלאי מספק ציונים גולמיים, אבל מפה חושפת אשכולות מרחביים ומסדרונות של פוטנציאל גבוה שלא ברורים ברשימה.
במחברת הנלווית, אנחנו משתמשים בספרייה geopandas כדי לנתח את הגיאומטריה של מצולע H3 ובספרייה folium כדי לעבד מפה אינטראקטיבית.
התוצאה היא מפה כורופלתית שבה כל תא משושה צבוע בהתאם לניקוד החזוי שלו.
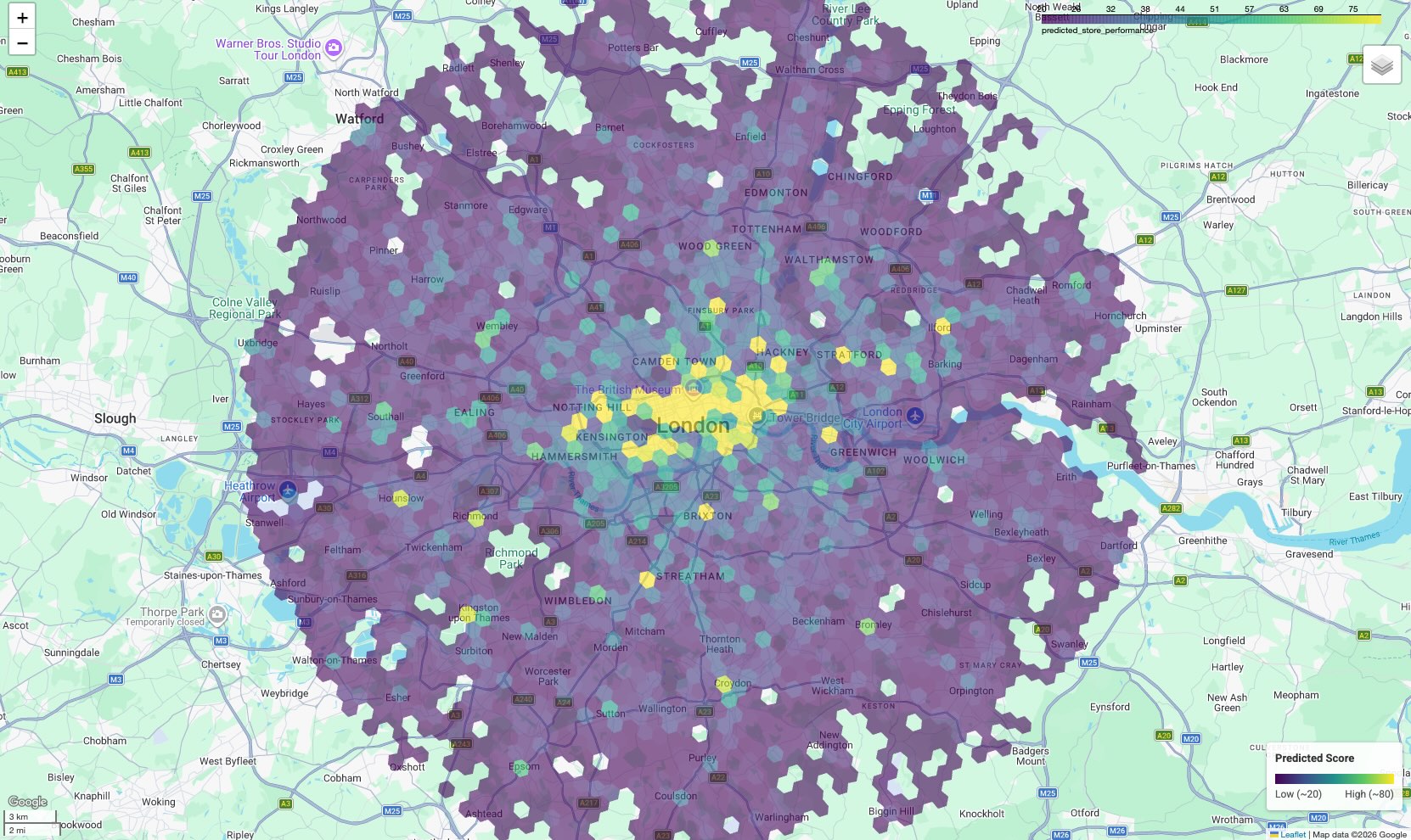
פירוש המפה:
- אזורים חמים (צהוב/ירוק): באזורים האלה צפויים ביצועים גבוהים. יש בהם את הצפיפות האופטימלית של בתי ספר, מכוני כושר ותחבורה ציבורית שמתאימה לאתרים המוצלחים שלכם. אלה מועמדים מצוינים לבחירת אתר חדש.
- אזורים חלשים (סגול): באזורים האלה חסרים מאפיינים סביבתיים תומכים שנמצאים ליד האזורים עם הביצועים הכי טובים.
- בדיקה אינטראקטיבית: בסביבת ה-notebook, אפשר להציב את הסמן מעל כל תא כדי לראות את המספרים הספציפיים של המתקנים (למשל, 'חדרי כושר: 12') שהשפיעו על הציון הספציפי הזה.
סיכום
שילבתם בהצלחה נתונים תפעוליים פנימיים עם Places Insights כדי לאבחן את ביצועי האתר. בעזרת ניתוח המשקלים של המודל, זיהיתם את המאפיינים הספציפיים של השכונה שקשורים למדדים הקיימים שלכם. באמצעות אינדקס מרחבי H3, הרחבתם את הניתוח הזה מכמה מאות אתרים לאלפי שכונות פוטנציאליות ברחבי לונדון.
הפעולות הבאות
- הרחבת הנדסת התכונות: מוסיפים לשאילתה סוגי מקומות ספציפיים יותר כדי לזהות גורמים נישתיים שמשפיעים על תנועה פיזית בחנות.
- בדיקת מודלים מתקדמים: מודל הרגרסיה הלינארית מספק הסבר ברור, אבל כדאי להתנסות ב-
BOOSTED_TREE_REGRESSORב-BigQuery ML בשילוב עם אסטרטגיית אימות צולב מתאימה כדי לזהות קשרים לא לינאריים. - הפיכת המפה לכלי תפעולי: מייצאים את תוצאות הרשת של H3 ללוח בקרה בהתאמה אישית באמצעות Maps JavaScript API כדי לשתף את התובנות האלה עם הצוות.
תורמים
- Henrik Valve | DevX Engineer
- Gennadii Donchyts | Staff Customer Engineer