

¿Por qué un sitio prospera mientras que otro tiene un rendimiento inferior a pesar de contar con personal, inventario y prácticas operativas coherentes? Las empresas con varias ubicaciones suelen tener dificultades para explicar esta variación en el rendimiento de su cartera. Por lo general, la respuesta se encuentra oculta en el entorno externo. Si aprovechamos los datos de los lugares de interés (POI), podemos ir más allá de las explicaciones anecdóticas y cuantificar exactamente cómo la densidad competitiva local y las características del vecindario determinan el éxito de un sitio.
En esta guía, se muestra cómo cuantificar el impacto del entorno local en el éxito del sitio con Places Insights y BigQuery ML. Combinarás tus datos de rendimiento del sitio patentados con indicadores geoespaciales externos para diagnosticar los factores que impulsan el rendimiento.
Usaremos un conjunto de datos de sitios en Londres para crear un modelo de regresión lineal. Este flujo de trabajo utiliza la indexación espacial H3, un sistema que divide la ciudad en celdas hexagonales uniformes. Si agregas datos ambientales a estas celdas, puedes entrenar un modelo para predecir el potencial de rendimiento de cualquier vecindario de la ciudad, no solo de tus sitios existentes.
Aprenderás a hacer lo siguiente:
- Ingeniería de atributos: Agrega recuentos de lugares de interés (POI), como gimnasios, escuelas y estaciones de transporte público, en un radio de 500 metros de tus sitios.
- Entrenar un modelo: Usa BigQuery ML para crear un modelo de regresión que correlacione estos atributos ambientales con tus métricas de rendimiento internas.
- Calificar la ciudad: Aplica el modelo entrenado a toda la cuadrícula H3 de Londres para identificar puntos de acceso de alto potencial para la expansión futura.
Si no conoces BigQuery ML, consulta Introducción a BigQuery ML para obtener información sobre los conceptos básicos y los tipos de modelos compatibles.
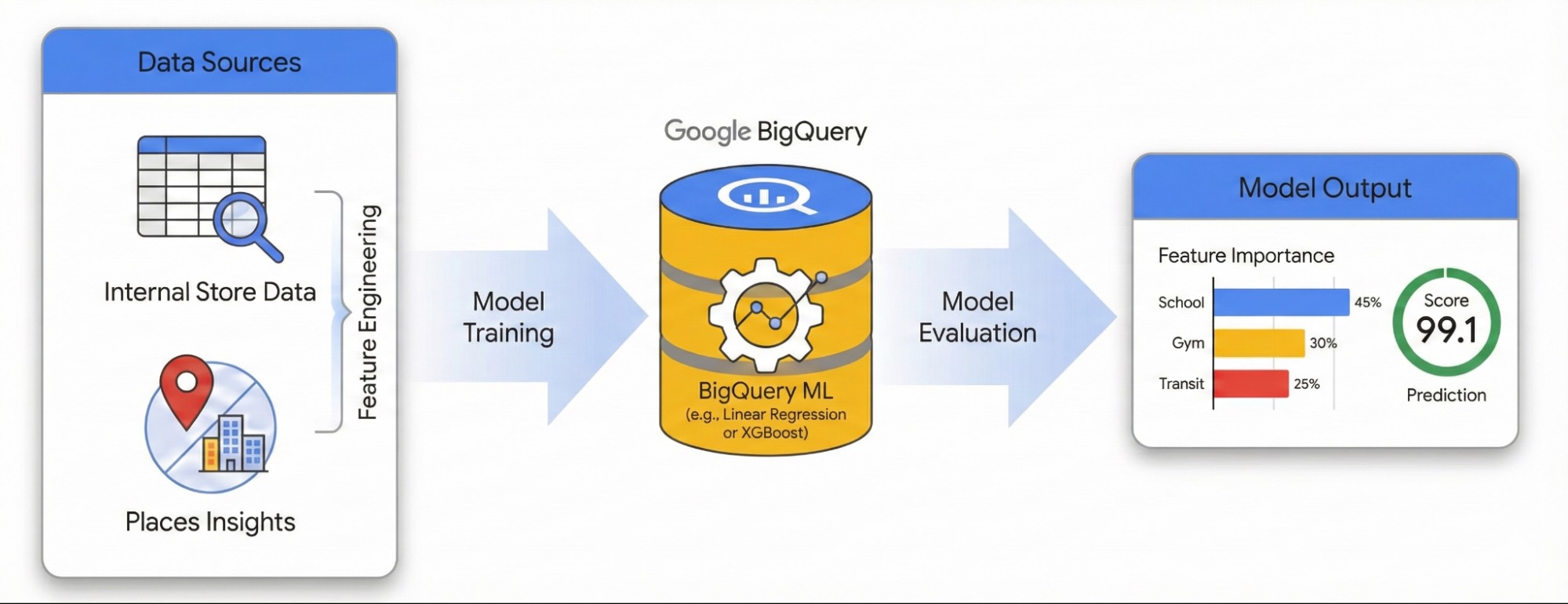
Para explorar este flujo de trabajo en un entorno interactivo, ejecuta el siguiente notebook. En él, se muestra cómo crear un modelo predictivo con BigQuery ML y visualizar oportunidades en toda la ciudad con la indexación espacial H3.
 Ver código fuente en GitHub
Ver código fuente en GitHub
Requisitos previos
Antes de comenzar, asegúrate de tener lo siguiente:
Proyecto de Google Cloud:
- Un proyecto de Google Cloud con facturación habilitada.
Acceso a los datos:
- Suscripción a Places Insights en BigQuery.
- Tu propia tabla de ubicaciones de sitios con una métrica de rendimiento (p.ej., ingresos). En los recursos del instructivo, se incluye un conjunto de datos de ejemplo.
Google Maps Platform:
- Una clave de API.
- Las siguientes APIs habilitadas para tu clave:
Entorno y bibliotecas de Python:
- Un entorno de Python, como Colab Enterprise en la consola de Google Cloud.
- Las siguientes bibliotecas instaladas:
Biblioteca Descripción pandas-gbqInteractúa con BigQuery. geopandasControla las operaciones de datos geoespaciales. foliumCrea mapas interactivos. shapelyRealiza manipulaciones geométricas.
Permisos de IAM:
- Asegúrate de que tu cuenta de usuario o de servicio tenga los siguientes roles
de IAM:
Rol ID Editor de datos de BigQuery roles/bigquery.dataEditorUsuario de BigQuery roles/bigquery.user
- Asegúrate de que tu cuenta de usuario o de servicio tenga los siguientes roles
de IAM:
Conocimiento de los costos:
- En este instructivo, se usan componentes facturables de Google Cloud. Ten en cuenta los posibles costos relacionados con lo siguiente:
- BigQuery ML: Se cobra por las ranuras de procesamiento que se usan. Consulta los precios de BigQuery ML.
- Places Insights: Se cobra según el uso de las consultas.
- En este instructivo, se usan componentes facturables de Google Cloud. Ten en cuenta los posibles costos relacionados con lo siguiente:
Ingeniería de atributos con Places Insights
Para aislar los factores externos que impulsan el rendimiento del sitio, debes transformar los datos sin procesar de los POI en atributos cuantificables. Calcularás la densidad de servicios o tipos de lugares específicos, como gimnasios, escuelas y estaciones de transporte público, en un radio de 500 metros de cada sitio. Los servicios que selecciones serán dependientes de lo que creas que puede ser más pertinente para tu empresa.
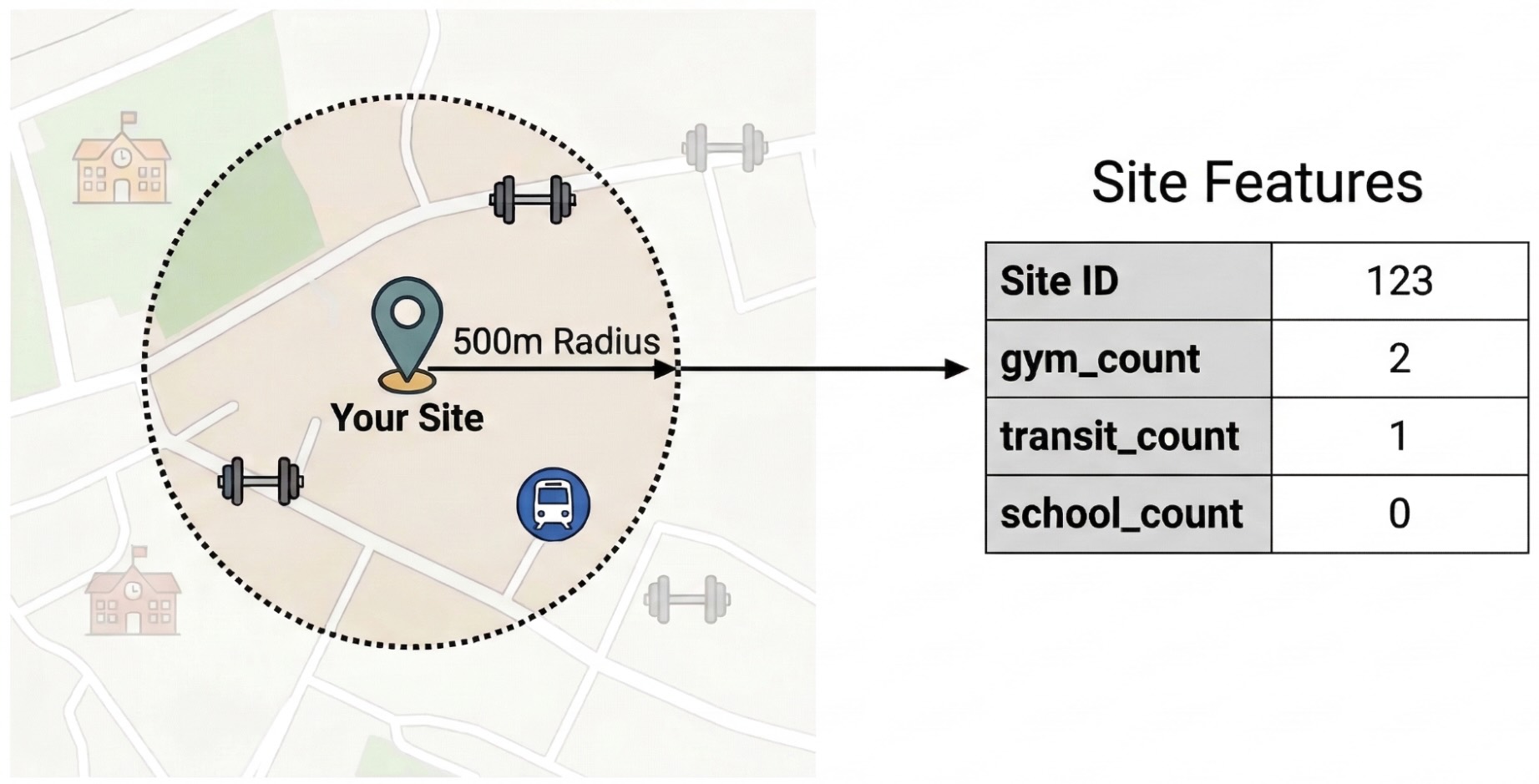
Usamos Python y la biblioteca pandas-gbq para este paso. Este enfoque te permite ejecutar la consulta SELECT WITH AGGREGATION_THRESHOLD, que es necesaria para acceder al conjunto de datos de Places Insights, y guardar los resultados en una tabla nueva de tu proyecto. Consulta Cómo consultar el conjunto de datos
directamente para obtener más información sobre cómo
trabajar con datos de Places Insights.
Ejecuta la consulta de ingeniería de atributos
Ejecuta la siguiente secuencia de comandos de Python en tu entorno (p.ej., Colab Enterprise). Esta secuencia de comandos conecta los datos internos de tu sitio con el conjunto de datos de Places Insights.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Comprende la consulta
ST_DWITHIN: Esta función geoespacial crea un búfer de 500 metros alrededor de cada ubicación del sitio y, luego, identifica todos los puntos de Places Insights que se encuentran dentro de ese radio.COUNTIF: Esta función calcula la densidad de tipos de lugares específicos (p.ej., "gimnasio", "escuela") para cada sitio. Estos recuentos se convierten en los atributos de entrada (X) para el modelo de aprendizaje automático.pandas_gbq.to_gbq: Esta función conserva los resultados de la consulta en una tabla nueva (site_features). Esta tabla permanente sirve como el conjunto de datos de entrenamiento limpio para el modelo de BigQuery ML.
Para obtener aplicaciones más avanzadas en el mundo real, considera calcular los atributos en varias distancias (p.ej., 250 m, 500 m, 1 km) y explorar otros atributos de Places Insights, como rating, price_level o regular_opening_hours. Consulta los
tipos de lugares admitidos y la
referencia del esquema principal
para obtener la lista completa de atributos de Places Insights.
Entrena el modelo con BigQuery ML
Con los atributos de ingeniería guardados en tu tabla site_features, ahora puedes
entrenar un modelo de regresión
lineal.
Este modelo aprende las ponderaciones óptimas (β) para cada atributo ambiental (X) para predecir el rendimiento de tu sitio (Y).
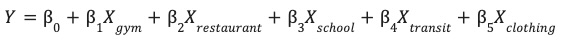
Controla los valores atípicos con el escalamiento robusto
Los datos geoespaciales suelen contener valores atípicos extremos que pueden distorsionar los modelos lineales estándar. Por ejemplo, un sitio en el West End de Londres podría tener 200 restaurantes en un radio de 500 metros, mientras que un sitio suburbano solo tiene 2. Si usas el escalamiento estándar (media/desviación estándar), el valor atípico (200) sesga la distribución y obliga al modelo a priorizar el ajuste de ese valor extremo.
Para solucionar este problema, usamos el escalamiento
robusto
(ML.ROBUST_SCALER) dentro de la definición del modelo. Esta técnica escala los atributos en función de la mediana y el rango intercuartílico (IQR), lo que hace que el modelo sea resistente a los valores atípicos y garantiza que aprenda de la distribución típica de tus sitios.
Crea el modelo
Ejecuta la siguiente consulta en SQL en BigQuery para crear y entrenar el modelo.
Usamos la
TRANSFORM
cláusula para aplicar el escalamiento robusto a todos los atributos de entrada. También establecemos
optimize_strategy = 'NORMAL_EQUATION' porque es el método de entrenamiento más eficiente
para conjuntos de datos relativamente pequeños, como una cartera típica de ubicaciones de tiendas. Por último, filtramos los valores atípicos de alto rendimiento (store_performance <
75) para enfocar el modelo en la predicción de patrones de crecimiento típicos.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Evalúa el rendimiento del modelo
Antes de poder confiar en las estadísticas del modelo sobre lo que impulsa el rendimiento del sitio, debes verificar que sus predicciones sean precisas.
Después del entrenamiento, usa la función ML.EVALUATE para evaluar las predicciones del modelo en comparación con un conjunto de datos "de retención" que no se usó durante el entrenamiento.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Verifica el R2
Score
(r2_score) y el Mean Absolute
Error
(mean_absolute_error) para determinar si tu modelo está listo para la producción:
- Un puntaje R2 mide qué parte de la varianza del rendimiento se explica realmente por los factores ambientales externos (POI cercanos). Un puntaje R2 de 0.70 significa que el 70% del éxito de un sitio está vinculado al entorno local. Cuanto más cerca de 1.0, más sólida será la correlación entre los servicios ambientales y el rendimiento del sitio.
- El MAE te indica el error promedio en puntos. Por ejemplo, un MAE de 1.5 significa que las predicciones del modelo suelen estar dentro de +/- 1.5 puntos del puntaje de rendimiento real.
Solución de problemas relacionados con puntajes bajos
Si tu puntaje R2 es bajo, considera las siguientes mejoras:
- Expande los tipos de atributos: Agrega diferentes tipos de lugares
a tu consulta (p.ej.,
tourist_attraction,subway_station). - Ajusta el radio de captación: Cambia la distancia
ST_DWITHIN. Un radio de 500 metros podría ser demasiado amplio para una cafetería, pero demasiado pequeño para una mueblería. - Aumenta el tamaño de los datos: Asegúrate de entrenar con suficientes ubicaciones de tiendas para encontrar un patrón estadísticamente significativo.
Califica la ciudad con la indexación espacial H3
Usamos la indexación espacial H3 para dividir la ciudad de Londres en una cuadrícula uniforme de celdas hexagonales (resolución 8, aproximadamente 0.7 km²). Si agregamos datos de Places Insights a estas celdas, podemos aplicar nuestro modelo entrenado a cada vecindario, identificando áreas de alto potencial que coincidan con el perfil ambiental de tus sitios con mejor rendimiento.
Ejecuta la consulta de prospección
Para generar esta cuadrícula, usamos la
PLACES_COUNT_PER_H3
función que proporciona el conjunto de datos de Places Insights (obtén más información para consultar
Places Insights con las funciones de recuento de lugares).
Esta función calcula los recuentos de POI para las celdas de la cuadrícula H3 en una sola operación.
Ejecuta la siguiente consulta en SQL para realizar tres pasos en una sola ejecución:
- Indexación y recuento H3: Llamamos a
PLACES_COUNT_PER_H3con un objeto de configuración JSON para encontrar todos los lugares operativos en un radio de 25 km del centro de Londres. Consultamos esto por separado para cada tipo de servicio (gimnasios, escuelas, etc.) y los combinamos conUNION ALL. - Tabulación dinámica (ingeniería de atributos): Como nuestro modelo de aprendizaje automático espera columnas de atributos distintas (como
gym_countyrestaurant_count), agrupamos las celdas y usamos la agregación condicional(SUM(IF(...)))para tabular los datos en el esquema correcto. - Predicción: Introducimos estos atributos de cuadrícula tabulados directamente en la función
ML.PREDICTpara generar un puntaje de rendimiento para cada vecindario.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Interpreta los resultados
La consulta muestra una tabla en la que cada fila representa un área hexagonal en Londres.
h3_index: Es el identificador único de la celda hexagonal.predicted_store_performance: Es el puntaje estimado del modelo para un sitio ubicado en esta celda, basado únicamente en el entorno circundante.h3_geography: Es la geometría poligonal de la celda, que usaremos para la visualización en el siguiente paso.
Los valores altos indican áreas en las que la densidad de escuelas, gimnasios y transporte público coincide con los patrones que se encuentran alrededor de tus sitios existentes más exitosos.
Visualiza el mapa de prospección
Para que los datos sean prácticos, visualiza los resultados en un mapa. Si bien el resultado tabular proporciona puntajes sin procesar, un mapa revela clústeres espaciales y corredores de alto potencial que no son evidentes en una lista.
En el notebook que lo acompaña, usamos la biblioteca geopandas para analizar la geometría poligonal H3 y folium para renderizar un mapa interactivo.
El resultado es un mapa coroplético en el que cada celda hexagonal está coloreada según su puntaje previsto.
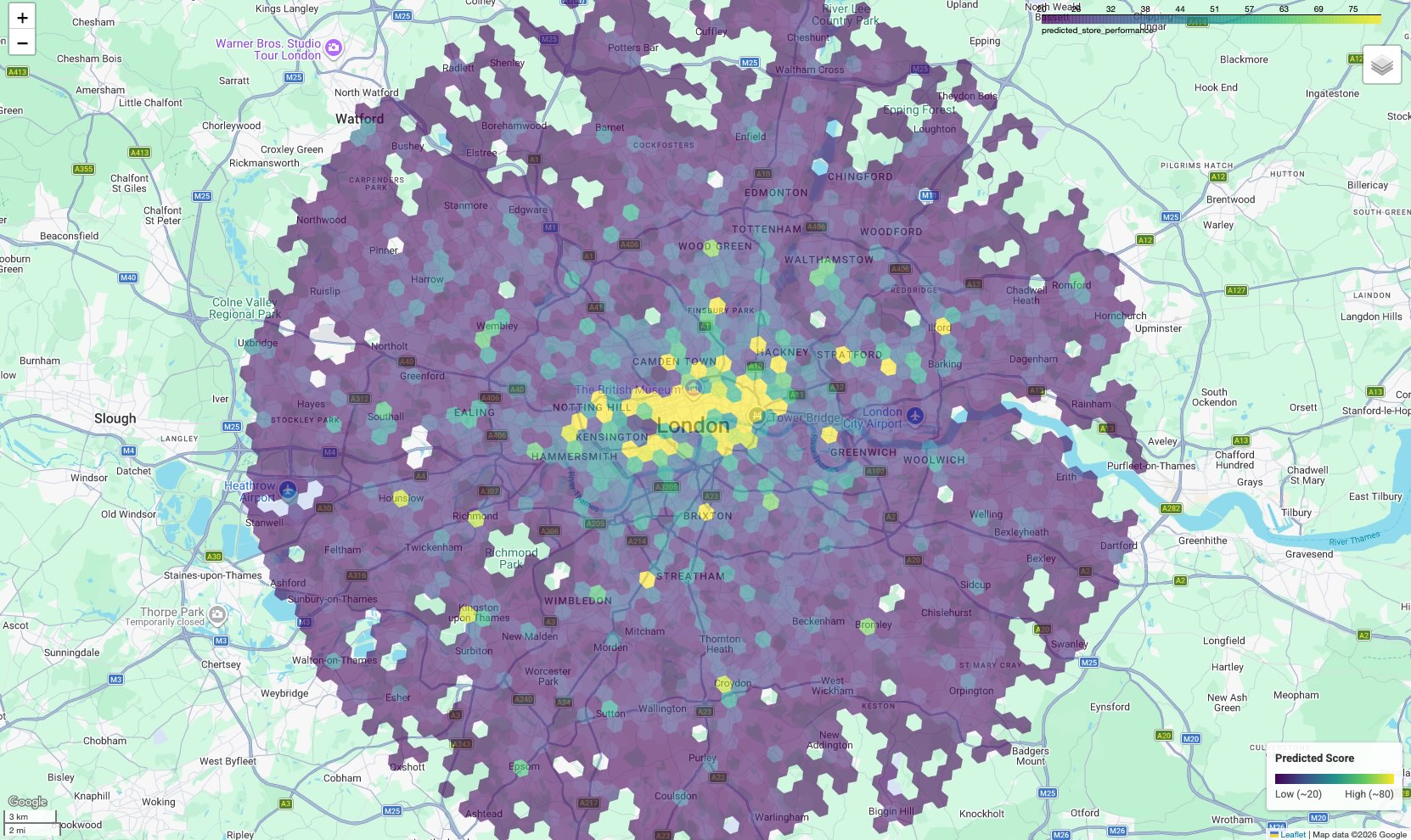
Interpreta el mapa:
- Puntos de acceso (amarillo/verde): Estas áreas tienen puntajes de rendimiento previstos altos. Poseen la densidad óptima de escuelas, gimnasios y transporte público que se correlaciona con tus sitios exitosos. Son candidatos principales para la selección de sitios nuevos.
- Puntos fríos (morado): Estas áreas carecen de los atributos ambientales de apoyo que se encuentran cerca de tus sitios con mejor rendimiento.
- Inspección interactiva: En el entorno del notebook, puedes colocar el cursor sobre cualquier celda para ver los recuentos específicos de servicios (p.ej., "Gimnasios: 12") que contribuyeron a ese puntaje específico.
Conclusión
Combinaste correctamente los datos operativos internos con Places Insights para diagnosticar el rendimiento del sitio. Al analizar las ponderaciones del modelo, identificaste las características específicas del vecindario que se correlacionan con tus métricas existentes. Con la indexación espacial H3, escalaste este análisis de unos cientos de sitios a miles de vecindarios potenciales en Londres.
Próximas acciones
- Expande la ingeniería de atributos: Agrega tipos de lugares más específicos a tu consulta para captar los factores de nicho del tráfico presencial.
- Explora modelos avanzados: Si bien la regresión lineal proporciona una explicación clara
experimenta con
BOOSTED_TREE_REGRESSORen BigQuery ML combinado con una estrategia de validación cruzada adecuada para captar relaciones no lineales. - Operacionaliza el mapa: Exporta los resultados de la cuadrícula H3 a un panel personalizado con la API de Maps JavaScript para compartir estas estadísticas con tu equipo.
Colaboradores
- Henrik Valve | Ingeniero de DevX
- Gennadii Donchyts | Ingeniero de Atención al cliente sénior