Comprendre les bases du SEO JavaScript
JavaScript joue un rôle crucial dans la plate-forme Web. En effet, ses nombreuses fonctionnalités lui permettent de convertir le Web en une plate-forme applicative puissante. En permettant à la recherche Google d'accéder à vos applications JavaScript, vous pouvez non seulement attirer de nouveaux utilisateurs, mais aussi inciter les utilisateurs existants à s'engager à nouveau lorsqu'ils recherchent du contenu fourni par vos applications Web. Bien que la recherche Google utilise JavaScript avec une version toujours actualisée de Chromium, plusieurs optimisations sont possibles.
Ce guide décrit comment la recherche Google traite JavaScript et partage des bonnes pratiques permettant d'améliorer la visibilité des applications Web JavaScript dans la recherche Google.
Traitement de JavaScript
Google traite les applications Web JavaScript en trois phases principales :
- Exploration
- Affichage
- Indexation
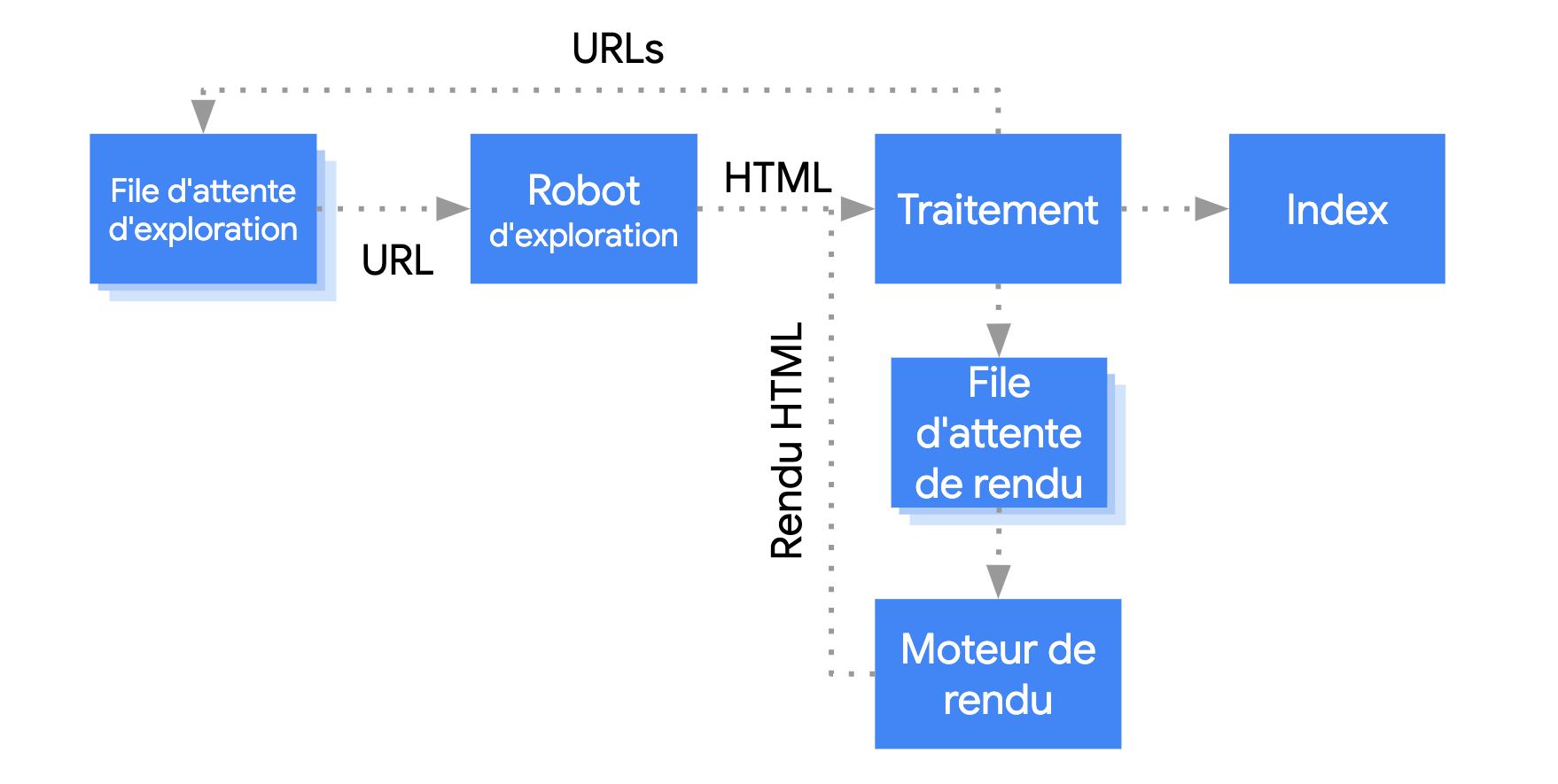
Googlebot met les pages en file d'attente pour l'exploration et l'affichage. Il n'est pas évident de déterminer immédiatement si une page est en attente d'exploration ou d'affichage. Lorsque Googlebot extrait une URL de la file d'attente d'exploration via une requête HTTP, il vérifie d'abord si vous en autorisez l'exploration. Googlebot lit alors le fichier robots.txt. Si l'URL est marquée comme non autorisée, Googlebot n'envoie pas la requête HTTP pour cette URL et ignore cette dernière. La recherche Google n'affichera pas le code JavaScript des fichiers ou des pages bloqués.
Googlebot analyse ensuite la réponse pour les autres URL dans l'attribut href des liens HTML, puis ajoute les URL à la file d'attente d'exploration. Pour empêcher la découverte de liens, utilisez le mécanisme nofollow.
L'exploration d'une URL et l'analyse de la réponse HTML conviennent particulièrement aux sites Web classiques ou aux pages affichées côté serveur dans lesquelles le code HTML de la réponse HTTP inclut tout le contenu. Certains sites JavaScript utilisent le modèle "shell d'application". Dans ce cas, le code HTML initial ne comporte pas le contenu réel, et Google doit exécuter JavaScript avant de pouvoir lire le contenu de la page générée par JavaScript.
Googlebot met toutes les pages avec un code d'état HTTP 200 en file d'attente pour l'affichage, sauf si un en-tête ou une balise meta pour les robots indique à Google de ne pas indexer la page.
La page peut rester dans cette file d'attente pendant quelques secondes ou pendant plus de temps. Une fois que les ressources de Google le permettent, l'environnement Chromium headless (sans tête) affiche la page et exécute le code JavaScript.
Googlebot recherche à nouveau les liens dans le code HTML affiché, puis met les URL en file d'attente pour l'exploration. Google utilise également le code HTML affiché pour indexer la page.
Gardez à l'esprit que l'affichage côté serveur ou le pré-affichage reste recommandé, car il permet aux utilisateurs et aux robots d'exploration d'accéder à votre site plus rapidement. De plus, tous les robots n'utilisent pas forcément JavaScript.
Décrire votre page avec des titres et des extraits uniques
Le recours à des éléments <title> uniques et descriptifs, ainsi qu'à des meta descriptions aide les utilisateurs à identifier rapidement le résultat le plus adapté à leur objectif.
Vous pouvez utiliser JavaScript pour définir ou modifier la meta description et l'élément <title>.
Définir l'URL canonique
La balise de lien rel="canonical" aide Google à trouver la version canonique d'une page.
Vous pouvez utiliser JavaScript pour définir l'URL canonique, mais n'oubliez pas que vous ne devez pas l'utiliser pour la remplacer par une autre URL que celle que vous avez spécifiée comme URL canonique dans le code HTML d'origine.
La meilleure façon de définir l'URL canonique est d'utiliser le code HTML. Toutefois, si vous devez utiliser JavaScript, assurez-vous de toujours définir l'URL canonique sur la même valeur que le code HTML d'origine.
Si vous ne pouvez pas définir l'URL canonique dans le code HTML, vous pouvez utiliser JavaScript pour la définir et l'omettre du code HTML d'origine.
S'assurer que le code est compatible
Les navigateurs proposent de nombreuses API, et le langage JavaScript évolue rapidement. Google impose certaines limitations concernant les API et les fonctionnalités JavaScript acceptées. Pour vous assurer que le code est compatible avec Google, suivez les instructions permettant de résoudre les problèmes liés à JavaScript.
Nous vous recommandons d'opter pour la diffusion différentielle et les polyfills si vous détectez une API de navigateur manquante dont vous avez besoin. Étant donné que certaines fonctionnalités de navigateur ne sont pas compatibles avec les polyfills, nous vous recommandons de consulter la documentation relative aux polyfills pour vous familiariser avec les limitations potentielles.
Utiliser des codes d'état HTTP adéquats
Googlebot utilise les codes d'état HTTP pour déterminer si une erreur s'est produite lors de l'exploration de la page.
Pour indiquer à Googlebot si une page ne peut pas être explorée ou indexée, utilisez un code d'état adéquat, tel que 404 pour une page introuvable ou 401 pour les pages protégées par des identifiants de connexion.
Vous pouvez utiliser des codes d'état HTTP pour indiquer à Googlebot si une page a été migrée vers une nouvelle URL. L'index pourra ainsi être mis à jour en conséquence.
Voici la liste des codes d'état HTTP et leur effet sur la recherche Google.
Éviter les erreurs soft 404 dans les applications à page unique
Dans les applications à page unique affichées côté client, le routage est souvent mis en œuvre du côté du client.
Dans ce cas, l'utilisation de codes d'état HTTP adéquats peut se révéler impossible ou difficilement applicable.
Pour éviter les erreurs soft 404 lors de l'affichage et du routage côté client, optez pour l'une des stratégies suivantes :
- Utilisez une redirection JavaScript vers une URL pour laquelle le serveur répond avec un code d'état HTTP
404(par exemple,/not-found). - Ajoutez une balise
<meta name="robots" content="noindex">aux pages d'erreur à l'aide de JavaScript.
Voici un exemple de code si vous optez pour la redirection :
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Voici un exemple de code si vous optez pour une balise noindex :
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Utiliser History API plutôt que des fragments
Google ne peut découvrir vos liens que s'il s'agit d'éléments HTML <a> avec un attribut href.
Pour les applications monopages avec routage côté client, utilisez l'API History pour implémenter le routage entre différentes vues de votre application Web. Pour que Googlebot puisse analyser et extraire vos URL, n'utilisez pas de fragments pour charger différents contenus de la page. L'exemple suivant illustre ce qu'il est déconseillé de faire, car Googlebot ne peut pas résoudre les URL de manière fiable :
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
À la place, mettez en œuvre l'API History pour vous assurer que Googlebot a accès à vos URL :
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Insérer correctement la balise link rel="canonical"
Il n'est pas recommandé d'utiliser JavaScript, mais il est possible d'insérer une balise link rel="canonical" avec JavaScript.
La recherche Google récupère l'URL canonique insérée lors de l'affichage de la page. Voici un exemple d'insertion de balise link rel="canonical" avec JavaScript :
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Utiliser les balises meta robots avec précaution
Vous pouvez empêcher Google d'indexer une page ou de suivre les liens via la balise meta pour les robots.
Par exemple, ajouter la balise meta suivante en haut de la page empêche Google d'indexer cette dernière :
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Vous pouvez utiliser JavaScript pour ajouter une balise meta pour les robots à une page ou modifier son contenu.
L'exemple de code suivant montre comment remplacer la balise meta robots par un code JavaScript pour empêcher l'indexation de la page active si un appel d'API ne renvoie pas de contenu.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Utiliser la mise en cache de longue durée
Googlebot met le contenu en cache de manière intensive afin de réduire les requêtes réseau et l'utilisation des ressources. WRS peut ignorer les en-têtes de mise en cache. Cela peut entraîner l'utilisation de ressources JavaScript ou CSS obsolètes par WRS.
L'empreinte du contenu évite ce problème en prenant une empreinte de la partie contenu du nom de fichier, par exemple main.2bb85551.js.
L'empreinte dépend du contenu du fichier. Par conséquent, les mises à jour génèrent un nom de fichier différent à chaque fois.
Pour en savoir plus, consultez le guide web.dev sur les stratégies de mise en cache de longue durée.
Utiliser les données structurées
Lorsque vous utilisez des données structurées dans vos pages, vous pouvez utiliser JavaScript pour générer le fichier JSON-LD et l'injecter dans la page. Assurez-vous de tester votre mise en œuvre pour éviter tout problème.
Suivre les bonnes pratiques relatives aux composants Web
Google accepte les composants Web. Lorsque Google affiche une page, il regroupe les contenus Light DOM et Shadow DOM. En d'autres termes, Google ne voit que le contenu visible dans le rendu HTML. Pour vous assurer que Google continue de voir votre contenu après son rendu, utilisez le test des résultats enrichis ou l'outil d'inspection d'URL.
Si le contenu n'est pas visible dans le rendu HTML, Google ne peut pas l'indexer.
L'exemple suivant crée un composant Web qui affiche son contenu Light DOM dans son composant Shadow DOM. Pour vous assurer que les contenus Light DOM et Shadow DOM apparaissent dans le rendu HTML, vous pouvez utiliser un élément Slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Après le rendu, Google peut indexer le contenu suivant :
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Résoudre les problèmes liés aux images et au chargement différé du contenu
Les images consomment souvent beaucoup de bande passante et peuvent nuire aux performances. Une bonne stratégie consiste à recourir au chargement différé afin de ne charger les images que lorsque l'utilisateur est sur le point de les consulter. Pour vous assurer que vous mettez en œuvre la fonctionnalité de chargement différé sans affecter l'expérience de recherche des internautes, suivez ces consignes.