JavaScript SEO の基本を理解する
JavaScript には、ウェブを強力なアプリケーション プラットフォームに変える多くの機能が用意されており、ウェブ プラットフォームを支える重要な要素となっています。JavaScript を利用するウェブアプリを Google 検索で見つかりやすくしましょう。デベロッパー様のウェブアプリが提供するコンテンツを探している新しいユーザーの開拓や、以前に利用したことがあるユーザーの再エンゲージメントにつながります。Google 検索は JavaScript を最新バージョンの Chromium で実行しますが、デベロッパー様側で最適化できる項目がいくつかあります。
このガイドでは、Google 検索で JavaScript が処理される仕組みについて説明し、Google 検索に対して JavaScript ベースのウェブアプリを最適化するためのヒントを紹介します。
Google が JavaScript を処理する仕組み
Google は、JavaScript ベースのウェブアプリを 3 つの主要なフェーズで処理します。
- クロール
- レンダリング
- インデックス登録
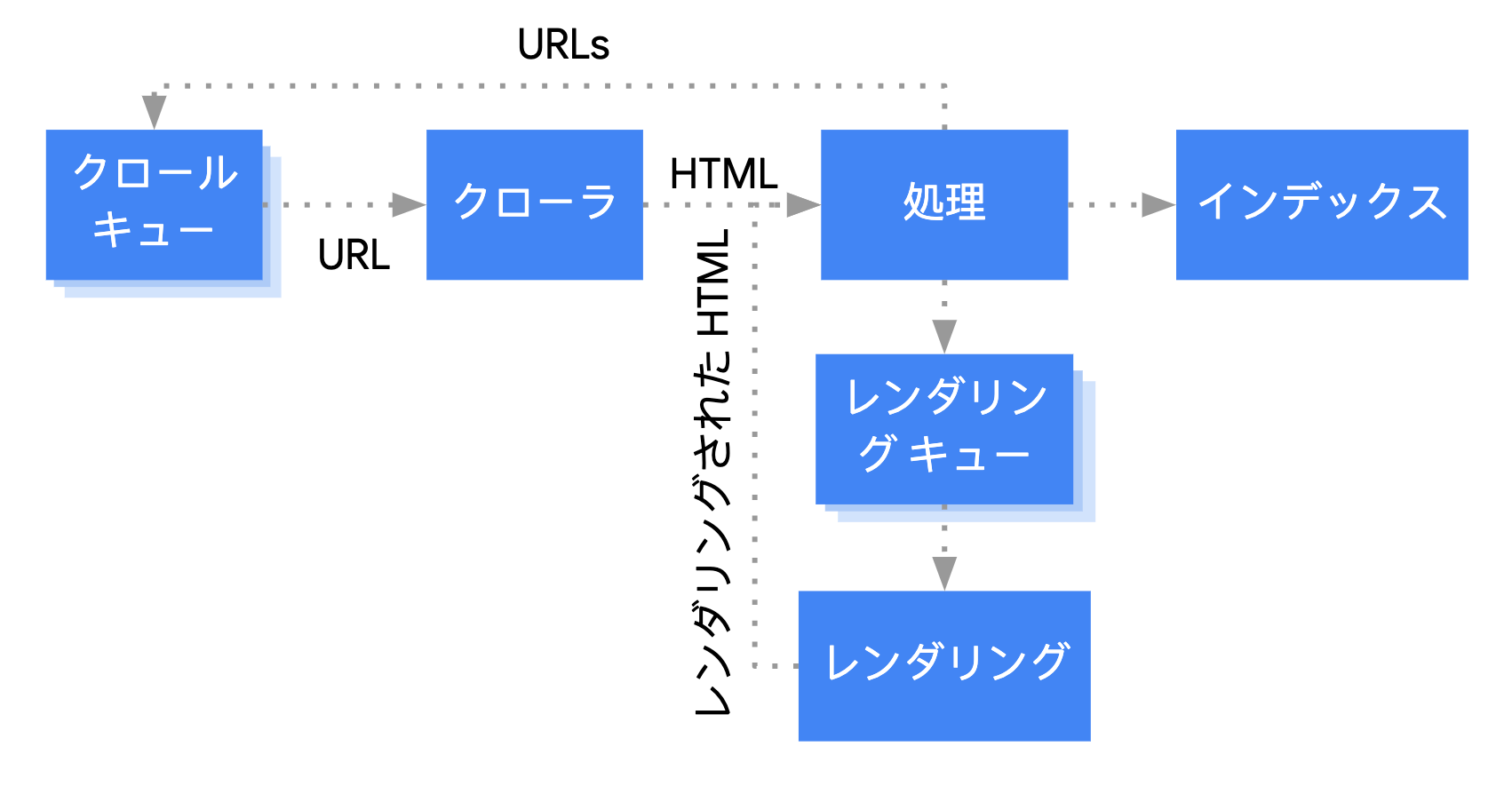
Googlebot は、クロールとレンダリングの両方のフェーズで、ページをキューに入れます。ページがクロールやレンダリング待ちの状態になるタイミングは、直接にはわかりません。Googlebot は、HTTP リクエストを発行してクロール キューから URL を取得すると、クロールが許可されているかどうかを最初に確認します。そのために Googlebot は robots.txt ファイルを読み取ります。URL がクロール禁止対象としてマークされている場合、Googlebot はその URL に対して HTTP リクエストを実行せず、URL をスキップします。Google 検索は、ブロックされたファイルやページ上の JavaScript をレンダリングしません。
次に、Googlebot は HTML リンクの href 属性内の他の URL についてレスポンスを解析し、URL をクロール キューに追加します。リンクの検出を回避するには、nofollow メカニズムを使用します。
URL のクロールと HTML レスポンスの解析は、HTTP レスポンス内の HTML にすべてのコンテンツが含まれている従来型のウェブサイトや、サーバーサイドでレンダリングされるページでは、問題なく実行できます。一方、一部の JavaScript サイトでは、App Shell モデルを使用していることがあります。この場合、最初は HTML に実際のコンテンツが含まれておらず、Google が JavaScript によって生成される実際のページ コンテンツを参照するには JavaScript を実行する必要があります。
robots meta タグまたはヘッダーによってページのインデックス登録が禁止されていなければ、Googlebot は 200 HTTP ステータス コードのすべてのページをレンダリングするためキューに入れます。ページはこのキューで数秒間(またはそれ以上)待機することがあります。Google のリソースに空きができると、ヘッドレスの Chromium がページをレンダリングして JavaScript を実行します。Googlebot はレンダリングされた HTML のリンクを再度解析し、見つかった URL をクロールするためキューに入れます。また、Google はレンダリングされた HTML を使用してページをインデックスに登録します。
ユーザーやクローラーに対してウェブサイトを高速化する効果があり、bot によっては JavaScript を実行できないものもあるため、サーバー側でのレンダリング(プリ レンダリング)も有効な方法として検討してみてください。
独自のタイトルとスニペットを持つページを作成する
<title> 要素を内容が伝わりやすい独自のものにし、わかりやすいメタ ディスクリプションを付けると、ユーザーが目的とする結果を見つけやすくなります。<title> 要素とメタ ディスクリプションは、JavaScript で設定または変更できます。
正規 URL を設定する
rel="canonical" リンクタグは、Google がページの正規バージョンを見つけるのに役立ちます。JavaScript を使用して正規 URL を設定できますが、元の HTML で正規 URL として指定した URL 以外の URL に正規 URL を変更するために JavaScript を使用することは避けてください。正規 URL を設定する最善の方法は HTML を使用することですが、JavaScript を使用する必要がある場合は、正規 URL を常に元の HTML と同じ値に設定してください。HTML で正規 URL を設定できない場合は、JavaScript を使用して正規 URL を設定し、元の HTML から除外できます。
互換性のあるコードを作成する
ブラウザからは多くの API が提供され、JavaScript は急速に進化している言語であることから、Google のサポートする API と JavaScript の機能には一定の制約があります。コードを Google と互換性があるものにするには、JavaScript の問題のトラブルシューティングに関するガイドラインに準拠してください。
必要とするブラウザの API で足りない機能を検出するには、差分配信とポリフィルの利用をおすすめします。一部のブラウザ機能はポリフィルできないため、考えられる制限事項をポリフィルのドキュメントで確認することをおすすめします。
有意な HTTP ステータス コードを使用する
Googlebot は、ページをクロールする際に問題が発生したかどうかを確認するために、HTTP ステータス コードを使用します。
ページに対するクロールやインデックス登録を許可しない場合は、それを Googlebot に伝えるために、有意なステータス コードを使用します。たとえば、ページが見つからなかったことを示す 404 や、ログインできなかったことを示す 401 などのコードがあります。また、HTTP ステータス コードを使用して、ページが新しい URL に移動されたことを Googlebot に通知することもできます。そうすることで、インデックスが随時更新されます。
HTTP ステータス コードと Google 検索への影響については、こちらをご覧ください。
シングルページ アプリで soft 404 エラーを回避する
クライアント側でレンダリングされたシングルページ アプリでは多くの場合、ルーティングはクライアント側ルーティングとして実装されます。
この場合、有意な HTTP ステータス コードの使用は不可能か、実用的でないことがあります。クライアント側でレンダリングやルーティングを行う場合に soft 404 エラーを回避するには、次のいずれかを実施します。
- サーバーが
404HTTP ステータス コード(/not-foundなど)を返す URL にリダイレクトする JavaScript を使用する。 - JavaScript を使用してエラーページに
<meta name="robots" content="noindex">を追加する。
リダイレクトを行う場合のサンプルコードを次に示します。
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
noindex タグを使用する場合のサンプルコードを次に示します。
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
フラグメントの代わりに History API を使用する
Google がリンクを検出できるのは、href 属性が設定された <a> HTML 要素の場合のみです。
クライアントサイド ルーティングを使用するシングルページ アプリケーションでは、History API を使用して、ウェブアプリのビュー間にルーティングを実装します。Googlebot が URL を確実に抽出して解析できるように、フラグメントを使用して別のページ コンテンツを読み込まないでください。次に示す方法は、Googlebot が URL を確実に解決できないため適切ではありません。
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
代わりに History API を実装することで、Googlebot が URL に確実にアクセスできるようになります。
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
rel="canonical" リンクタグを適切に挿入する
この場合、JavaScript の使用はおすすめしませんが、JavaScript を使用して rel="canonical" リンクタグを挿入することは可能です。Google 検索では、ページのレンダリング時に、挿入された正規 URL が取得されます。JavaScript を使用して rel="canonical" リンクタグを挿入する例を次に示します。
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
robots meta タグを使用する場合の注意点
robots meta タグは、Google によるページのインデックス登録やリンクの参照を回避するために使用できます。たとえば、ページの上部に次の meta タグを追加すると、Google によるページのインデックス登録がブロックされます。
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
JavaScript を使用して、robots meta タグをページに追加したり、タグの内容を変更したりできます。次のコード例は、API 呼び出しでコンテンツが返されない場合は現在のページがインデックスに登録されないように、JavaScript で robots meta タグを変更する方法を示しています。
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
長期保存キャッシュを使用する
Googlebot は、ネットワーク リクエストとリソース使用量を減らすために、積極的にキャッシュに保存しますが、WRS はキャッシュ ヘッダーを無視することがあります。このため、WRS は古い JavaScript や CSS リソースを使用するおそれがあります。この問題は、ファイル名の一部をコンテンツのフィンガープリントにすることで回避されます(main.2bb85551.js など)。フィンガープリントはファイル コンテンツによって異なるため、更新するたびに別のファイル名が生成されます。詳しくは、長期保存キャッシュを使用する際の web.dev ガイドをご覧ください。
構造化データを使用する
ページで構造化データを使用する場合は、JavaScript を使用して必要な JSON-LD を生成し、ページに挿入できます。問題を避けるために、必ず実装をテストしてください。
ウェブ コンポーネントに関するおすすめの方法に従う
Google はウェブ コンポーネントをサポートしています。 Google がページをレンダリングする際、Shadow DOM と Light DOM のコンテンツがフラット化されます。 つまり、Google はレンダリングされた HTML に表示されるコンテンツのみを認識できます。レンダリング後に Google がコンテンツを引き続き認識できるようにするには、リッチリザルト テストまたは URL 検査ツールを使用して、レンダリングされた HTML を確認します。
レンダリングされた HTML にコンテンツが表示されない場合は、Google はそのコンテンツをインデックスに登録できません。
次の例は、Shadow DOM 内に Light DOM コンテンツを表示するウェブ コンポーネントを作成します。 レンダリングされた HTML に Light DOM と Shadow DOM の両方のコンテンツが表示されるようにする 1 つの方法は、Slot 要素を使用することです。
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>レンダリング後、Google はこのコンテンツをインデックスに登録します。
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
画像と遅延読み込みされるコンテンツを修正する
画像があると、帯域幅とパフォーマンスにかなりの負荷がかかることがあります。ユーザーが画像を表示しようとしたときにだけ、画像を遅延読み込みする方法をおすすめします。遅延読み込みを実装して検索されやすくするには、遅延読み込みのガイドラインに従ってください。