Dati strutturati per i set di dati (Dataset, DataCatalog, DataDownload)
I set di dati sono più facili da trovare nello strumento Ricerca per set di dati quando fornisci informazioni di supporto come il nome, la descrizione, l'autore e i formati di distribuzione sotto forma di dati strutturati. L'approccio di Google al rilevamento di set di dati utilizza schema.org e altri standard di metadati inseribili nelle pagine che descrivono i set di dati. Lo scopo di questo markup è migliorare il rilevamento dei set di dati in settori come le scienze biologiche e sociali, il machine learning, i dati civici e amministrativi e altri ancora.
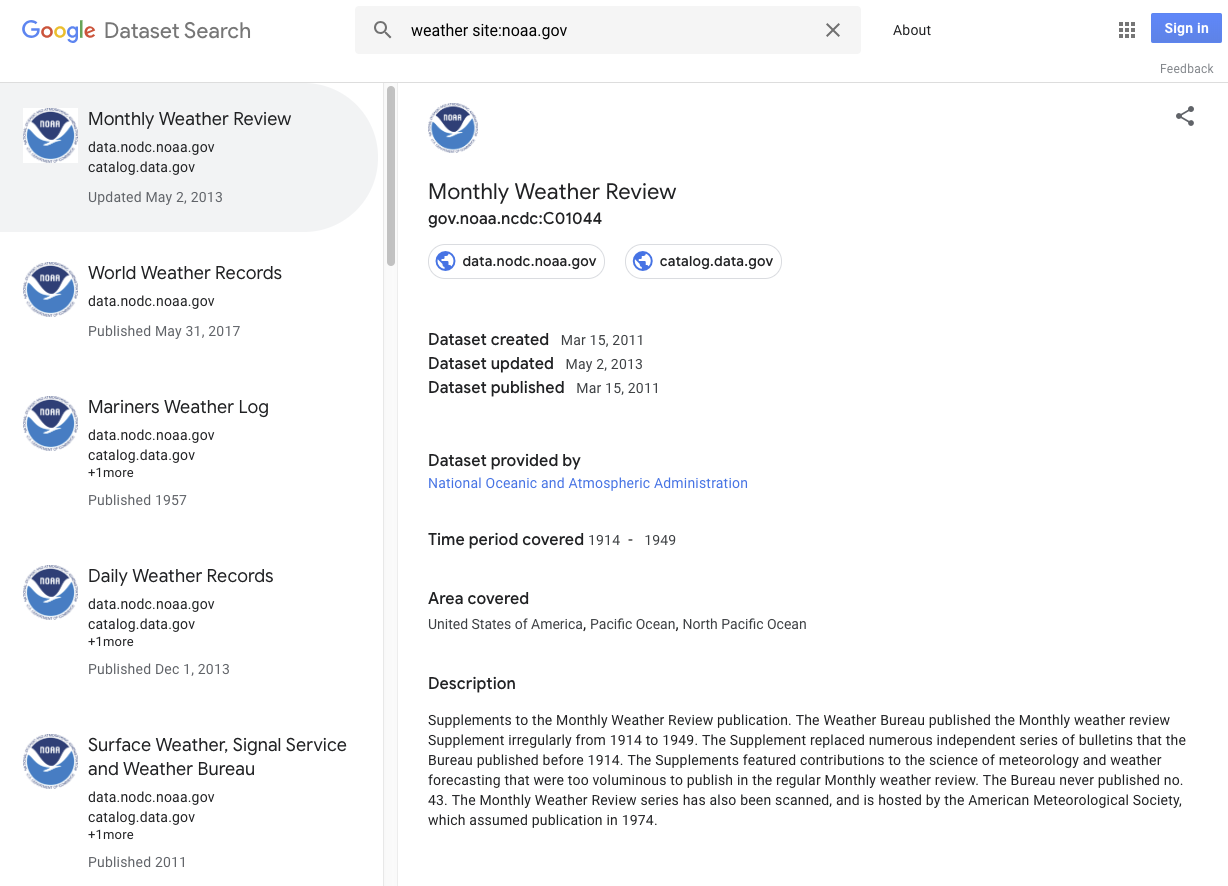
Di seguito sono riportati alcuni esempi di ciò che può essere considerato un set di dati:
- Una tabella o un file CSV contenente dati
- Una raccolta organizzata di tabelle
- Un file in un formato proprietario che contiene dati
- Una raccolta di file che insieme costituiscono un set di dati significativo
- Un oggetto strutturato con dati in un altro formato che potresti voler caricare in uno speciale strumento per l'elaborazione
- Dati di acquisizione delle immagini
- File relativi al machine learning, quali parametri addestrati o definizioni di strutture di rete neurale
Come aggiungere dati strutturati
I dati strutturati sono un formato standardizzato per fornire informazioni su una pagina e classificarne i contenuti. Se non li hai mai utilizzati, scopri di più su come funzionano i dati strutturati.
Ecco una panoramica su come creare, testare e rilasciare i dati strutturati.
- Aggiungi le proprietà obbligatorie. In base al formato che utilizzi, scopri dove inserire i dati strutturati nella pagina.
- Segui le linee guida.
- Convalida il codice utilizzando lo strumento di Test dei risultati avanzati e correggi eventuali errori critici. Prendi in considerazione anche la possibilità di correggere eventuali problemi non critici che potrebbero essere segnalati nello strumento, in quanto possono contribuire a migliorare la qualità dei tuoi dati strutturati (tuttavia, questo non è necessario per l'idoneità per i risultati avanzati).
- Implementa alcune pagine che includono dati strutturati e utilizza lo strumento Controllo URL per verificare come Google vede la pagina. Assicurati che la pagina sia accessibile per Google e che non venga bloccata da file robots.txt, tag
noindexo requisiti di accesso. Se la pagina non presenta problemi, puoi chiedere a Google di ripetere la scansione degli URL. - Per tenere Google informata delle future modifiche, ti consigliamo di inviare una Sitemap. Puoi automatizzare questa operazione con l'API Search Console Sitemap.
Eliminare un set di dati dai risultati di Ricerca per set di dati
Se preferisci che un set di dati non venga visualizzato nei risultati di Ricerca per set di dati, usa il meta tag robots per gestirne la modalità di indicizzazione. Tieni presente che potrebbe essere necessario un po' di tempo (giorni o settimane, a seconda della pianificazione di scansione) per applicare le modifiche in Ricerca per set di dati.
Il nostro approccio al rilevamento di set di dati
Siamo in grado di comprendere i dati strutturati relativi ai set di dati nelle pagine web attraverso il markup Dataset di schema.org o le strutture equivalenti
rappresentate nel formato Data Catalog Vocabulary (DCAT) di W3C. Stiamo inoltre valutando
di supportare in via sperimentale i dati strutturati basati su CSVW di W3C e prevediamo di sviluppare e adattare il nostro approccio all'emergere di eventuali best practice per la descrizione dei set di dati. Per ulteriori informazioni sul nostro
approccio al rilevamento di set di dati, consulta la pagina su
come facilitare il rilevamento dei set di dati.
Esempi
Ecco un esempio di set di dati in cui vengono usati il codice JSON-LD e la sintassi di schema.org (opzione preferita) nello strumento di Test dei risultati avanzati. Lo stesso vocabolario di schema.org può essere usato anche nelle sintassi RDFa 1.1 o Microdati. Puoi anche usare il vocabolario DCAT di W3C per descrivere i metadati. L'esempio seguente si basa sulla descrizione di un set di dati reale.
Ecco un esempio di set di dati in formato JSON-LD:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Ecco un esempio di set di dati in formato RDFa che utilizza il vocabolario DCAT (non supportato nel Test dei risultati avanzati):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Linee guida
I siti devono seguire le linee guida sui dati strutturati. Oltre alle linee guida sui dati strutturati, ti consigliamo di attenerti alle best practice relative a Sitemap e a fonte e provenienza.
Best practice relative a Sitemap
Utilizza un file Sitemap per consentire
a Google di trovare i tuoi URL. L'utilizzo dei file Sitemap e del markup sameAs consente di documentare la modalità
di pubblicazione delle descrizioni dei set di dati in tutto il sito.
Se disponi di un repository di set di dati, è probabile che tu abbia almeno due tipi di pagine: le pagine canoniche
("di destinazione") per ogni set di dati e le pagine che elencano più set di dati (ad esempio, risultati di
ricerca o alcuni sottoinsiemi di set di dati). Ti consigliamo di aggiungere dati strutturati relativi a un set di dati alle pagine canoniche. Utilizza la proprietà sameAs
per rimandare alla pagina canonica se aggiungi dati strutturati a più copie del
set di dati, ad esempio schede nelle pagine dei risultati di ricerca.
Best practice relative a fonte e provenienza
È abbastanza comune che i set di dati aperti vengano ripubblicati, aggregati e basati su altri set di dati. Qui viene illustrata una panoramica del nostro approccio alla rappresentazione di situazioni in cui un set di dati è la copia di un altro set o è basato su quest'ultimo.
- Utilizza la proprietà
sameAsper indicare gli URL più canonici per l'originale nei casi in cui il set di dati (o la descrizione) sia una semplice ripubblicazione di materiali pubblicati altrove. Il valore disameAsdeve indicare in modo univoco l'identità del set di dati. In altre parole, non utilizzare lo stesso valore disameAsper due set di dati diversi. - Utilizza la proprietà
isBasedOnnei casi in cui il set di dati ripubblicato (inclusi i relativi metadati) è stato modificato in modo significativo. - Quando un set di dati deriva da diversi originali o ne rappresenta un'aggregazione, utilizza la
proprietà
isBasedOn. - Utilizza la proprietà
identifierper collegare eventuali identificatori di oggetti digitali (DOI) o identificatori compatti pertinenti. Se il set di dati ha più identificatori, ripeti la proprietàidentifier. Se usi il formato JSON-LD, viene usata la sintassi degli elenchi JSON.
Ci auguriamo di migliorare i nostri consigli in base ai feedback ricevuti, in particolare quelli relativi alla descrizione della provenienza, al controllo delle versioni e alle date associate alla pubblicazione in serie temporali. Unisciti anche tu alle discussioni della community.
Consigli relativi alle proprietà del testo
Ti consigliamo di limitare tutte le proprietà di testo a un massimo di 5000 caratteri. La Ricerca Google per set di dati utilizza solo i primi 5000 caratteri di qualsiasi proprietà di testo. Nomi e titoli sono in genere costituiti da poche parole o una breve frase.
Avvisi ed errori noti
Potresti riscontrare errori o avvisi nel Test dei risultati avanzati di Google e in altri sistemi di convalida. In particolare, i sistemi di convalida possono suggerire che le organizzazioni devono avere informazioni di contatto che includano un elemento contactType; i valori utili includono customer service, emergency, journalist, newsroom e public engagement.
Puoi anche ignorare gli errori relativi a csvw:Table identificato come valore imprevisto per la proprietà mainEntity.
Definizioni dei tipi di dati strutturati
Affinché i tuoi contenuti siano idonei per la visualizzazione come risultato avanzato, devi includere le proprietà obbligatorie. Puoi anche includere le proprietà consigliate per aggiungere ulteriori informazioni sui contenuti e fornire così un'esperienza utente migliore.
Puoi utilizzare il Test dei risultati avanzati per convalidare il tuo markup.
La priorità va alla descrizione delle informazioni relative a un set di dati (i relativi metadati) e alla rappresentazione dei relativi contenuti. Ad esempio, i metadati del set di dati indicano di cosa tratta il set di dati, quali variabili misura, chi lo ha creato e così via ma non, ad esempio, i valori specifici delle variabili.
Dataset
La definizione completa di Dataset è disponibile all'indirizzo
schema.org/Dataset.
Puoi descrivere ulteriori informazioni sulla pubblicazione del set di dati, ad esempio la
licenza, quando è stato pubblicato, il relativo
DOI
o un valore sameAs che rimanda a una versione canonica del set di dati in un
repository diverso. Aggiungi identifier, license e sameAs per i set di dati che forniscono informazioni sulla provenienza e sulla licenza.
Le proprietà supportate da Google sono le seguenti:
| Proprietà obbligatorie | |
|---|---|
description
|
Text
Un breve riepilogo che descrive un set di dati. Linee guida
|
name
|
Text
Un nome descrittivo di un set di dati. Ad esempio, "La profondità della neve nell'emisfero settentrionale". Linee guida
Consigliato: Non consigliato: |
| Proprietà consigliate | |
|---|---|
alternateName
|
Text
Nomi alternativi che sono stati utilizzati per fare riferimento a questo set di dati, come alias o abbreviazioni. Esempio (nel formato JSON-LD): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person o
Organization
Il creatore o l'autore del set di dati. Per identificare in modo univoco le persone, usa il valore ORCID ID per la proprietà "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text o CreativeWork
Identifica gli articoli accademici consigliati dal fornitore di dati come da citare in aggiunta al set di dati stesso. Fornisci la citazione per il set di dati con altre proprietà come "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Linee guida aggiuntive
|
funder
|
Person o
Organization
Una persona o un'organizzazione che fornisce sostegno finanziario per questo set di dati. Per identificare in modo univoco le persone, usa il valore ORCID ID per la proprietà "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart o isPartOf
|
URL o
Dataset
Se il set di dati è una raccolta di set di dati più piccoli, utilizza la proprietà "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text o PropertyValue
Un identificatore, ad esempio DOI o identificatori compatti. Se il set di dati contiene più identificatori, ripeti la proprietà |
isAccessibleForFree
|
Boolean
Indica se il set di dati è accessibile senza pagamento. |
keywords
|
Text
Parole chiave che riassumono il set di dati. |
license
|
URL o CreativeWork
La licenza applicata alla distribuzione del set di dati. Ad esempio: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Linee guida aggiuntive
|
measurementTechnique
|
Text o URL
La tecnica, la tecnologia o la metodologia utilizzate in un set di dati, che possono corrispondere alla variabile o alle variabili descritte in |
sameAs
|
URL
L'URL di una pagina web di riferimento che indica in modo univoco l'identità del set di dati. |
spatialCoverage |
Text o Place
Puoi fornire un singolo punto che descrive l'aspetto spaziale del set di dati. Includi questa proprietà solo se il set di dati ha una dimensione spaziale. Ad esempio, un singolo punto in cui sono state raccolte tutte le misurazioni o le coordinate di un riquadro di delimitazione per un'area. Punti "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Forme Utilizza "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } I punti all'interno delle proprietà Località con nome "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
I dati nel set di dati riguardano un intervallo di tempo specifico. Includi questa proprietà solo se il set di dati ha una dimensione temporale. Schema.org utilizza lo standard ISO 8601 per descrivere intervalli di tempo e punti temporali. Puoi descrivere le date in modo diverso a seconda dell'intervallo del set di dati. Indica intervalli aperti con due punti decimali ( Data unica "temporalCoverage" : "2008" Periodo di tempo "temporalCoverage" : "1950-01-01/2013-12-18" Periodo di tempo aperto "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text o PropertyValue
La variabile misurata da questo set di dati. Ad esempio, temperatura o pressione. |
version
|
Text o Number
Il numero di versione del set di dati. |
url
|
URL
Posizione di una pagina che descrive il set di dati. |
DataCatalog
La definizione completa di DataCatalog è disponibile all'indirizzo
schema.org/DataCatalog.
I set di dati sono spesso pubblicati in repository che contengono molti altri set di dati. Uno stesso set di dati può essere incluso in più repository. Puoi fare riferimento a un catalogo dati a cui appartiene questo set di dati mediante riferimento diretto tramite le seguenti proprietà:
| Proprietà consigliate | |
|---|---|
includedInDataCatalog
|
DataCatalog
Il catalogo a cui appartiene il set di dati.
|
DataDownload
La definizione completa di DataDownload è disponibile all'indirizzo
schema.org/DataDownload. Oltre alle proprietà Dataset, aggiungi le seguenti proprietà per i set di dati che offrono opzioni di download.
La proprietà distribution descrive come ottenere il set di dati perché l'URL punta spesso alla pagina di destinazione che descrive il set di dati. La proprietà distribution indica dove scaricare i dati e in quale formato. Questa proprietà può
avere diversi valori: ad esempio, la versione CSV è disponibile a un URL e la versione Excel
è disponibile a un altro URL.
| Proprietà obbligatorie | |
|---|---|
distribution.contentUrl
|
URL
Il link per il download. |
| Proprietà consigliate | |
|---|---|
distribution
|
DataDownload
La descrizione della posizione per il download del set di dati e il formato file per il download.
|
distribution.encodingFormat
|
Text o URL
Il formato file della distribuzione.
|
Set di dati tabulari
Un set di dati tabulare è organizzato principalmente in termini di una griglia di righe e colonne. Per le pagine che incorporano set di dati tabulari, puoi anche creare un markup più esplicito, facendo riferimento all'approccio di base. Al momento supportiamo una variante di CSVW ("CSV sul Web", vedi W3C), offerta in parallelo ai contenuti tabulari lato utente nella pagina HTML.
Ecco un esempio che mostra una piccola tabella codificata in formato JSON-LD CSVW. Sono presenti alcuni errori noti nello strumento di Test dei risultati avanzati.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Monitorare i risultati avanzati con Search Console
Search Console è uno strumento che consente di monitorare il rendimento delle tue pagine in Ricerca Google. Registrarsi in Search Console non è obbligatorio per essere inclusi nei risultati di Ricerca Google, ma può aiutarti a capire e migliorare il modo in cui Google vede il tuo sito. Ti consigliamo di controllare Search Console nei seguenti casi:
- Dopo aver effettuato il deployment dei dati strutturati per la prima volta
- Dopo aver rilasciato nuovi modelli o aggiornato il codice
- Analisi periodica del traffico
Dopo aver effettuato il deployment dei dati strutturati per la prima volta
Dopo che Google ha indicizzato le tue pagine, cerca i problemi utilizzando il report sullo stato dei risultati avanzati pertinente. L'ideale sarebbe un aumento degli elementi validi e nessun aumento di quelli non validi. Se riscontri problemi nei dati strutturati:
- Correggi gli elementi non validi.
- Controlla un URL pubblicato per verificare se il problema persiste.
- Richiedi la convalida utilizzando il report sullo stato.
Dopo aver rilasciato nuovi modelli o aggiornato il codice
Quando apporti modifiche significative al tuo sito web, monitora l'aumento degli elementi non validi relativi ai dati strutturati.- Se vedi un aumento di errori, forse hai reso disponibile un nuovo modello non funzionante oppure il tuo sito interagisce con il modello esistente in modo nuovo, ma non corretto.
- Se noti una diminuzione degli elementi validi (non associata a un aumento di quelli non validi), forse non stai più incorporando dati strutturati nelle tue pagine. Utilizza lo strumento Controllo URL per scoprire la causa del problema.
Analisi periodica del traffico
Analizza il traffico di Ricerca Google utilizzando il rapporto sul rendimento. I dati mostrano la frequenza con cui la pagina viene visualizzata nei risultati multimediali nella Ricerca, la frequenza con cui gli utenti fanno clic e qual è la posizione media che visualizzi nei risultati di ricerca. Puoi anche estrarre automaticamente questi risultati con l'API Search Console.Risoluzione dei problemi
Se hai difficoltà con l'implementazione o il debug dei dati strutturati, ecco alcune risorse che potrebbero esserti utili.
- Se utilizzi un sistema di gestione dei contenuti (CMS) o un'altra persona si sta occupando del tuo sito, chiedile di aiutarti. Assicurati di inoltrarle gli eventuali messaggi di Search Console che illustrano il problema.
- Google non garantisce che le funzionalità che utilizzano dati strutturati vengano visualizzate nei risultati di ricerca. Per un elenco delle cause comuni per cui i tuoi contenuti potrebbero non essere mostrati da Google in un risultato avanzato consulta le linee guida generali sui dati strutturati.
- I tuoi dati strutturati potrebbero contenere un errore. Consulta l'elenco degli errori nei dati strutturati e il report sui dati strutturati non analizzabili.
- Se i dati strutturati della tua pagina sono interessati da un'azione manuale, i dati strutturati sulla pagina verranno ignorati (sebbene la pagina possa ancora essere visualizzata nei risultati della Ricerca Google). Per risolvere i problemi relativi ai dati strutturati, utilizza il report Azioni manuali.
- Consulta nuovamente le linee guida per verificare se i tuoi contenuti non sono conformi. Il problema può essere causato dall'utilizzo di contenuti di spam o di markup di spam. Tuttavia, il problema potrebbe non riguardare la sintassi e perciò non essere identificato dal Test dei risultati avanzati.
- Risolvi i problemi relativi a risultati avanzati mancanti o a un calo del numero totale di risultati avanzati.
- Lascia del tempo per le nuove operazioni di scansione e indicizzazione. Ricorda che possono passare diversi giorni dopo la pubblicazione di una pagina prima che Google la rilevi e la sottoponga a scansione. Per domande generali sulla scansione e sull'indicizzazione, consulta le Domande frequenti (FAQ) relative alla scansione e all'indicizzazione della Ricerca Google.
- Pubblica una domanda nel forum di Google Search Central.
Il set di dati specifico non viene visualizzato nei risultati di Ricerca per set di dati
error Che cosa ha causato il problema: il sito non ha dati strutturati nella pagina che descrive i set di dati oppure non è stata ancora eseguita la scansione della pagina.
done Risoluzione del problema
- Copia il link della pagina che ti aspetti di vedere nei risultati di Ricerca per set di dati e inseriscilo nello strumento di Test dei risultati avanzati. Se viene visualizzato il messaggio "La pagina non è idonea per i risultati avanzati rilevati da questo test" o "Non tutto il markup è idoneo per i risultati avanzati", significa che la pagina non contiene alcun markup Dataset oppure che il markup è errato. Per risolvere il problema, fai riferimento alla sezione Come aggiungere dati strutturati.
- Se la pagina include markup, è possibile che non sia stata ancora sottoposta a scansione. Puoi controllare lo stato della scansione con Search Console.
Il logo dell'azienda manca oppure non viene visualizzato correttamente nei risultati
error Che cosa ha causato il problema: nella pagina potrebbe mancare il markup schema.org relativo ai loghi delle organizzazioni oppure non hai definito le informazioni della tua attività su Google.
done Risoluzione del problema
- Aggiungi i dati strutturati per i loghi alla tua pagina.
- Definisci le informazioni della tua attività su Google.