
Die Funktion PLACES_COUNT_V2 gibt eine BigQuery-Tabelle mit Ortszahlen und Beispiel-Orts-IDs für mehrere Eingabegeografien basierend auf den angegebenen Filtern zurück.
Diese Funktion ist für die effiziente Batchverarbeitung konzipiert. Sie akzeptiert einen Eingabetabellenparameter
für Geografien, sodass Sie viele Interessengebiete in einer einzigen Abfrage analysieren können,
indem Sie die Geografien über eine Eingabetabelle bereitstellen.
Syntax
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_V2`( TABLE input_geographies, filters )
Parameter
PROJECT_NAME: Der Name Ihres Google Cloud-Projekts.LINKED_DATASET_NAME: Der Name des BigQuery-Datasets, das die Places Insights-Funktionen enthält (z.B.places_insights___us).input_geographies: Eine BigQuery-Tabelle mit den zu analysierenden Geografien. Diese Tabelle muss die folgenden Spalten enthalten:filters(JSON): Ein JSON-Objekt mit Schlüssel-Wert-Paaren zum Filtern der Orte. Weitere Informationen finden Sie unter Filterparameter.
Ausgabetabellenschema
Die Funktion PLACES_COUNT_V2 gibt eine Tabelle mit den folgenden Spalten zurück:
| Spaltenname | Datentyp | Beschreibung |
|---|---|---|
geo_id |
STRING | Die eindeutige ID für die Eingabegeografie aus der Tabelle input_geographies. |
input_geography |
GEOGRAPHY | Das ursprüngliche GEOGRAPHY-Objekt aus der Tabelle input_geographies. |
place_count |
INTEGER | Die Gesamtzahl der Orte, die den Filtern entsprechen. |
sample_place_ids |
ARRAY<STRING> | Ein Array mit bis zu 250 Orts-IDs, die den Kriterien entsprechen. |
Funktionsweise
Die Funktion verarbeitet jede Zeile in der Tabelle input_geographies. Für jedes geo
Objekt wird die Anzahl der Orte gezählt, die sich innerhalb der Geografie (oder innerhalb von
der geography_radius, wenn das geo ein Punkt ist und der Radius in
den filters angegeben ist) befinden. Die Zählung umfasst nur Orte, die alle
im JSON-Objekt filters definierten Bedingungen erfüllen.
Beispiel: Anzahl der Restaurants in drei Bezirken von New York City berechnen
In diesem Beispiel wird eine Tabelle mit der Anzahl der Restaurants in drei Bezirken von New York City erstellt.
In diesem Beispiel wird das United States Census Bureau
Data
BigQuery öffentliche Dataset verwendet, um
die Grenzen für drei Bezirke in New York City zu ermitteln: "Queens", "Kings", und "New
York". Die Grenzen der einzelnen Bezirke sind in der Spalte county_geom enthalten.
Zuerst erstellen wir eine temporäre Tabelle new_york_counties, die die geo_id und die vereinfachte GEOGRAPHY für jeden Bezirk enthält.
SELECT * FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), JSON_OBJECT( 'types', ["restaurant"], 'business_status', ['OPERATIONAL'] ) );
Die Antworttabelle enthält drei Zeilen, eine für jeden Bezirk, mit der geo_id, input_geography, place_count und sample_place_ids der Restaurants.
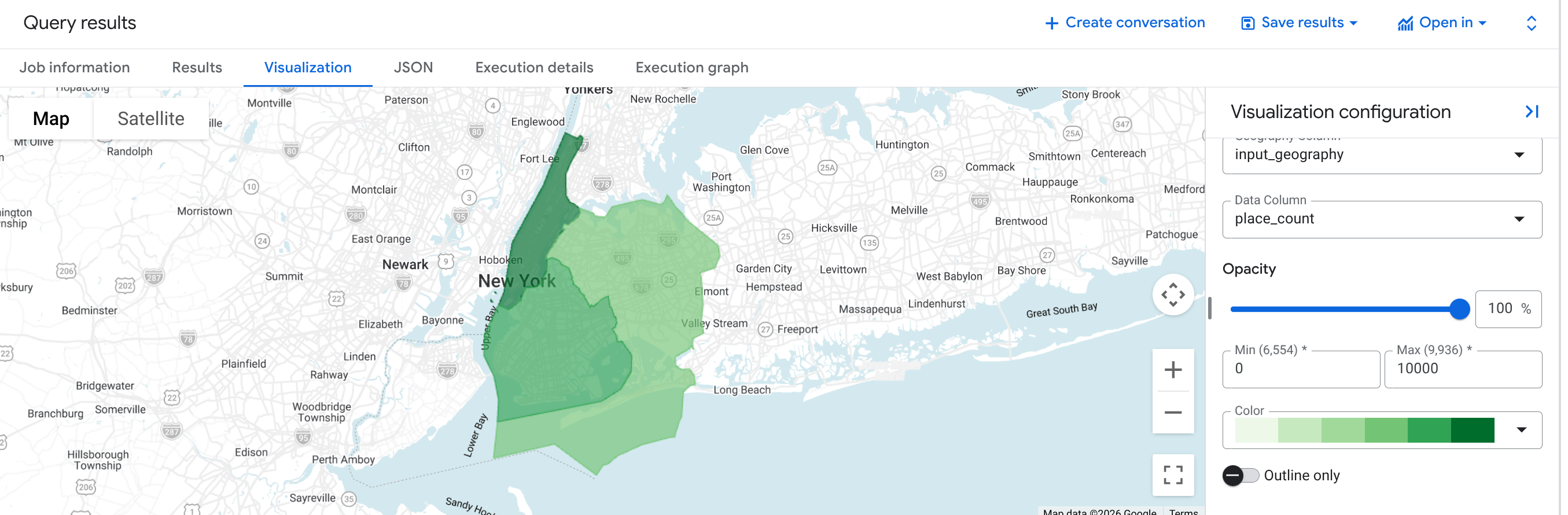
Vorteile der Verwendung von PLACES_COUNT_V2
PLACES_COUNT_V2 bietet erhebliche Vorteile gegenüber PLACES_COUNT und
PLACES_COUNT_PER_GEO:
- Batchverarbeitung:Analysieren Sie effizient Tausende von benutzerdefinierten Geografien in einer einzigen Abfrage, indem Sie mehrere Geografieeingaben in einer Tabelle bereitstellen.
- Leistung: Nutzt die optimierten räumlichen Joins von BigQuery , die bei großen Datasets erhebliche Geschwindigkeitsvorteile bieten.
- Skalierbarkeit:Kann eine große Anzahl von Eingabegeografien verarbeiten, ohne die Einschränkungen der Größe einzelner JSON-Parameter.
- Nullwerte enthalten:
PLACES_COUNT_V2gibt für jede in der Eingabetabelle angegebenegeo_ideine Zeile zurück. Wenn keine Orte den Kriterien für eine bestimmte Geografie entsprechen, istplace_countgleich 0. So erhalten Sie für jeden Eingabebereich ein Ergebnis und können sehen, wo keine Orte vorhanden sind.