
PLACES_COUNT_PER_TYPE_V2 함수는 여러 입력 지역에 대해 장소 유형별로 분류된 장소 수와 샘플 장소 ID가 포함된 BigQuery 테이블을 반환합니다. 이 함수는 지역의 입력 테이블 매개변수를 수락하여 효율적인 일괄 처리를 위해 설계되었습니다. 입력 테이블을 통해 지역을 제공하고 장소 유형을 배열로 지정합니다.
구문
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_PER_TYPE_V2`( TABLE input_geographies, target_types, filters )
매개변수
PROJECT_NAME: Google Cloud 프로젝트 이름입니다.LINKED_DATASET_NAME: 장소 통계 함수가 포함된 BigQuery 데이터 세트의 이름입니다 (예:places_insights___us).input_geographies: 분석할 지역이 포함된 BigQuery 테이블입니다. 이 테이블에는 다음 열이 포함 되어야 합니다.target_types(ARRAY<STRING>): 개수를 가져오려는 장소 유형 문자열의 배열입니다. 장소는primary_type뿐만 아니라types배열에 나열된 유형 중 하나 와 일치하는 경우에만 집계됩니다.filters(JSON): 장소를 추가로 필터링하기 위한 키-값 쌍이 포함된 JSON 객체입니다. 필터 매개변수를 참고하세요.
출력 테이블 스키마
PLACES_COUNT_PER_TYPE_V2 함수는 다음 열이 포함된 테이블을 반환합니다.
| 열 이름 | 데이터 유형 | 설명 |
|---|---|---|
geo_id |
STRING | input_geographies 테이블의 입력 지역에 대한 고유 식별자입니다. |
input_geography |
GEOGRAPHY | input_geographies 테이블의 원래 GEOGRAPHY 객체입니다. |
place_type |
STRING | 이 행이 나타내는 target_types 배열의 장소 유형입니다. |
place_count |
INTEGER | 지역 내 또는 지역 근처에서 place_type 및 기타 필터와 일치하는 장소의 수입니다. |
sample_place_ids |
ARRAY<STRING> | 이 유형 및 지역의 기준과 일치하는 최대 250개의 장소 ID 배열입니다. |
개수가 0인 경우에도 target_types 배열에 지정된 geo_id 및 place_type의 각 조합에 대한 행이 출력에 포함됩니다.
작동 방식
이 함수는 input_geographies 테이블에 제공된 각 지역을 처리합니다.
각 지역에 대해 target_types 배열에 나열된 유형 중 하나 와 일치하고 filters JSON 객체의 모든 조건을 충족하는 장소를 집계합니다. 결과는 geo_id 및 target_types의 각 유형별로 집계되고 분류됩니다.
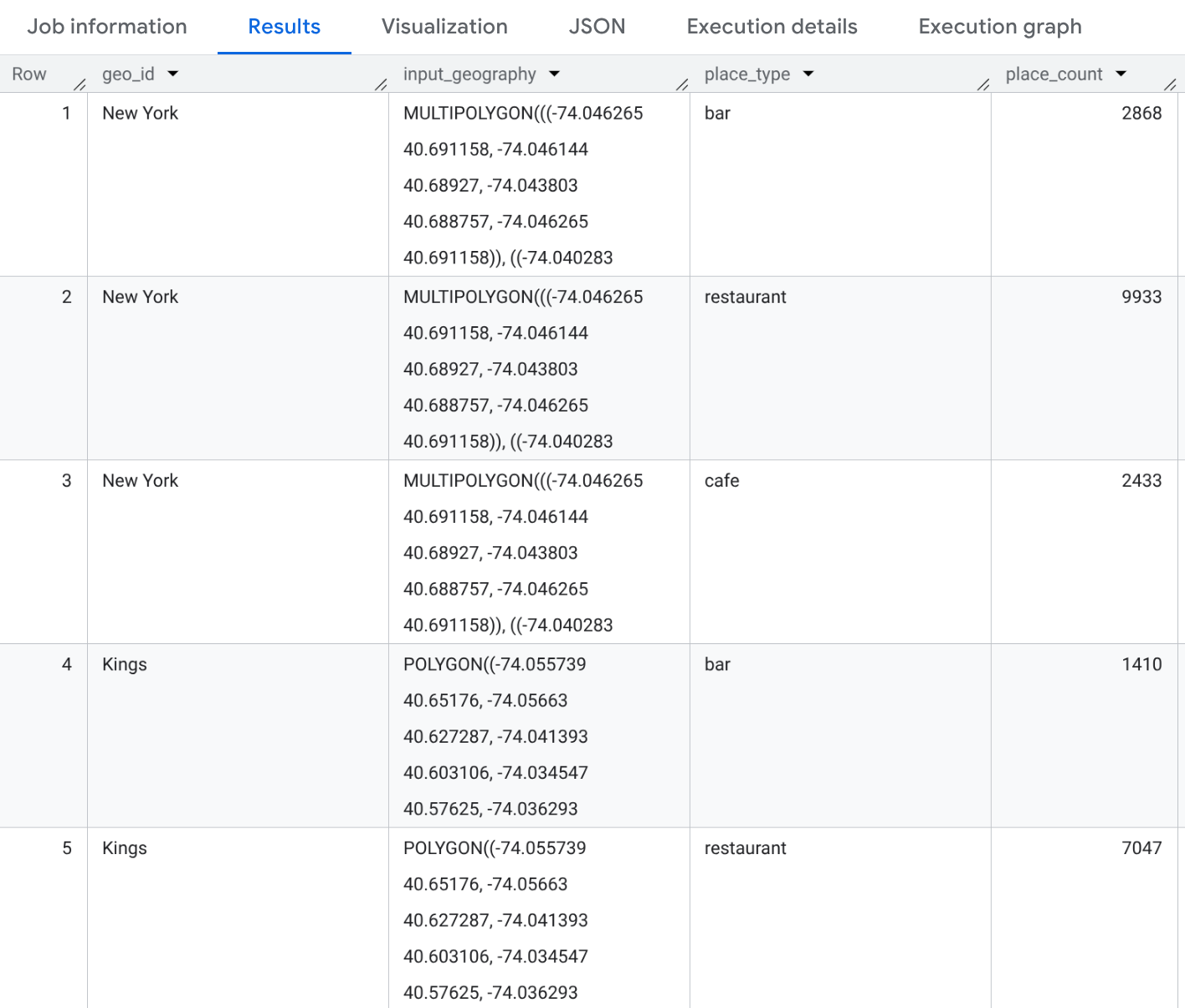
예: 뉴욕시 카운티의 다양한 유형의 음식점 집계
이 예에서는 뉴욕시 3개 카운티의 'restaurant', 'cafe', 'bar' 유형의 개수 테이블을 생성합니다.
SELECT geo_id, input_geography, place_type, place_count FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), ['restaurant', 'cafe', 'bar'], -- target_types JSON_OBJECT( 'business_status', ['OPERATIONAL'] ) );
결과는 9개의 행 (3개 카운티 * 3개 유형)이 있는 테이블입니다. 각 행에는 각 카운티 내 'restaurant', 'cafe' 또는 'bar' 업체의 개수가 표시됩니다. SELECT 문에 샘플 장소 ID를 추가하면 샘플 장소 ID를 포함할 수도 있습니다.
PLACES_COUNT_PER_TYPE_V2 사용의 이점
PLACES_COUNT_PER_TYPE_V2는 특히 이전 PLACES_COUNT_PER_TYPE 함수와 비교할 때 다음과 같은 몇 가지 주요 이점을 제공합니다.
- 지역 일괄 처리: 한 번에 하나의 지역을 처리하는
PLACES_COUNT_PER_TYPE와 달리PLACES_COUNT_PER_TYPE_V2는 입력 지역의TABLE을 허용합니다. 따라서 여러 함수 호출을 하는 대신 단일 쿼리에서 여러 지역 (점, 다각형)에 걸쳐 유형별 개수를 분석하고 가져올 수 있습니다. - 향상된 성능 및 확장성: 테이블 입력을 사용하면
PLACES_COUNT_PER_TYPE_V2제공된 모든 지역에서 BigQuery의 최적화된 지리공간 조인 및 병렬 처리 기능을 동시에 활용할 수 있습니다. 따라서 많은 지역을 처리할 때 성능이 크게 개선되고 확장성이 향상됩니다. - 0개 개수 포함: 일괄 처리 내 특정 지역에서 찾을 수 없는 유형에 대해 개수가 0인 행을 반환하여 모든 유형-지역 조합에 대한 완전한 결과 세트를 보장합니다.