
PLACES_COUNT_PER_TYPE_V2 関数は、複数の入力地域について、プレイスのタイプ別に分類されたプレイスの数とサンプル プレイス ID を含む BigQuery テーブルを返します。この関数は、地域情報の入力テーブル パラメータを受け取り、効率的なバッチ処理を行うように設計されています。地域は入力テーブルで指定し、場所のタイプは配列として指定します。
構文
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_PER_TYPE_V2`( TABLE input_geographies, target_types, filters )
パラメータ
PROJECT_NAME: Google Cloud Platform プロジェクトの名前です。LINKED_DATASET_NAME: Places Insights 関数を含む BigQuery データセットの名前(例:places_insights___us)。input_geographies: 分析する地域を含む BigQuery テーブル。このテーブルには、次の列が必要です。target_types(ARRAY<STRING>): カウントを取得する場所のタイプ文字列の配列。場所は、primary_typeだけでなく、types配列にリストされているタイプのいずれかと一致する場合にカウントされます。filters(JSON): 場所の追加フィルタリング用の Key-Value ペアを含む JSON オブジェクト。フィルタ パラメータをご覧ください。
出力テーブル スキーマ
PLACES_COUNT_PER_TYPE_V2 関数は、次の列を含むテーブルを返します。
| 列名 | データ型 | 説明 |
|---|---|---|
geo_id |
STRING | input_geographies テーブルの入力地理情報の一意の識別子。 |
input_geography |
GEOGRAPHY | input_geographies テーブルの元の GEOGRAPHY オブジェクト。 |
place_type |
STRING | この行が表す target_types 配列のプレイスタイプ。 |
place_count |
INTEGER | place_type と他のフィルタに一致する場所の数(地理的範囲内またはその付近)。 |
sample_place_ids |
ARRAY<STRING> | このタイプと地域条件に一致するプレイス ID の配列(最大 250 個)。 |
出力には、target_types 配列で指定された geo_id と place_type の組み合わせごとに 1 行が含まれます(カウントがゼロの場合でも)。
仕組み
この関数は、input_geographies テーブルで指定された各地域を処理します。各地域について、target_types 配列にリストされているタイプのいずれかに一致し、filters JSON オブジェクトのすべての条件を満たす場所の数をカウントします。結果は集計され、geo_id ごと、target_types のタイプごとに分類されます。
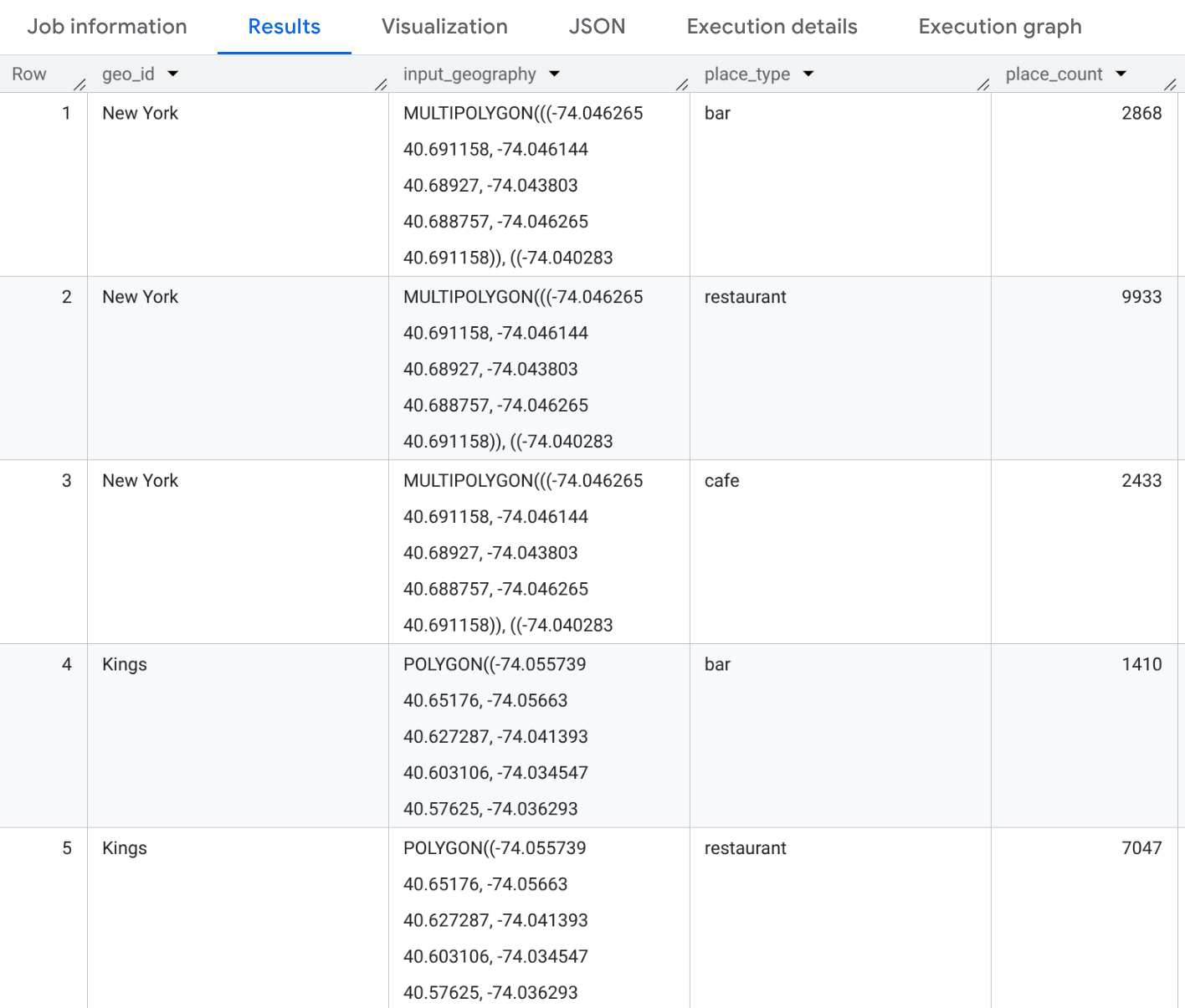
例: ニューヨーク市の郡にあるさまざまな種類の飲食店を数える
この例では、ニューヨーク市の 3 つの郡で「レストラン」、「カフェ」、「バー」の種類の数を表すテーブルを生成します。
SELECT geo_id, input_geography, place_type, place_count FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), ['restaurant', 'cafe', 'bar'], -- target_types JSON_OBJECT( 'business_status', ['OPERATIONAL'] ) );
結果は 9 行(3 つの郡 × 3 つのタイプ)のテーブルになります。各行には、郡ごとの「レストラン」、「カフェ」、「バー」の数が表示されます。SELECT ステートメントに追加すると、プレイス ID のサンプルを含めることもできます。
PLACES_COUNT_PER_TYPE_V2 を使用するメリット
PLACES_COUNT_PER_TYPE_V2 には、特に古い PLACES_COUNT_PER_TYPE 関数と比較して、次のような主なメリットがあります。
- Geography のバッチ処理:
PLACES_COUNT_PER_TYPEは一度に 1 つの geography を処理しますが、PLACES_COUNT_PER_TYPE_V2は入力 geography のTABLEを受け入れます。これにより、複数の関数呼び出しを行うのではなく、1 つのクエリで複数の地域(ポイント、ポリゴン)にわたるタイプ固有のカウントを分析して取得できます。 - パフォーマンスとスケーラビリティの向上: テーブル入力を取得することで、
PLACES_COUNT_PER_TYPE_V2は、提供されているすべての地域で BigQuery の最適化された地理空間結合と並列処理機能を同時に活用できます。これにより、パフォーマンスが大幅に向上し、多数の地域を扱う際のスケーラビリティが向上します。 - ゼロカウントを含む: バッチ内の特定の地域で見つからなかったタイプについて、カウントが 0 の行を返します。これにより、すべてのタイプと地域の組み合わせについて完全な結果セットが保証されます。