
The PLACES_COUNT_PER_TYPE_V2 function returns a BigQuery table containing
place counts and sample Place IDs, broken down by place type, for multiple
input geographies. This function is designed for efficient batch processing by
accepting an input table parameter
of geographies. You provide the geographies through an input table and specify
the place types as an array.
Syntax
SELECT * FROM `PROJECT_NAME.LINKED_DATASET_NAME.PLACES_COUNT_PER_TYPE_V2`( TABLE input_geographies, target_types, filters )
Parameters
PROJECT_NAME: The name of your Google Cloud project.LINKED_DATASET_NAME: The name of the BigQuery dataset containing the Places Insights functions (e.g.,places_insights___us).input_geographies: A BigQuery table containing the geographies to analyze. This table must include the following columns:target_types(ARRAY<STRING>): An array of place type strings you want to get counts for. Places will be counted if they match any of the types listed in theirtypesarray, not just theprimary_type.filters(JSON): A JSON object containing key-value pairs for additional filtering of the places. See Filter Parameters.
Output Table Schema
The PLACES_COUNT_PER_TYPE_V2 function returns a table with the following
columns:
| Column Name | Data Type | Description |
|---|---|---|
geo_id |
STRING | The unique identifier for the input geography, from the input_geographies table. |
input_geography |
GEOGRAPHY | The original GEOGRAPHY object from the input_geographies table. |
place_type |
STRING | The place type from the target_types array this row represents. |
place_count |
INTEGER | The number of places matching the place_type and other filters within or near the geography. |
sample_place_ids |
ARRAY<STRING> | An array of up to 250 Place IDs that match the criteria for this type and geography. |
The output will contain a row for each combination of geo_id and place_type
specified in the target_types array, even if the count is zero.
How it works
The function processes each geography provided in the input_geographies table.
For each geography, it counts places that match any of the types listed in
the target_types array and also satisfy all conditions in the filters
JSON object. The results are aggregated and broken down by each geo_id and
each type in target_types.
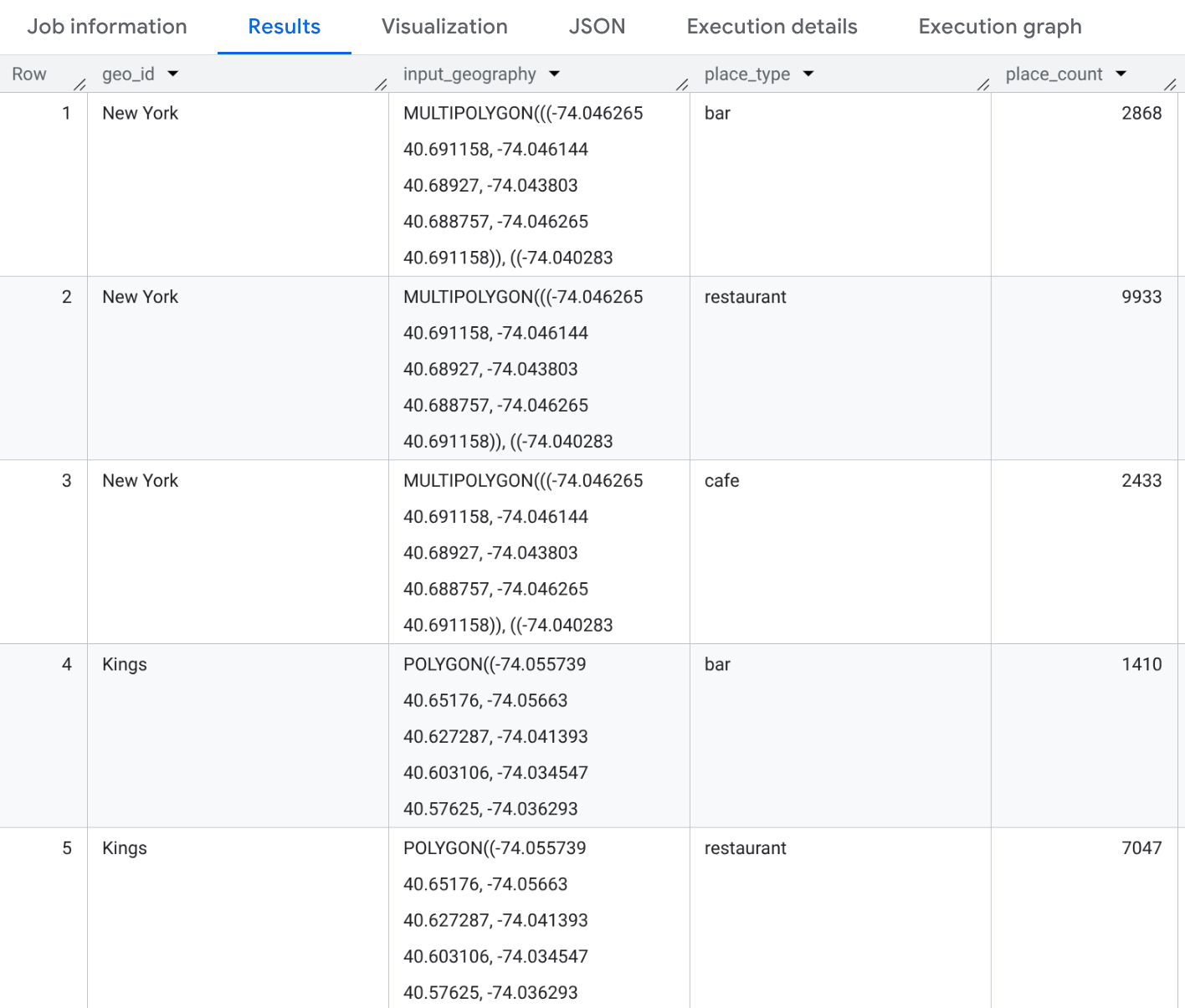
Example: Count different types of eateries in NYC Counties
This example generates a table of counts for "restaurant", "cafe", and "bar" types across three New York City counties.
SELECT geo_id, input_geography, place_type, place_count FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE_V2`( ( SELECT county_name AS geo_id, ST_SIMPLIFY(county_geom, 100) AS geo FROM `bigquery-public-data.geo_us_boundaries.counties` WHERE state_fips_code = "36" -- New York State AND county_name IN ("Queens", "Kings", "New York") ), ['restaurant', 'cafe', 'bar'], -- target_types JSON_OBJECT( 'business_status', ['OPERATIONAL'] ) );
The result will be a table with 9 rows (3 counties * 3 types). Each row will show the count of "restaurant", "cafe", or "bar" establishments within each county. You can also include sample Place IDs if you add it to your SELECT statement.
Benefits of Using PLACES_COUNT_PER_TYPE_V2
PLACES_COUNT_PER_TYPE_V2 offers several key advantages, particularly when
compared to the older PLACES_COUNT_PER_TYPE function:
- Batch Processing of Geographies: Unlike
PLACES_COUNT_PER_TYPEwhich processes one geography at a time,PLACES_COUNT_PER_TYPE_V2accepts aTABLEof input geographies. This lets you analyze and get type-specific counts across numerous geographies (points, polygons) in a single query, instead of making multiple function calls. - Enhanced Performance and Scalability: By taking a table input,
PLACES_COUNT_PER_TYPE_V2can take advantage of BigQuery's optimized geospatial joins and parallel processing capabilities across all provided geographies simultaneously. This results in significant performance improvements and better scalability when dealing with a large number of geographies. - Zero Counts Included: Returns rows with 0 counts for types not found in a specific area within the batch, ensuring a complete result set for all type-geography combinations.