
本文档将介绍如何使用地点概览中的示例地点 ID 数据,同时使用地点计数函数和有针对性的地点详情查找来提高结果的可信度。
如需查看此模式的详细参考实现,请参阅以下说明性笔记本:
 在 GitHub 上查看源代码
在 GitHub 上查看源代码
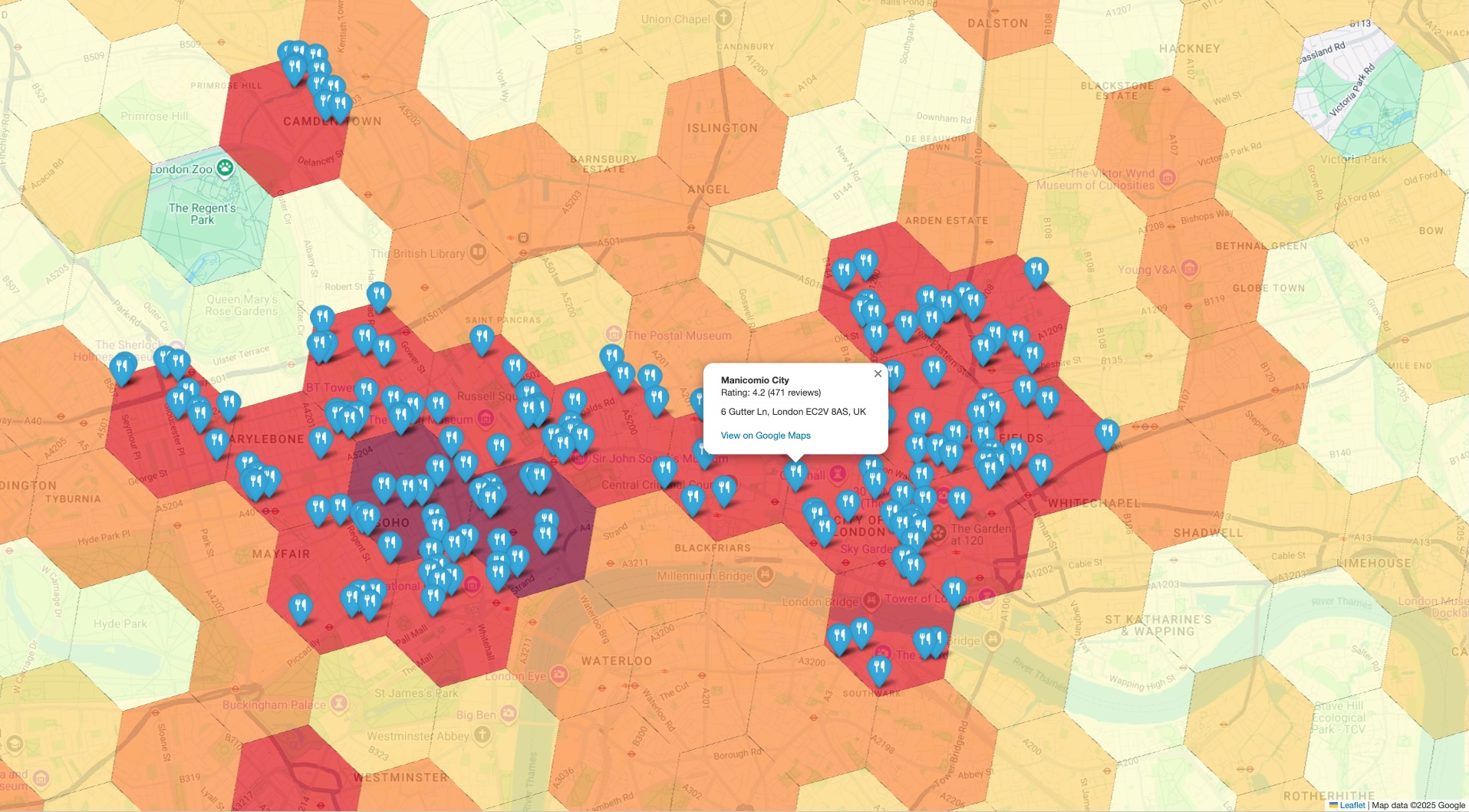
架构模式
此架构模式可为您提供一个可重复的工作流,以弥合高级统计分析与实际验证之间的差距。通过将 BigQuery 的规模与 Places API 的精确度相结合,您可以放心地验证分析结果。这对于选址、竞争对手分析和市场调研尤其有用,因为在这些方面,对数据的信任至关重要。
此模式的核心涉及四个关键步骤:
- 执行大规模分析:使用 BigQuery 中地点概览的地点数量函数,分析大范围地理区域(例如整个城市或地区)的地点数据。
- 隔离和提取样本:从汇总结果中识别感兴趣的区域(例如,高密度“热点”),并提取函数提供的
sample_place_ids。 - 检索标准答案详情:使用提取的地点 ID 向地点详情 API 发出有针对性的调用,以获取每个地点的丰富真实世界详情。
- 创建组合可视化图表:将详细地点数据叠加在初始的高级统计地图上,以直观验证汇总统计数据是否反映了实际情况。
解决方案工作流
此工作流可帮助您弥合宏观趋势与微观事实之间的差距。您首先会从宏观的统计视角入手,然后有策略地向下钻取,通过具体的实际示例来验证数据。
使用 Places Insights 大规模分析地点密度
第一步是大致了解当前形势。您无需提取数千个单独的兴趣点 (POI),只需运行一个查询即可获得统计摘要。
Places Insights PLACES_COUNT_PER_H3 函数非常适合这种情况。该工具会将 POI 数量汇总到六边形网格系统 (H3) 中,以便您根据特定条件(例如营业中的高评分餐厅)快速确定高密度或低密度区域。
以下是一个查询示例。请注意,您需要提供搜索区域的地理位置。开放数据集(例如 Overture Maps Data BigQuery 公共数据集)可用于检索地理边界数据。
对于经常使用的开放数据集边界,我们建议将其具体化为您自己项目中的一个表。这可显著降低 BigQuery 费用并提高查询性能。
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
按品牌 ID 进行过滤和验证
如果您想验证特定品牌的数量和样本放置 ID,请使用 brand_ids 过滤条件提供品牌 ID 列表。
如需获取目标品牌的品牌 ID,请在 BigQuery 中查询 brands 表:
SELECT id, name
FROM `YOUR_PROJECT.places_insights___us.brands`
WHERE LOWER(name) LIKE "%starbucks%";
检索目标品牌 ID(例如,星巴克的 ID 为 "1413758728321880760")后,将其传递到 brand_ids 过滤条件数组中:
SELECT *
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'brand_ids', ["1413758728321880760"]
)
);
在第 3 步(实况验证)中,您可以不确认某个地点是否与一般类别匹配,而是使用正则表达式匹配,以编程方式将 Place Details API 返回的显示名称与预期品牌名称进行比较。例如,您可以比较 response.display_name.text 字段。
此查询的输出结果是一个包含 H3 单元格和每个单元格内地点数量的表格,可作为密度热图的基础。
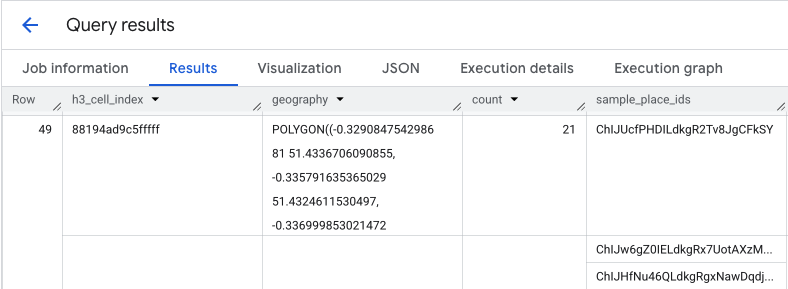
隔离热点并提取示例地点 ID
PLACES_COUNT_PER_H3 函数的结果还会返回一个 sample_place_ids 数组,每个响应元素最多包含 250 个地点 ID。这些 ID 是从汇总统计信息到促成该统计信息的各个地点的链接。
系统可以先从初始查询中找出最相关的单元格。
例如,您可以选择数量最多的前 20 个单元格。然后,您需要将这些热点中的 sample_place_ids 整合到单个列表中。此列表包含精选的示例,其中列出了最相关区域中最有趣的 POI,可帮助您做好有针对性的验证准备。
如果您使用 pandas DataFrame 在 Python 中处理 BigQuery 结果,则提取这些 ID 的逻辑非常简单:
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
如果使用其他编程语言,可以应用类似的逻辑。
使用 Places API 检索真实数据详情
获得整合的地点 ID 列表后,您现在可以从大规模分析过渡到特定数据检索。您将使用这些 ID 查询地点详情 API,以获取每个示例地点的详细信息。
这是一个关键的验证步骤。虽然 Places Insights 会告诉您某个区域有多少家餐厅,但 Places API 会告诉您这些餐厅是哪些,并提供它们的名称、确切地址、纬度/经度、用户评分,甚至还提供指向 Google 地图上相应位置的直接链接。这样可以丰富您的样本数据,将抽象 ID 转化为具体的可验证地点。
如需查看 Place Details API 提供的完整数据列表以及检索相关数据的费用,请查看 API 文档。
使用 Python 客户端库向 Places API 发出针对特定 ID 的请求,如下所示。如需了解详情,请参阅 Places API(新)客户端库示例。
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
请注意,此请求中的字段会从两个不同的结算 SKU 中提取数据。
formattedAddress和location属于地点详情精简版 SKU。displayName和googleMapsUri是地点详情专业版 SKU 的一部分。
如果单个“地点详情”请求包含多个 SKU 中的字段,则整个请求会按最高层级 SKU 的费率结算。因此,此特定调用将按“地点详情 Pro”请求结算。
为控制费用,请始终使用 FieldMask 仅请求应用所需的字段。
创建用于验证的组合可视化图表
最后一步是将这两个数据集合并到单个视图中。这样,您就可以立即以直观的方式对初始分析进行抽查。 您的可视化图表应包含两个图层:
- 基础层:根据初始的
PLACES_COUNT_PER_H3结果生成的等值线图或热图,显示整个地理区域内地点的总体密度。 - 顶层:一组用于表示每个示例 POI 的单独标记,使用在上一步中从 Places API 检索到的精确坐标绘制。
以下伪代码示例展示了构建此组合视图的逻辑:
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
通过将具体的实况标记叠加到高级密度地图上,您可以立即确认被标识为热点的区域实际上确实包含您正在分析的地点。这种直观的确认有助于建立对数据驱动型结论的信任。
总结
这种架构模式提供了一种可靠高效的方法来验证大规模地理空间数据洞见。通过利用 Places Insights 进行广泛的可扩缩分析,并利用 Place Details API 进行有针对性的标准答案验证,您可以创建一个强大的反馈环。这样可确保您的战略决策(无论是零售网站选择还是物流规划)不仅基于具有统计显著性的数据,还基于可验证的准确数据。
后续步骤
- 探索其他位置数函数,了解它们如何回答不同的分析问题。
- 请查看 Places API 文档,了解您可以请求哪些其他字段来进一步丰富分析。
贡献者
Henrik Valve | DevX 工程师