
ในเอกสารนี้ คุณจะได้เรียนรู้วิธีใช้ข้อมูลรหัสสถานที่ตัวอย่างจาก Places Insights โดยใช้ฟังก์ชันการนับสถานที่ ควบคู่ไปกับการค้นหารายละเอียด สถานที่เป้าหมายเพื่อสร้าง ความมั่นใจในผลลัพธ์
ดูการใช้งานรูปแบบนี้โดยละเอียดได้ที่ Notebook อธิบายนี้
 ดูแหล่งที่มาใน GitHub
ดูแหล่งที่มาใน GitHub
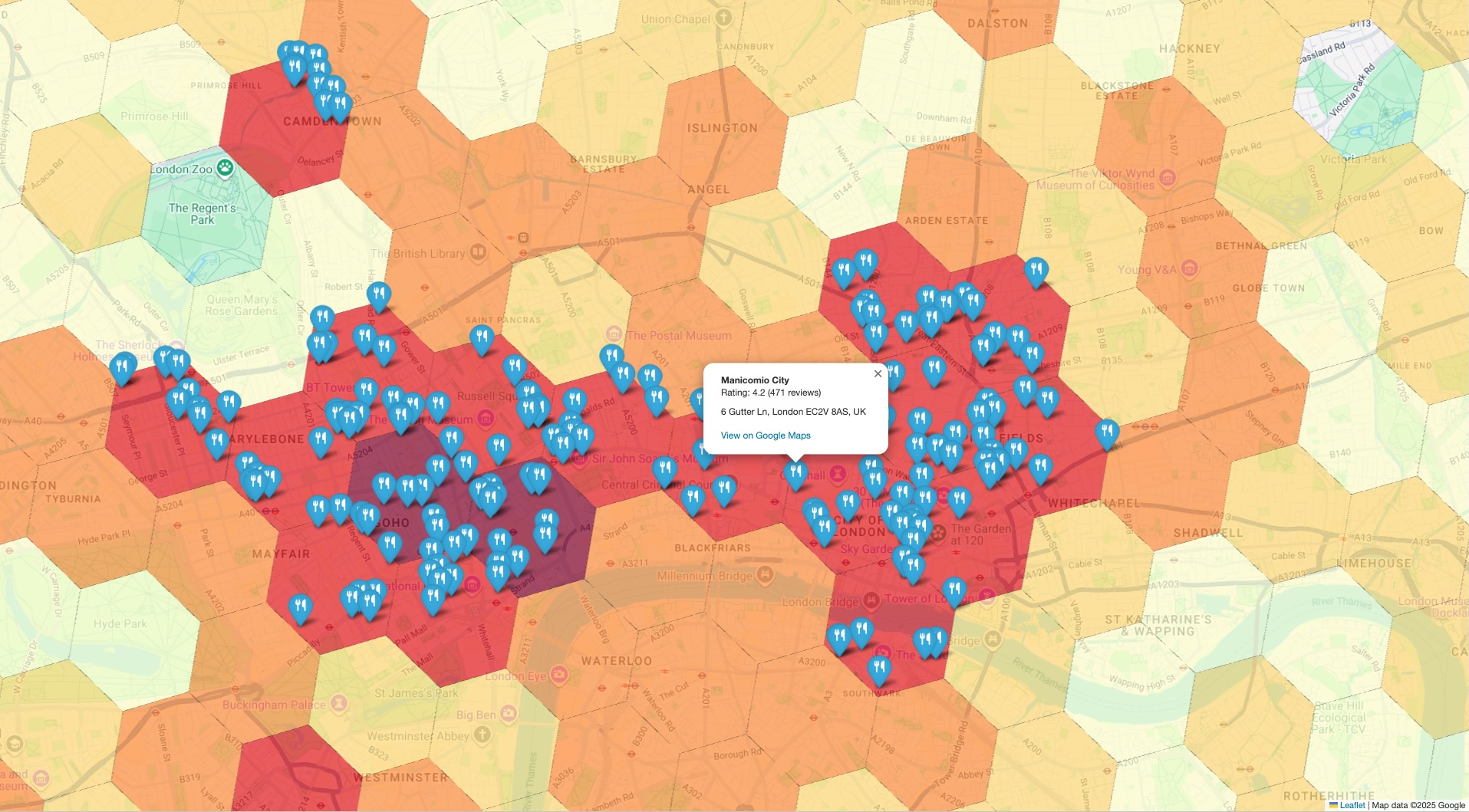
รูปแบบสถาปัตยกรรม
รูปแบบสถาปัตยกรรมนี้ช่วยให้คุณมีเวิร์กโฟลว์ที่ทำซ้ำได้เพื่อเชื่อมช่องว่าง ระหว่างการวิเคราะห์ทางสถิติระดับสูงกับการยืนยันความจริงภาคพื้นดิน การผสานความสามารถในการปรับขนาดของ BigQuery เข้ากับความแม่นยำของ Places API จะช่วยให้คุณตรวจสอบผลการวิเคราะห์ได้อย่างมั่นใจ ซึ่งมีประโยชน์อย่างยิ่งสำหรับ การเลือกสถานที่ การวิเคราะห์คู่แข่ง และการวิจัยตลาดที่ความน่าเชื่อถือของข้อมูล มีความสำคัญอย่างยิ่ง
หัวใจสำคัญของรูปแบบนี้เกี่ยวข้องกับขั้นตอนหลัก 4 ขั้นตอน ได้แก่
- ทำการวิเคราะห์ขนาดใหญ่: ใช้ฟังก์ชันการนับสถานที่ จากข้อมูลเชิงลึกเกี่ยวกับสถานที่ใน BigQuery เพื่อ วิเคราะห์ข้อมูลสถานที่ในพื้นที่ขนาดใหญ่ เช่น ทั้งเมืองหรือภูมิภาค
- แยกและดึงตัวอย่าง: ระบุพื้นที่ที่น่าสนใจ (เช่น
"ฮอตสปอต" ที่มีความหนาแน่นสูง) จากผลลัพธ์ที่รวบรวมไว้ แล้วดึง
sample_place_idsที่ฟังก์ชันระบุไว้ - ดึงรายละเอียดความจริงที่เชื่อถือได้: ใช้ Place IDs ที่ดึงออกมาเพื่อทำการเรียกที่กำหนดเป้าหมาย ไปยัง Place Details API เพื่อดึงรายละเอียดที่สมบูรณ์และ เป็นข้อมูลจริงสำหรับแต่ละสถานที่
- สร้างภาพข้อมูลรวม: วางซ้อนข้อมูลสถานที่แบบละเอียดไว้ด้านบน แผนที่สถิติระดับสูงเริ่มต้นเพื่อตรวจสอบด้วยภาพว่า จำนวนที่รวบรวมแล้วแสดงถึงความเป็นจริงในพื้นที่
เวิร์กโฟลว์ของโซลูชัน
เวิร์กโฟลว์นี้ช่วยให้คุณเชื่อมโยงช่องว่างระหว่างแนวโน้มระดับมหภาคกับข้อเท็จจริงระดับจุลภาคได้ คุณเริ่มต้นด้วยมุมมองทางสถิติในวงกว้างและเจาะลึกอย่างมีกลยุทธ์ เพื่อยืนยันข้อมูลด้วยตัวอย่างที่เฉพาะเจาะจงและเป็นจริง
วิเคราะห์ความหนาแน่นของสถานที่ในวงกว้างด้วยข้อมูลเชิงลึกเกี่ยวกับสถานที่
ขั้นตอนแรกคือการทำความเข้าใจภาพรวมในระดับสูง แทนที่จะ ดึงข้อมูลจุดที่น่าสนใจ (POI) หลายพันรายการ คุณสามารถเรียกใช้การ ค้นหาเพียงครั้งเดียวเพื่อรับข้อมูลสรุปทางสถิติ
ฟังก์ชันข้อมูลเชิงลึกเกี่ยวกับสถานที่ PLACES_COUNT_PER_H3
เหมาะสำหรับกรณีนี้
โดยจะรวบรวมจำนวนจุดที่น่าสนใจไว้ในระบบตารางหกเหลี่ยม
(H3) ซึ่งช่วยให้คุณระบุพื้นที่ที่มี
ความหนาแน่นสูงหรือต่ำได้อย่างรวดเร็วตามเกณฑ์ที่เฉพาะเจาะจง (เช่น ร้านอาหารที่มี
คะแนนสูงซึ่งเปิดให้บริการ)
ตัวอย่างคำค้นหามีดังนี้ โปรดทราบว่าคุณจะต้องระบุ พื้นที่ค้นหาทางภูมิศาสตร์ คุณใช้ชุดข้อมูลแบบเปิด เช่น ข้อมูล Overture Maps ชุดข้อมูลสาธารณะของ BigQuery เพื่อดึงข้อมูลขอบเขตทางภูมิศาสตร์ได้
สำหรับขอบเขตชุดข้อมูลแบบเปิดที่ใช้บ่อย เราขอแนะนำให้สร้างเป็นตารางในโปรเจ็กต์ของคุณเอง ซึ่งจะช่วยลดต้นทุน BigQuery และ ปรับปรุงประสิทธิภาพการค้นหาได้อย่างมาก
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
การกรองและการตรวจสอบตามรหัสแบรนด์
หากต้องการตรวจสอบจำนวนและรหัสสถานที่ตัวอย่างสำหรับแบรนด์ที่เฉพาะเจาะจง
ให้ระบุรายการรหัสแบรนด์โดยใช้ตัวกรอง brand_ids
หากต้องการรับรหัสแบรนด์สำหรับแบรนด์เป้าหมาย ให้ค้นหาตาราง brands ใน
BigQuery โดยใช้คำสั่งต่อไปนี้
SELECT id, name
FROM `YOUR_PROJECT.places_insights___us.brands`
WHERE LOWER(name) LIKE "%starbucks%";
หลังจากดึงรหัสแบรนด์เป้าหมาย (เช่น "1413758728321880760"
สำหรับ Starbucks) แล้ว ให้ส่งรหัสภายในอาร์เรย์ตัวกรอง brand_ids ดังนี้
SELECT *
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'brand_ids', ["1413758728321880760"]
)
);
ในขั้นตอนที่ 3 ซึ่งเป็นการยืนยันความจริงพื้นฐาน แทนที่จะยืนยันว่าสถานที่ตรงกับหมวดหมู่ทั่วไป คุณสามารถเปรียบเทียบชื่อที่แสดงที่ API รายละเอียดสถานที่ส่งคืนกับชื่อแบรนด์ที่คาดไว้โดยใช้การจับคู่ตามนิพจน์ทั่วไปได้โดยอัตโนมัติ
เช่น คุณสามารถเปรียบเทียบฟิลด์
response.display_name.textได้
เอาต์พุตของคําค้นหานี้จะแสดงตารางของเซลล์ H3 และจํานวนสถานที่ ภายในแต่ละเซลล์ ซึ่งเป็นพื้นฐานสําหรับแผนที่ความหนาแน่นแบบฮีทแมป
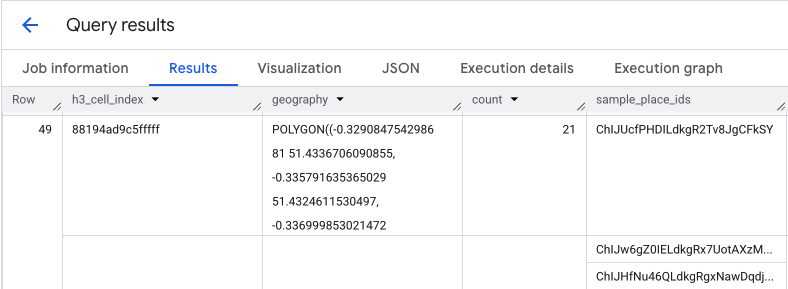
แยกฮอตสปอตและดึงรหัสสถานที่ตัวอย่าง
ผลลัพธ์จากฟังก์ชัน PLACES_COUNT_PER_H3 จะแสดงผลอาร์เรย์ของ sample_place_ids ด้วย โดยมีรหัสสถานที่สูงสุด 250 รายการต่อองค์ประกอบของการตอบกลับ รหัสเหล่านี้
คือลิงก์จากสถิติรวมไปยังสถานที่แต่ละแห่งที่
มีส่วนทำให้เกิดสถิตินั้น
ระบบอาจระบุเซลล์ที่เกี่ยวข้องมากที่สุดจากคำค้นหาเริ่มต้นก่อน
เช่น คุณอาจเลือก 20 เซลล์แรกที่มีจำนวนสูงสุด จากนั้น
จากฮอตสปอตเหล่านี้ ให้คุณรวบรวม sample_place_ids ไว้ในรายการเดียว
รายการนี้แสดงตัวอย่างจุดที่น่าสนใจที่สุดที่คัดสรรมาแล้วจากพื้นที่ที่เกี่ยวข้องมากที่สุด เพื่อเตรียมพร้อมสำหรับการยืนยันที่กำหนดเป้าหมาย
หากคุณประมวลผลผลลัพธ์ BigQuery ใน Python โดยใช้ DataFrame ของ pandas ตรรกะในการแยกรหัสเหล่านี้จะตรงไปตรงมา ดังนี้
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
คุณสามารถใช้ตรรกะที่คล้ายกันได้หากใช้ภาษาโปรแกรมอื่นๆ
เรียกดูรายละเอียดความจริงพื้นฐานด้วย Places API
เมื่อมีรายการรหัสสถานที่ที่รวมแล้ว ตอนนี้คุณก็เปลี่ยนจากข้อมูลวิเคราะห์ขนาดใหญ่ ไปเป็นการดึงข้อมูลที่เฉพาะเจาะจงได้แล้ว คุณจะใช้รหัสเหล่านี้เพื่อค้นหา Place Details API เพื่อดูข้อมูลโดยละเอียดเกี่ยวกับสถานที่ตัวอย่างแต่ละแห่ง
ขั้นตอนนี้เป็นขั้นตอนการตรวจสอบที่สำคัญ แม้ว่าข้อมูลเชิงลึกเกี่ยวกับสถานที่จะบอกจํานวนร้านอาหารในพื้นที่ แต่ Places API จะบอกว่าร้านอาหารใดที่อยู่ในพื้นที่นั้น โดยจะระบุชื่อ ที่อยู่ที่แน่นอน ละติจูด/ลองจิจูด คะแนนของผู้ใช้ และแม้แต่ลิงก์โดยตรงไปยังตำแหน่งของร้านอาหารใน Google Maps ซึ่งจะช่วยเพิ่มข้อมูลตัวอย่าง และเปลี่ยนรหัสที่เป็นนามธรรมให้เป็นสถานที่ที่จับต้องได้และยืนยันได้
ดูรายการข้อมูลทั้งหมดที่ใช้ได้จาก Place Details API และค่าใช้จ่าย ที่เกี่ยวข้องกับการดึงข้อมูลได้ที่เอกสารประกอบเกี่ยวกับ API
คำขอไปยัง Places API สำหรับรหัสที่เฉพาะเจาะจงโดยใช้ไลบรารีของไคลเอ็นต์ Python จะมีลักษณะดังนี้ ดูรายละเอียดเพิ่มเติมได้ที่ตัวอย่างไลบรารีของไคลเอ็นต์ Places API (ใหม่)
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
โปรดทราบว่าฟิลด์ในคำขอนี้ดึงข้อมูลจาก SKU การเรียกเก็บเงิน 2 รายการที่แตกต่างกัน
formattedAddressและlocationเป็นส่วนหนึ่งของ Place Details Essentials SKUdisplayNameและgoogleMapsUriเป็นส่วนหนึ่งของ Place Details Pro SKU
เมื่อคำขอรายละเอียดสถานที่รายการเดียวมีฟิลด์จาก SKU หลายรายการ ระบบจะเรียกเก็บเงินทั้งคำขอในอัตราของ SKU ระดับสูงสุด ดังนั้น ระบบจะเรียกเก็บเงินสำหรับการเรียกใช้เฉพาะนี้เป็นคำขอรายละเอียดสถานที่ Pro
หากต้องการควบคุมค่าใช้จ่าย ให้ใช้ FieldMask เสมอเพื่อขอเฉพาะฟิลด์ที่แอปพลิเคชันของคุณต้องการ
สร้างภาพรวมเพื่อการตรวจสอบ
ขั้นตอนสุดท้ายคือการรวมชุดข้อมูลทั้ง 2 ชุดไว้ในมุมมองเดียว ซึ่งเป็นวิธีที่รวดเร็วและใช้งานง่ายในการตรวจสอบการวิเคราะห์เบื้องต้น ภาพควรมี 2 เลเยอร์ดังนี้
- เลเยอร์ฐาน: แผนที่ Choropleth หรือฮีตแมปที่สร้างจากผลลัพธ์เริ่มต้น
PLACES_COUNT_PER_H3ซึ่งแสดงความหนาแน่นโดยรวมของสถานที่ต่างๆ ใน ภูมิศาสตร์ของคุณ - เลเยอร์บนสุด: ชุดเครื่องหมายแต่ละรายการสำหรับจุดที่น่าสนใจตัวอย่างแต่ละรายการ ซึ่งพล็อต โดยใช้พิกัดที่แน่นอนซึ่งดึงมาจาก Places API ในขั้นตอนก่อนหน้า
ตรรกะในการสร้างมุมมองแบบรวมนี้แสดงอยู่ในตัวอย่างรหัสเทียมต่อไปนี้
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
การวางเครื่องหมายความจริงภาคพื้นดินที่เฉพาะเจาะจงบนแผนที่ความหนาแน่นระดับสูง จะช่วยให้คุณยืนยันได้ทันทีว่าพื้นที่ที่ระบุว่าเป็นฮอตสปอตนั้น มีสถานที่ที่คุณกำลังวิเคราะห์อยู่เป็นจำนวนมาก การยืนยันด้วยภาพนี้ จะสร้างความน่าเชื่อถืออย่างมากให้กับข้อสรุปที่อิงตามข้อมูล
บทสรุป
รูปแบบสถาปัตยกรรมนี้เป็นวิธีที่แข็งแกร่งและมีประสิทธิภาพในการตรวจสอบความถูกต้องของข้อมูลเชิงลึกเชิงพื้นที่ขนาดใหญ่ การใช้ประโยชน์จากข้อมูลเชิงลึกเกี่ยวกับสถานที่สำหรับการวิเคราะห์ในวงกว้างที่ปรับขนาดได้ และ Place Details API สำหรับการยืนยันความจริงที่เจาะจง คุณจะสร้างวงจรความคิดเห็นที่มีประสิทธิภาพ ซึ่งจะช่วยให้การตัดสินใจเชิงกลยุทธ์ ไม่ว่าจะเป็นการเลือกเว็บไซต์ค้าปลีกหรือการวางแผนด้านลอจิสติกส์ อิงตามข้อมูลที่มีนัยสำคัญทางสถิติและมีความถูกต้องที่ตรวจสอบได้
ขั้นตอนถัดไป
- สํารวจฟังก์ชันการนับสถานที่อื่นๆ เพื่อดูว่าฟังก์ชันเหล่านั้นตอบคําถามเชิงวิเคราะห์ที่แตกต่างกันได้อย่างไร
- อ่านเอกสารประกอบเกี่ยวกับ Places API เพื่อดูช่องอื่นๆ ที่คุณขอได้เพื่อเพิ่มข้อมูลในการวิเคราะห์
ผู้ร่วมให้ข้อมูล
Henrik Valve | DevX Engineer