
En este documento, aprenderás a usar datos de ejemplo de IDs de lugares de Places Insights, con las funciones de recuento de lugares, junto con búsquedas segmentadas de Place Details para generar confianza en tus resultados.
Para obtener una implementación de referencia detallada de este patrón, consulta este notebook explicativo:
 Ver código fuente en GitHub
Ver código fuente en GitHub
El patrón arquitectónico
Este patrón arquitectónico te brinda un flujo de trabajo repetible para cerrar la brecha entre el análisis estadístico de alto nivel y la verificación de datos reales. Si combinas la escala de BigQuery con la precisión de la API de Places, puedes validar con confianza tus hallazgos analíticos. Esto es particularmente útil para la selección de sitios, el análisis de la competencia y la investigación de mercado, en los que la confianza en los datos es fundamental.
El núcleo de este patrón incluye cuatro pasos clave:
- Realiza un análisis a gran escala: Usa una función de recuento de lugares de Places Insights en BigQuery para analizar datos de lugares en una geografía grande, como una ciudad o región completa.
- Aísla y extrae muestras: Identifica áreas de interés (p.ej., "puntos de acceso" con alta densidad) a partir de los resultados agregados y extrae los
sample_place_idsque proporciona la función. - Recupera detalles de datos reales: Usa los IDs de lugares extraídos para realizar llamadas segmentadas a la API de Place Details y obtener detalles enriquecidos del mundo real para cada lugar.
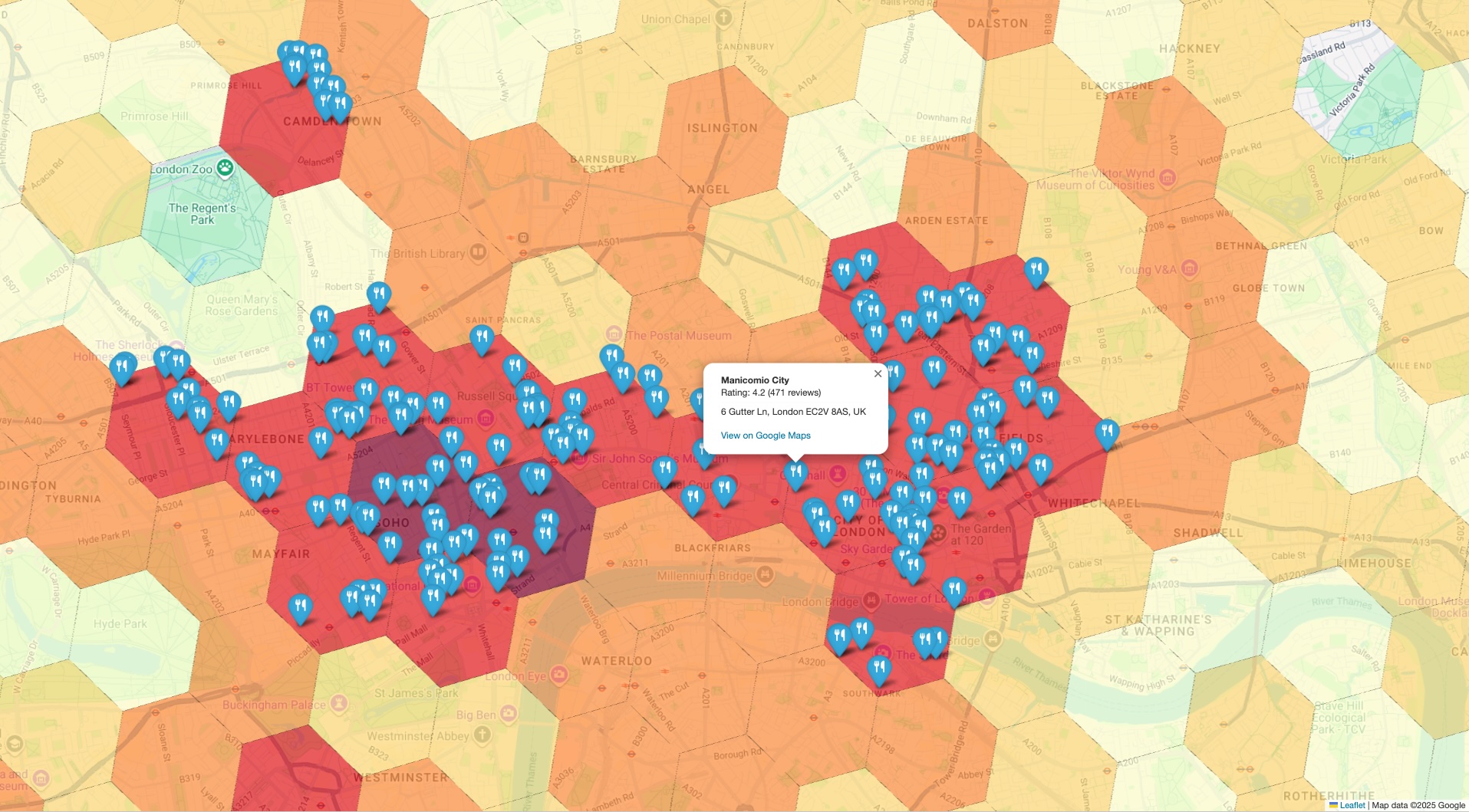
- Crea una visualización combinada: Superpón los datos detallados de los lugares sobre el mapa estadístico inicial de alto nivel para validar visualmente que los recuentos agregados reflejen la realidad en el terreno.
Flujo de trabajo de la solución
Este flujo de trabajo te permite cerrar la brecha entre las tendencias a nivel macro y los datos a nivel micro. Comienzas con una vista estadística amplia y, de forma estratégica, profundizas para verificar los datos con ejemplos específicos del mundo real.
Analiza la densidad de lugares a gran escala con Places Insights
El primer paso es comprender el panorama a un nivel alto. En lugar de recuperar miles de puntos de interés (POI) individuales, puedes ejecutar una sola consulta para obtener un resumen estadístico.
La función PLACES_COUNT_PER_H3
de Places Insights
es ideal para esto. Agrega recuentos de POI en un sistema de cuadrícula hexagonal
(H3), lo que te permite identificar rápidamente áreas de
alta o baja densidad según tus criterios específicos (p.ej., restaurantes con una
calificación alta que estén operativos).
A continuación, se muestra una consulta de ejemplo. Ten en cuenta que deberás proporcionar la geografía de tu área de búsqueda. Se puede usar un conjunto de datos abiertos, como el Overture Maps Data BigQuery public dataset, para recuperar datos de límites geográficos.
Para los límites de conjuntos de datos abiertos que se usan con frecuencia, recomendamos materializarlos en una tabla de tu propio proyecto. Esto reduce significativamente los costos de BigQuery y mejora el rendimiento de las consultas.
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
Filtrado y validación por ID de marca
Si deseas validar los recuentos y los IDs de lugares de muestra para marcas específicas, proporciona una lista de IDs de marcas con el filtro brand_ids.
Para obtener el ID de marca de una marca objetivo, consulta la tabla brands en BigQuery:
SELECT id, name
FROM `YOUR_PROJECT.places_insights___us.brands`
WHERE LOWER(name) LIKE "%starbucks%";
Después de recuperar el ID de marca objetivo (por ejemplo, "1413758728321880760"
para Starbucks), pásalo dentro del array de filtros brand_ids:
SELECT *
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'brand_ids', ["1413758728321880760"]
)
);
Durante el paso 3, la verificación de datos reales, en lugar de confirmar que un lugar coincide con categorías generales, puedes comparar de forma programática el nombre visible que muestra la API de Place Details con el nombre de marca esperado mediante una coincidencia de expresión regular. Por ejemplo, puedes comparar el campo response.display_name.text.
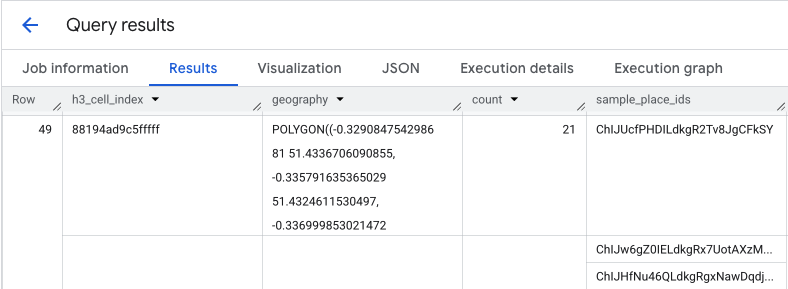
El resultado de esta consulta te proporciona una tabla de celdas H3 y el recuento de lugares dentro de cada una, lo que forma la base de un mapa de calor de densidad.
Aísla los puntos de acceso y extrae los IDs de lugares de muestra
El resultado de la función PLACES_COUNT_PER_H3 también muestra un array de sample_place_ids, hasta 250 IDs de lugares por elemento de la respuesta. Estos IDs son el vínculo de la estadística agregada a los lugares individuales que contribuyen a ella.
Tu sistema podría identificar primero las celdas más pertinentes de la consulta inicial.
Por ejemplo, puedes seleccionar las 20 celdas principales con los recuentos más altos. Luego, desde estos puntos de acceso, consolida los sample_place_ids en una sola lista.
Esta lista representa una muestra seleccionada de los POI más interesantes de las áreas más pertinentes, lo que te prepara para la verificación segmentada.
Si procesas tus resultados de BigQuery en Python con un DataFrame de pandas, la lógica para extraer estos IDs es sencilla:
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
Se puede aplicar una lógica similar si se usan otros lenguajes de programación.
Recupera detalles de datos reales con la API de Places
Con tu lista consolidada de IDs de lugares, ahora puedes pasar de las estadísticas a gran escala a la recuperación de datos específicos. Usarás estos IDs para consultar la API de Place Details y obtener información detallada sobre cada ubicación de muestra.
Este es un paso de validación fundamental. Si bien Places Insights te indicó cuántos restaurantes había en un área, la API de Places te indica cuáles son, y te proporciona su nombre, dirección exacta, latitud/longitud, calificación de los usuarios e incluso un vínculo directo a su ubicación en Google Maps. Esto enriquece tus datos de muestra, ya que convierte los IDs abstractos en lugares concretos y verificables.
Para obtener la lista completa de los datos disponibles en la API de Place Details y el costo asociado con la recuperación, revisa la documentación de la API documentación.
Una solicitud a la API de Places para un ID específico con la biblioteca cliente de Python se vería de la siguiente manera. Consulta los ejemplos de la biblioteca cliente de la API de Places (nueva) para obtener más detalles.
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
Ten en cuenta que los campos de esta solicitud extraen datos de dos SKUs de facturación diferentes.
formattedAddressylocationforman parte del SKU de Place Details Essentials.displayNameygoogleMapsUriforman parte del SKU de Place Details Pro.
Cuando una sola solicitud de Place Details incluye campos de varios SKUs, se factura toda la solicitud según la tarifa del SKU de nivel más alto. Por lo tanto, esta llamada específica se facturará como una solicitud de Place Details Pro.
Para controlar tus costos, usa siempre el FieldMask para solicitar solo los campos que requiere tu aplicación.
Crea una visualización combinada para la validación
El paso final es reunir ambos conjuntos de datos en una sola vista. Esto proporciona una forma inmediata e intuitiva de verificar tu análisis inicial. Tu visualización debe tener dos capas:
- Capa base: Un mapa coroplético o de calor generado a partir de los resultados iniciales de
PLACES_COUNT_PER_H3, que muestra la densidad general de lugares en tu geografía. - Capa superior: Un conjunto de marcadores individuales para cada POI de muestra, trazados con las coordenadas precisas recuperadas de la API de Places en el paso anterior.
La lógica para compilar esta vista combinada se expresa en este ejemplo de pseudocódigo:
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
Si superpones los marcadores específicos de datos reales en el mapa de densidad de alto nivel, puedes confirmar al instante que las áreas identificadas como puntos de acceso contienen, de hecho, una alta concentración de los lugares que estás analizando. Esta confirmación visual genera una confianza significativa en tus conclusiones basadas en datos.
Conclusión
Este patrón arquitectónico proporciona un método sólido y eficiente para validar estadísticas geoespaciales a gran escala. Si aprovechas Places Insights para realizar análisis amplios y escalables, y la API de Place Details para realizar verificaciones segmentadas de datos reales, creas un potente circuito de retroalimentación. Esto garantiza que tus decisiones estratégicas, ya sea en la selección de sitios de venta minorista o en la planificación logística, se basen en datos que no solo sean estadísticamente significativos, sino también verificablemente precisos.
Próximos pasos
- Explora otras funciones de recuento de lugares para ver cómo pueden responder diferentes preguntas analíticas.
- Revisa la documentación de la API de Places para descubrir otros campos que puedes solicitar para enriquecer aún más tu análisis.
Colaboradores
Henrik Valve | DevX Ingeniero