
במאמר הזה נסביר איך להשתמש בנתונים לדוגמה של מזהי מקומות מתוך Places Insights, באמצעות פונקציות של ספירת מקומות, לצד חיפושים מטורגטים של פרטי מקומות, כדי להגביר את רמת הביטחון בתוצאות.
לעיון בהטמעה מפורטת של התבנית הזו, אפשר לעיין במחברת ההסבר הבאה:
 הצגת המקור ב-GitHub
הצגת המקור ב-GitHub
הדפוס האדריכלי
דפוס הארכיטקטורה הזה מספק לכם תהליך עבודה שניתן לחזור עליו כדי לגשר על הפער בין ניתוח סטטיסטי ברמה גבוהה לבין אימות של נתוני אמת. שילוב של היכולות של BigQuery עם הדיוק של Places API מאפשר לכם לאמת את הממצאים האנליטיים שלכם בביטחון. האפשרות הזו שימושית במיוחד לבחירת מיקום, לניתוח מתחרים ולמחקר שוק, שבהם האמון בנתונים הוא בעל חשיבות עליונה.
הליבה של התבנית הזו כוללת ארבעה שלבים עיקריים:
- ניתוח נתונים בקנה מידה גדול: אפשר להשתמש בפונקציה של ספירת מקומות מתוך Places Insights ב-BigQuery כדי לנתח נתוני מקומות באזור גיאוגרפי גדול, כמו עיר או אזור שלמים.
- בידוד דגימות וחילוץ שלהן: מזהים אזורים שמעניינים אתכם (למשל, אזורים עם צפיפות גבוהה) מתוך התוצאות המצטברות, ומחלצים את
sample_place_idsשמוצגות על ידי הפונקציה. - אחזור פרטים של מקומות: משתמשים במזהי המקומות שחולצו כדי לבצע קריאות ממוקדות ל-Place Details API כדי לאחזר פרטים עשירים על כל מקום בעולם האמיתי.
- יצירת תצוגה חזותית משולבת: כדי לוודא שהספירות המצטברות משקפות את המצב בשטח, אפשר להוסיף את נתוני המקומות המפורטים מעל המפה הסטטיסטית הראשונית ברמת המבט הכוללת.
תהליך העבודה של הפתרון
תהליך העבודה הזה מאפשר לגשר על הפער בין מגמות ברמת המאקרו לבין עובדות ברמת המיקרו. מתחילים בתצוגה רחבה של נתונים סטטיסטיים, ואז מתמקדים באופן אסטרטגי בנתונים כדי לאמת אותם באמצעות דוגמאות ספציפיות מהעולם האמיתי.
ניתוח צפיפות של מקומות בהיקף נרחב באמצעות Places Insights
השלב הראשון הוא להבין את התמונה הכוללת. במקום לאחזר אלפי נקודות עניין (POI) בודדות, אתם יכולים להריץ שאילתה אחת כדי לקבל סיכום סטטיסטי.
הפונקציה PLACES_COUNT_PER_H3
Places Insights
היא הפתרון האידיאלי למצבים כאלה. הוא צובר את מספר הנקודות של העניין במערכת רשת משושים (H3), ומאפשר לכם לזהות במהירות אזורים עם צפיפות גבוהה או נמוכה על סמך הקריטריונים הספציפיים שלכם (למשל, מסעדות עם דירוג גבוה שפועלות).
לדוגמה, השאילתה הבאה: חשוב לזכור שתצטרכו לספק את המיקום הגיאוגרפי של אזור החיפוש. אפשר להשתמש במערך נתונים פתוח, כמו Overture Maps Data, שהוא מערך נתונים ציבורי ב-BigQuery, כדי לאחזר נתונים של גבולות גיאוגרפיים.
אם אתם משתמשים לעיתים קרובות בגבולות של מערכי נתונים פתוחים, מומלץ ליצור מהם טבלה בפרויקט שלכם. כך אפשר לצמצם משמעותית את העלויות ב-BigQuery ולשפר את ביצועי השאילתות.
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
סינון ואימות לפי מזהה מותג
אם רוצים לאמת את הספירות ואת מזהי המקומות לדוגמה של מותגים ספציפיים, צריך לספק רשימה של מזהי מותגים באמצעות המסנן brand_ids.
כדי לקבל את מזהה המותג של מותג יעד, שולחים שאילתה לטבלה brands ב-BigQuery:
SELECT id, name
FROM `YOUR_PROJECT.places_insights___us.brands`
WHERE LOWER(name) LIKE "%starbucks%";
אחרי שמקבלים את מזהה מותג היעד (לדוגמה, "1413758728321880760"
עבור Starbucks), מעבירים אותו בתוך מערך המסננים brand_ids:
SELECT *
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'brand_ids', ["1413758728321880760"]
)
);
במהלך שלב 3, אימות האמת הבסיסית, במקום לאשר שמקום מסוים תואם לקטגוריות כלליות, אפשר להשוות באופן פרוגרמטי את השם המוצג שמוחזר על ידי Place Details API לשם המותג הצפוי באמצעות התאמה לביטוי רגולרי. לדוגמה, אפשר להשוות את השדה response.display_name.text.
הפלט של השאילתה הזו הוא טבלה של תאי H3 ומספר המקומות בכל תא, שמהווה את הבסיס למפת חום של צפיפות.
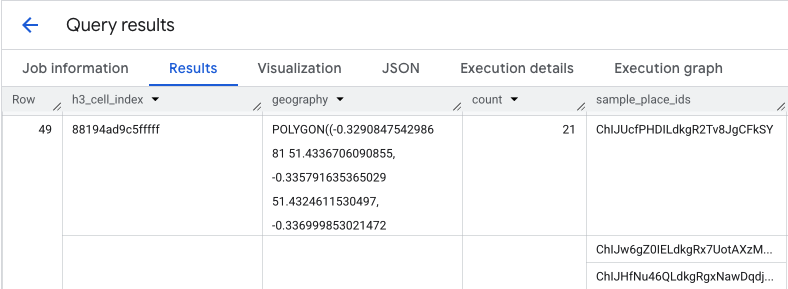
בידוד נקודות חמות וחילוץ מזהים לדוגמה של מקומות
התוצאה של הפונקציה PLACES_COUNT_PER_H3 היא גם מערך של sample_place_ids, עד 250 מזהי מקומות לכל רכיב בתגובה. המזהים האלה הם הקישור מהנתון הסטטיסטי המצטבר למקומות הספציפיים שמהם הוא מורכב.
המערכת יכולה קודם לזהות את התאים הרלוונטיים ביותר מהשאילתה הראשונית.
לדוגמה, אפשר לבחור את 20 התאים העליונים עם הערכים הכי גבוהים. לאחר מכן, מתוך הנקודות החמות האלה, מאחדים את sample_place_ids לרשימה אחת.
הרשימה הזו מייצגת מדגם של נקודות העניין המעניינות ביותר מהאזורים הרלוונטיים ביותר, כדי להכין אתכם לאימות ממוקד.
אם אתם מעבדים את התוצאות של BigQuery ב-Python באמצעות pandas DataFrame, הלוגיקה לחילוץ המזהים האלה היא פשוטה:
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
אפשר להשתמש בלוגיקה דומה אם משתמשים בשפות תכנות אחרות.
אחזור פרטים של נתוני אמת באמצעות Places API
אחרי שיוצרים רשימה מאוחדת של מזהי מקומות, אפשר לעבור מניתוח נתונים בהיקף נרחב לאחזור נתונים ספציפיים. תשתמשו במזהים האלה כדי להריץ שאילתות ב-Place Details API ולקבל מידע מפורט על כל מיקום לדוגמה.
זהו שלב אימות קריטי. בעוד שבתובנות לגבי מקומות אפשר לראות כמה מסעדות יש באזור מסוים, באמצעות Places API אפשר לראות אילו מסעדות יש באזור, כולל השם, הכתובת המדויקת, קו הרוחב וקו האורך, דירוג המשתמשים ואפילו קישור ישיר למיקום שלהן במפות Google. כך המערכת מעשירה את נתוני המדגם, והופכת מזהים מופשטים למקומות קונקרטיים שניתן לאמת.
רשימה מלאה של הנתונים שזמינים מ-Place Details API והעלות שמשויכת לאחזור מופיעה במסמכי התיעוד של ה-API.
בקשה ל-Places API לקבלת מזהה ספציפי באמצעות ספריית הלקוח של Python תיראה כך. פרטים נוספים מופיעים בדוגמאות לשימוש בספריית הלקוח של Places API (חדש).
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
חשוב לדעת שהשדות בבקשה הזו שואבים נתונים משני מק"טים שונים של חיוב.
-
formattedAddressו-locationהם חלק מPlace Details Essentials SKU. -
displayNameו-googleMapsUriהם חלק מחבילת Place Details Pro.
אם בקשה אחת של פרטי מקום כוללת שדות מכמה מק"טים, כל הבקשה תחויב לפי התעריף של המק"ט ברמה הגבוהה ביותר. לכן, החיוב על הקריאה הספציפית הזו יהיה כבקשה לפרטי מקום ב-Pro.
כדי לשלוט בעלויות, תמיד כדאי להשתמש בפרמטר FieldMask כדי לבקש רק את השדות שהאפליקציה צריכה.
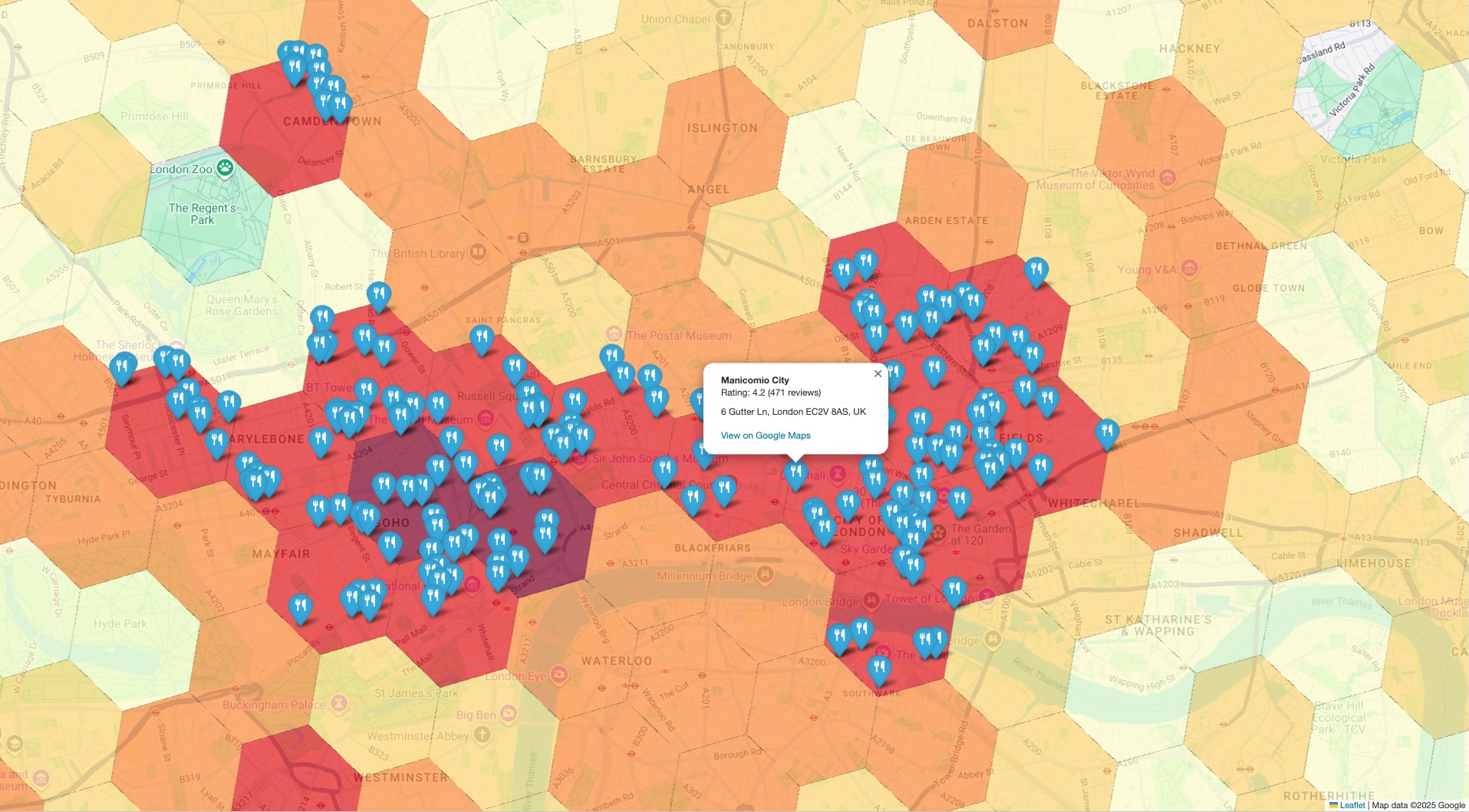
יצירת תצוגה חזותית משולבת לאימות
השלב האחרון הוא לאחד את שני מערכי הנתונים לתצוגה אחת. כך תוכלו לבדוק את הניתוח הראשוני שלכם באופן מיידי ואינטואיטיבי. הוויזואליזציה צריכה לכלול שתי שכבות:
- שכבת הבסיס: מפה כמותית או מפת חום שנוצרות מהתוצאות הראשוניות של
PLACES_COUNT_PER_H3, שבהן מוצגת הצפיפות הכוללת של המקומות באזור הגיאוגרפי שלכם. - השכבה העליונה: קבוצה של סמנים נפרדים לכל נקודת עניין לדוגמה, שמוצגים באמצעות הקואורדינטות המדויקות שאוחזרו מ-Places API בשלב הקודם.
הלוגיקה ליצירת התצוגה המשולבת הזו מופיעה בדוגמה הבאה של פסאודו-קוד:
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
כשמציגים את הסמנים הספציפיים של נתוני האמת על גבי מפת הצפיפות ברמה הגבוהה, אפשר לוודא באופן מיידי שהאזורים שזוהו כנקודות חמות אכן מכילים ריכוז גבוה של המקומות שאתם מנתחים. האימות הוויזואלי הזה עוזר לבנות אמון משמעותי במסקנות שמבוססות על הנתונים.
סיכום
דפוס הארכיטקטורה הזה מספק שיטה חזקה ויעילה לאימות תובנות גיאוספציאליות בקנה מידה גדול. בעזרת Places Insights לניתוח רחב היקף וניתן להרחבה, ובעזרת Place Details API לאימות ממוקד של נתוני אמת, אתם יוצרים לולאת משוב יעילה. כך תוכלו לוודא שההחלטות האסטרטגיות שלכם, בין אם מדובר בבחירת מיקום לחנות קמעונאית או בתכנון לוגיסטי, מבוססות על נתונים שהם לא רק בעלי מובהקות סטטיסטית, אלא גם מדויקים באופן שניתן לאימות.
השלבים הבאים
- כדאי לעיין בפונקציות אחרות של ספירת מקומות כדי לראות איך הן יכולות לענות על שאלות אנליטיות שונות.
- כדאי לעיין במסמכי התיעוד של Places API כדי לגלות שדות נוספים שאפשר לבקש כדי להעשיר עוד יותר את הניתוח.
תורמים
Henrik Valve | DevX Engineer