
Giới thiệu
Tài liệu này mô tả cách xây dựng một giải pháp lựa chọn địa điểm bằng cách kết hợp tập dữ liệu Thông tin chi tiết về địa điểm, dữ liệu không gian địa lý công khai trong BigQuery và Place Details API.
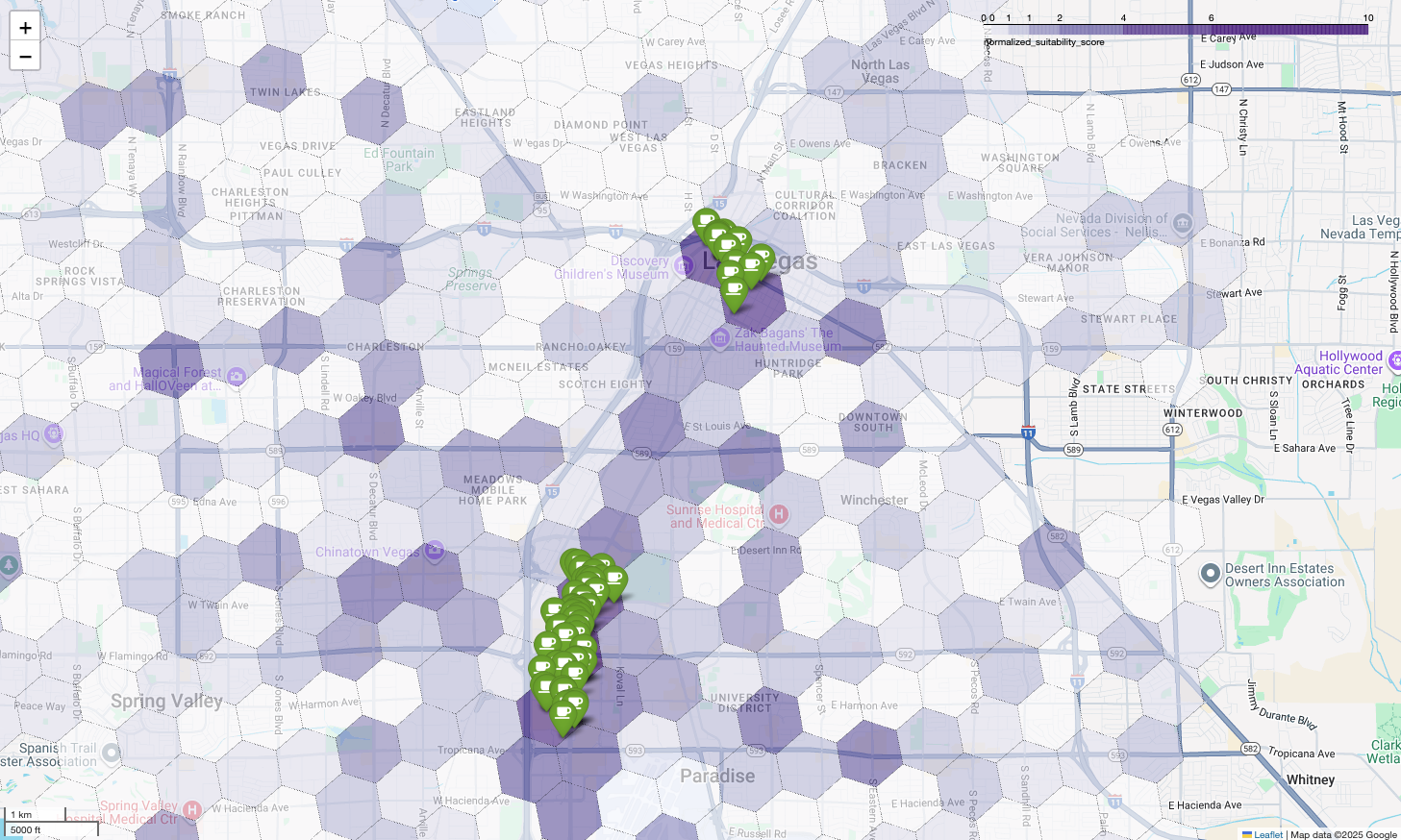
Bản đồ ở trên minh hoạ kết quả của một bản trình diễn tại Google Cloud Next 2025. Bạn có thể xem bản trình diễn này trên YouTube. Bạn có thể chạy mã dùng để tạo các kết quả này bằng sổ tay mẫu.
 Xem nguồn trên GitHub
Xem nguồn trên GitHub
Thử thách kinh doanh
Hãy tưởng tượng bạn sở hữu một chuỗi cửa hàng cà phê thành công và muốn mở rộng sang một tiểu bang mới, chẳng hạn như Nevada, nơi bạn chưa có mặt. Việc mở một địa điểm mới là một khoản đầu tư đáng kể và việc đưa ra quyết định dựa trên dữ liệu là yếu tố quan trọng để thành công. Bạn nên bắt đầu từ đâu?
Hướng dẫn này sẽ giúp bạn phân tích nhiều lớp để xác định vị trí tối ưu cho một quán cà phê mới. Chúng tôi sẽ bắt đầu với chế độ xem toàn tiểu bang, từng bước thu hẹp phạm vi tìm kiếm xuống một quận và khu thương mại cụ thể, đồng thời cuối cùng thực hiện phân tích siêu cục bộ để chấm điểm từng khu vực và xác định khoảng trống thị trường bằng cách lập bản đồ đối thủ cạnh tranh.
Quy trình giải pháp
Quy trình này tuân theo một phễu logic, bắt đầu từ phạm vi rộng và dần dần trở nên chi tiết hơn để tinh chỉnh khu vực tìm kiếm và tăng độ tin cậy khi chọn trang web cuối cùng.
Điều kiện tiên quyết và cách thiết lập môi trường
Trước khi bắt đầu phân tích, bạn cần có một môi trường với một số chức năng chính. Mặc dù hướng dẫn này sẽ trình bày một cách triển khai bằng SQL và Python, nhưng bạn có thể áp dụng các nguyên tắc chung cho các ngăn xếp công nghệ khác.
Là điều kiện tiên quyết, hãy đảm bảo môi trường của bạn có thể:
- Thực thi truy vấn trong BigQuery.
- Truy cập vào Thông tin chi tiết về địa điểm, hãy xem phần Thiết lập Thông tin chi tiết về địa điểm để biết thêm thông tin
- Đăng ký nhận các tập dữ liệu công khai từ
bigquery-public-datavà Tổng số dân số theo quận của Cục Thống kê Dân số Hoa Kỳ
Bạn cũng cần có khả năng trực quan hoá dữ liệu không gian địa lý trên bản đồ. Đây là điều quan trọng để diễn giải kết quả của từng bước phân tích. Có nhiều cách để thực hiện việc này. Bạn có thể sử dụng các công cụ BI như Looker Studio để kết nối trực tiếp với BigQuery hoặc sử dụng các ngôn ngữ khoa học dữ liệu như Python.
Phân tích ở cấp tiểu bang: Tìm hạt phù hợp nhất
Bước đầu tiên là phân tích trên diện rộng để xác định quận có nhiều triển vọng nhất ở Nevada. Chúng tôi sẽ định nghĩa đầy hứa hẹn là sự kết hợp giữa dân số cao và mật độ nhà hàng hiện có cao, cho thấy văn hoá ẩm thực mạnh mẽ.
Truy vấn BigQuery của chúng tôi thực hiện việc này bằng cách tận dụng các thành phần địa chỉ tích hợp sẵn có trong tập dữ liệu Thông tin chi tiết về địa điểm. Truy vấn này đếm số lượng nhà hàng bằng cách lọc dữ liệu trước để chỉ bao gồm những địa điểm trong tiểu bang Nevada, sử dụng trường administrative_area_level_1_name. Sau đó, truy vấn này tinh chỉnh thêm tập hợp này để chỉ bao gồm những địa điểm mà mảng loại chứa "restaurant". Cuối cùng, truy vấn này nhóm các kết quả này theo tên quận (administrative_area_level_2_name) để tạo số lượng cho mỗi quận. Phương pháp này sử dụng cấu trúc địa chỉ được lập chỉ mục trước, tích hợp sẵn của tập dữ liệu.
Đoạn trích này cho thấy cách chúng ta kết hợp các hình học của quận với Thông tin chi tiết về địa điểm và lọc theo một loại địa điểm cụ thể, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Chỉ đếm số lượng nhà hàng thô là không đủ; chúng ta cần cân bằng số lượng này với dữ liệu dân số để có được cảm nhận chân thực về mức độ bão hoà và cơ hội của thị trường. Chúng tôi sẽ sử dụng dữ liệu dân số của Tổng dân số theo hạt của Cục Thống kê Dân số Hoa Kỳ.
Để so sánh hai chỉ số rất khác nhau này (số lượng địa điểm so với số lượng lớn dân số), chúng tôi sử dụng phương pháp chuẩn hoá tối thiểu-tối đa. Kỹ thuật này điều chỉnh cả hai chỉ số theo một phạm vi chung (từ 0 đến 1). Sau đó, chúng tôi kết hợp các chỉ số này thành một normalized_score duy nhất, trong đó mỗi chỉ số có trọng số 50% để so sánh một cách cân bằng.
Đoạn trích này cho thấy logic cốt lõi để tính điểm. Chỉ số này kết hợp số dân và số lượng nhà hàng đã được chuẩn hoá:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Sau khi chạy truy vấn đầy đủ, một danh sách các quận, số lượng nhà hàng, dân số và điểm số được chuẩn hoá sẽ được trả về. Sắp xếp theo normalized_score
DESC cho thấy Hạt Clark là lựa chọn rõ ràng nhất để điều tra thêm vì đây là ứng cử viên hàng đầu.
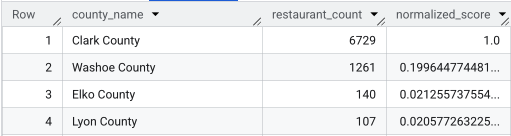
Ảnh chụp màn hình này cho thấy 4 quận hàng đầu theo điểm số được chuẩn hoá. Số lượng dân số thô đã được cố ý bỏ qua trong ví dụ này.
Phân tích ở cấp quận: Tìm các khu thương mại sầm uất nhất
Giờ đây, khi đã xác định được Quận Clark, bước tiếp theo là phóng to để tìm mã bưu chính có hoạt động thương mại cao nhất. Dựa trên dữ liệu từ các quán cà phê hiện có, chúng tôi biết rằng hiệu suất sẽ tốt hơn khi quán nằm gần nơi tập trung nhiều thương hiệu lớn. Vì vậy, chúng tôi sẽ sử dụng thông tin này làm chỉ số đại diện cho lượng người ghé thăm cửa hàng thực tế cao.
Truy vấn này sử dụng bảng brands trong Thông tin chi tiết về địa điểm, chứa thông tin về các thương hiệu cụ thể. Bạn có thể truy vấn bảng này để khám phá danh sách các thương hiệu được hỗ trợ. Trước tiên, chúng tôi xác định danh sách các thương hiệu mục tiêu, sau đó kết hợp danh sách này với tập dữ liệu chính của Thông tin chi tiết về địa điểm để đếm số lượng một số cửa hàng trong số này nằm trong mỗi mã bưu chính ở Quận Clark.
Cách hiệu quả nhất để đạt được mục tiêu này là thực hiện theo phương pháp gồm 2 bước:
- Trước tiên, chúng ta sẽ thực hiện một quy trình tổng hợp nhanh chóng, không gian địa lý để đếm số lượng thương hiệu trong mỗi mã bưu chính.
- Thứ hai, chúng tôi sẽ kết hợp những kết quả đó với một tập dữ liệu công khai để lấy ranh giới trên bản đồ cho mục đích trực quan hoá.
Đếm số lượng thương hiệu bằng trường postal_code_names
Truy vấn đầu tiên này thực hiện logic đếm cốt lõi. Thao tác này lọc các địa điểm ở Quận Clark, sau đó huỷ lồng mảng postal_code_names để nhóm số lượng thương hiệu theo mã bưu chính.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
Kết quả là một bảng gồm mã bưu chính và số lượng thương hiệu tương ứng.
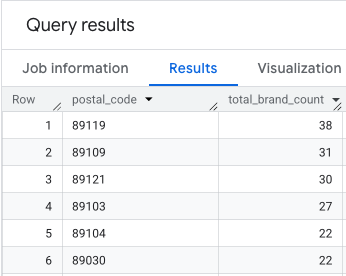
Đính kèm hình học mã ZIP để lập bản đồ
Giờ đây, khi đã có số lượng, chúng ta có thể lấy các hình đa giác cần thiết để trực quan hoá. Truy vấn thứ hai này lấy truy vấn đầu tiên của chúng ta, bao bọc truy vấn đó trong một Biểu thức bảng chung (CTE) có tên là brand_counts_by_zip và kết hợp kết quả của truy vấn đó với geo_us_boundaries.zip_codes table công khai. Thao tác này sẽ gắn hiệu quả hình học vào số lượng được tính toán trước của chúng tôi.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
Kết quả là một bảng gồm mã bưu chính, số lượng thương hiệu tương ứng và hình học mã bưu chính.
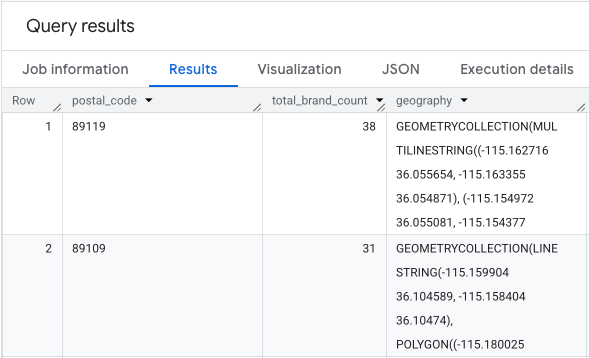
Chúng ta có thể trực quan hoá dữ liệu này dưới dạng biểu đồ nhiệt. Các khu vực màu đỏ đậm hơn cho biết nồng độ cao hơn của các thương hiệu mục tiêu, hướng chúng tôi đến những khu vực có mật độ thương mại cao nhất ở Las Vegas.
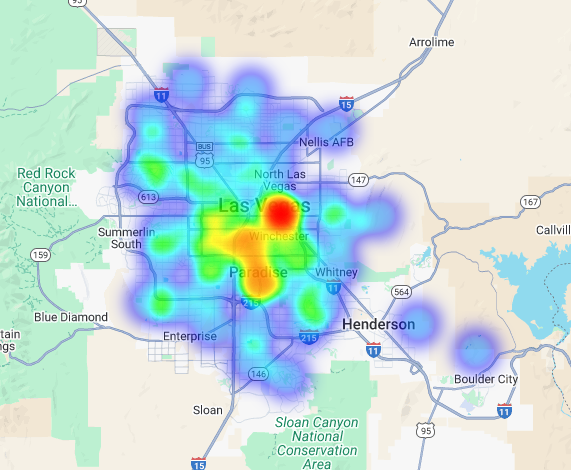
Phân tích siêu cục bộ: Chấm điểm từng khu vực trên lưới
Sau khi xác định được khu vực khái quát của Las Vegas, đã đến lúc phân tích thật chi tiết. Đây là nơi chúng tôi áp dụng kiến thức kinh doanh cụ thể của mình. Chúng tôi biết một quán cà phê tuyệt vời sẽ phát triển mạnh mẽ khi ở gần những doanh nghiệp khác hoạt động nhộn nhịp trong giờ cao điểm của chúng tôi, chẳng hạn như vào cuối buổi sáng và giờ ăn trưa.
Truy vấn tiếp theo của chúng ta sẽ thực sự cụ thể. Việc này bắt đầu bằng cách tạo một lưới lục giác chi tiết trên khu vực đô thị Las Vegas bằng cách sử dụng chỉ mục không gian địa lý H3 tiêu chuẩn (ở độ phân giải 8) để phân tích khu vực ở cấp độ vi mô. Trước tiên, truy vấn sẽ xác định tất cả các doanh nghiệp bổ sung đang mở cửa trong khung giờ cao điểm của chúng tôi (từ 10 giờ sáng đến 2 giờ chiều thứ Hai).
Sau đó, chúng tôi áp dụng điểm số có trọng số cho từng loại địa điểm. Một nhà hàng gần đó có giá trị hơn đối với chúng tôi so với một cửa hàng tiện lợi, vì vậy nhà hàng sẽ nhận được hệ số nhân cao hơn. Điều này giúp chúng ta có một suitability_score tuỳ chỉnh cho từng khu vực nhỏ.
Đoạn trích này làm nổi bật logic tính điểm có trọng số, tham chiếu đến một cờ (is_open_monday_window) được tính toán trước để kiểm tra giờ mở cửa:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Mở rộng để xem toàn bộ truy vấn
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
Việc trực quan hoá các điểm số này trên bản đồ sẽ cho thấy rõ những vị trí chiến thắng. Các ô màu tím đậm nhất, chủ yếu ở gần Dải Las Vegas và trung tâm thành phố, là những khu vực có tiềm năng cao nhất cho quán cà phê mới của chúng tôi.
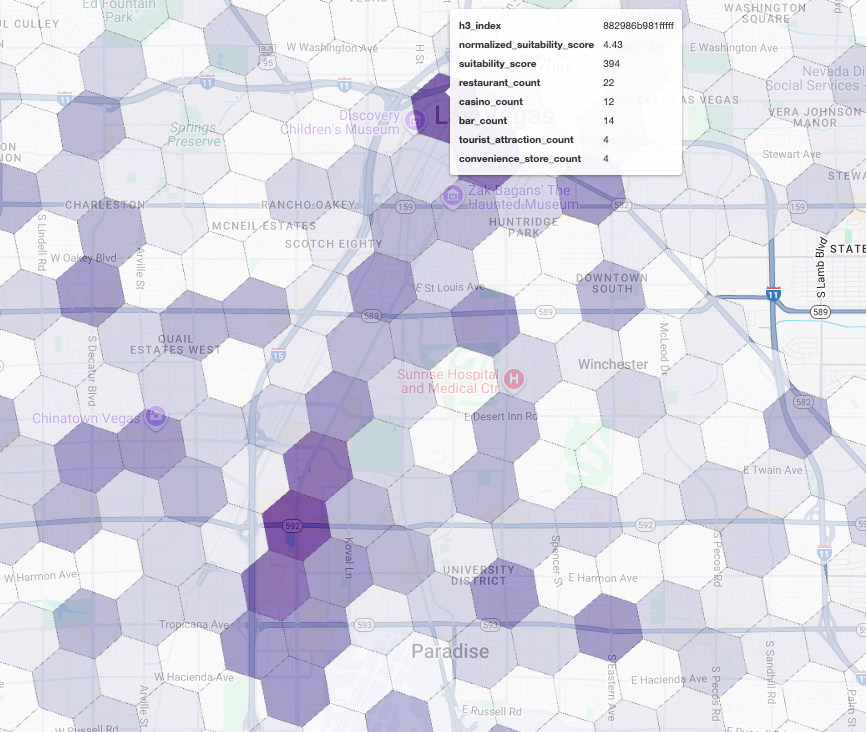
Phân tích đối thủ cạnh tranh: Xác định các quán cà phê hiện có
Mô hình phù hợp của chúng tôi đã xác định thành công những khu vực hứa hẹn nhất, nhưng chỉ có điểm cao không đảm bảo thành công. Giờ đây, chúng ta phải phủ dữ liệu này lên dữ liệu của đối thủ cạnh tranh. Vị trí lý tưởng là khu vực có tiềm năng cao và mật độ quán cà phê hiện có thấp, vì chúng tôi đang tìm kiếm một khoảng trống rõ ràng trên thị trường.
Để làm được điều này, chúng ta sẽ sử dụng hàm PLACES_COUNT_PER_H3. Hàm này được thiết kế để trả về số lượng địa điểm một cách hiệu quả trong một khu vực địa lý cụ thể, theo ô H3.
Trước tiên, chúng tôi xác định một cách linh hoạt vị trí địa lý cho toàn bộ khu vực đô thị Las Vegas.
Thay vì chỉ dựa vào một địa điểm, chúng tôi truy vấn tập dữ liệu công khai Overture Maps để lấy ranh giới của Las Vegas và các địa điểm chính xung quanh, hợp nhất chúng thành một đa giác duy nhất bằng ST_UNION_AGG. Sau đó, chúng ta sẽ truyền khu vực này vào hàm, yêu cầu hàm đếm tất cả các quán cà phê đang hoạt động.
Truy vấn này xác định khu vực đô thị và gọi hàm để lấy số lượng quán cà phê trong các ô H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
Hàm này trả về một bảng bao gồm chỉ mục ô H3, hình học của ô đó, tổng số quán cà phê và mẫu mã địa điểm của các quán cà phê:
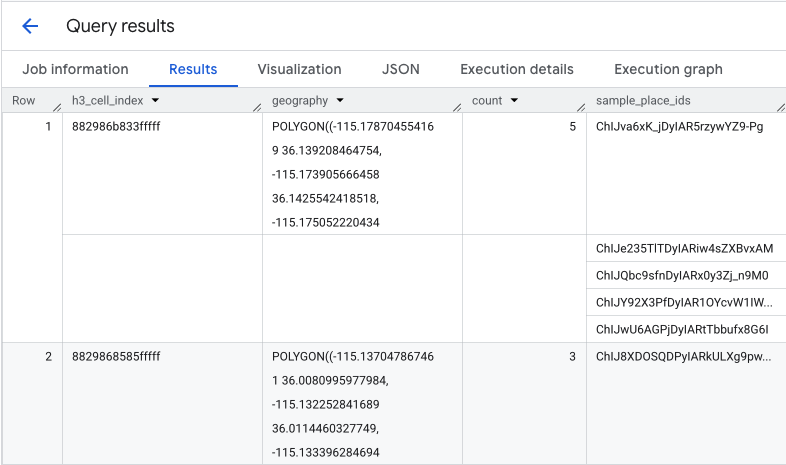
Mặc dù số lượng tổng hợp là thông tin hữu ích, nhưng việc xem các đối thủ cạnh tranh thực tế là điều cần thiết.
Đây là nơi chúng tôi chuyển đổi từ tập dữ liệu Thông tin chi tiết về địa điểm sang Places API. Bằng cách trích xuất sample_place_ids từ các ô có điểm phù hợp được chuẩn hoá cao nhất, chúng ta có thể gọi Place Details API để truy xuất thông tin chi tiết phong phú cho từng đối thủ cạnh tranh, chẳng hạn như tên, địa chỉ, điểm xếp hạng và vị trí của họ.
Điều này đòi hỏi bạn phải so sánh kết quả của cụm từ tìm kiếm trước đó (nơi điểm phù hợp được tạo) và cụm từ tìm kiếm PLACES_COUNT_PER_H3. Bạn có thể dùng Chỉ mục ô H3 để lấy số lượng và mã nhận dạng quán cà phê từ các ô có điểm phù hợp được chuẩn hoá cao nhất.
Đoạn mã Python này minh hoạ cách thực hiện so sánh.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Giờ đây, chúng ta có danh sách Mã địa điểm cho các quán cà phê đã tồn tại trong các ô H3 có điểm phù hợp cao nhất. Bạn có thể yêu cầu thêm thông tin chi tiết về từng địa điểm.
Bạn có thể thực hiện việc này bằng cách gửi trực tiếp một yêu cầu đến Place Details API cho từng Mã địa điểm hoặc sử dụng Client Library để thực hiện lệnh gọi. Hãy nhớ đặt tham số FieldMask để chỉ yêu cầu dữ liệu bạn cần.
Cuối cùng, chúng tôi kết hợp mọi thứ thành một hình ảnh trực quan duy nhất và mạnh mẽ. Chúng tôi vẽ bản đồ chuyên đề về mức độ phù hợp màu tím làm lớp cơ sở, sau đó thêm các ghim cho từng quán cà phê riêng lẻ được truy xuất từ Places API. Bản đồ cuối cùng này cung cấp chế độ Xem nhanh, tổng hợp toàn bộ Phân tích của chúng tôi: các khu vực màu tím đậm cho thấy tiềm năng và các ghim màu xanh lục cho thấy thực tế của thị trường hiện tại.
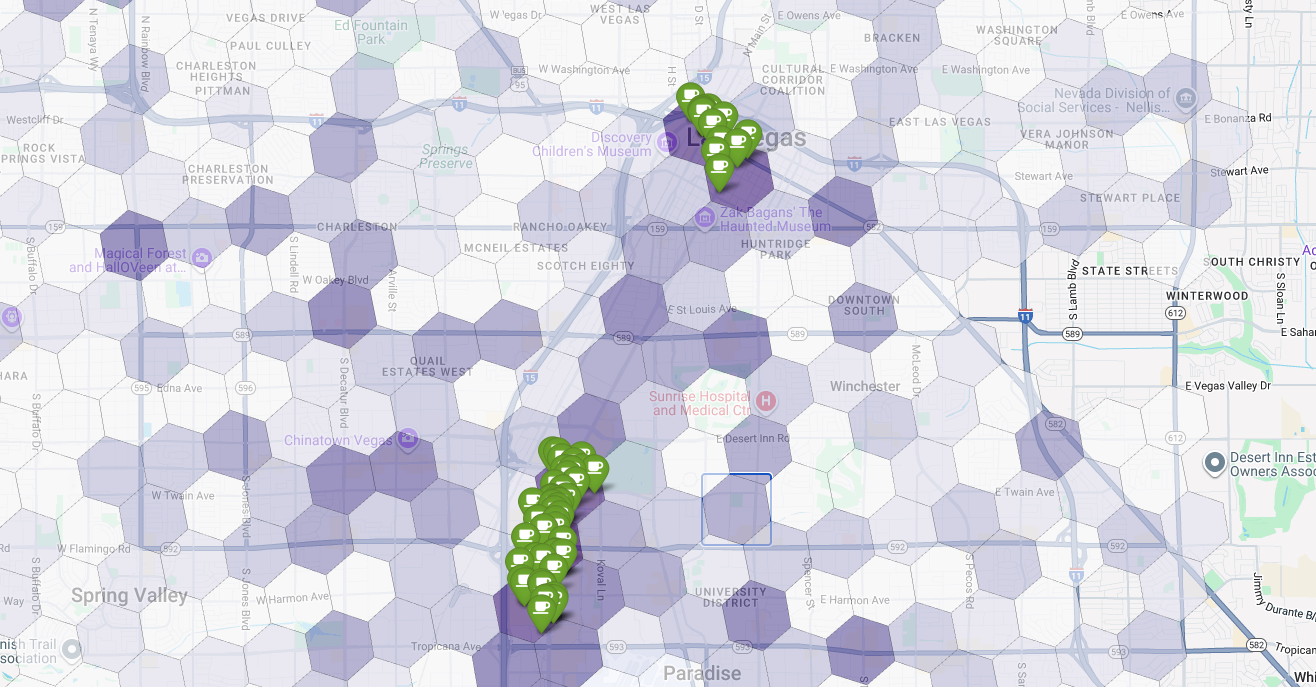
Bằng cách tìm kiếm các ô màu tím sẫm có ít hoặc không có ghim, chúng ta có thể tự tin xác định chính xác những khu vực có cơ hội tốt nhất cho vị trí mới của mình.
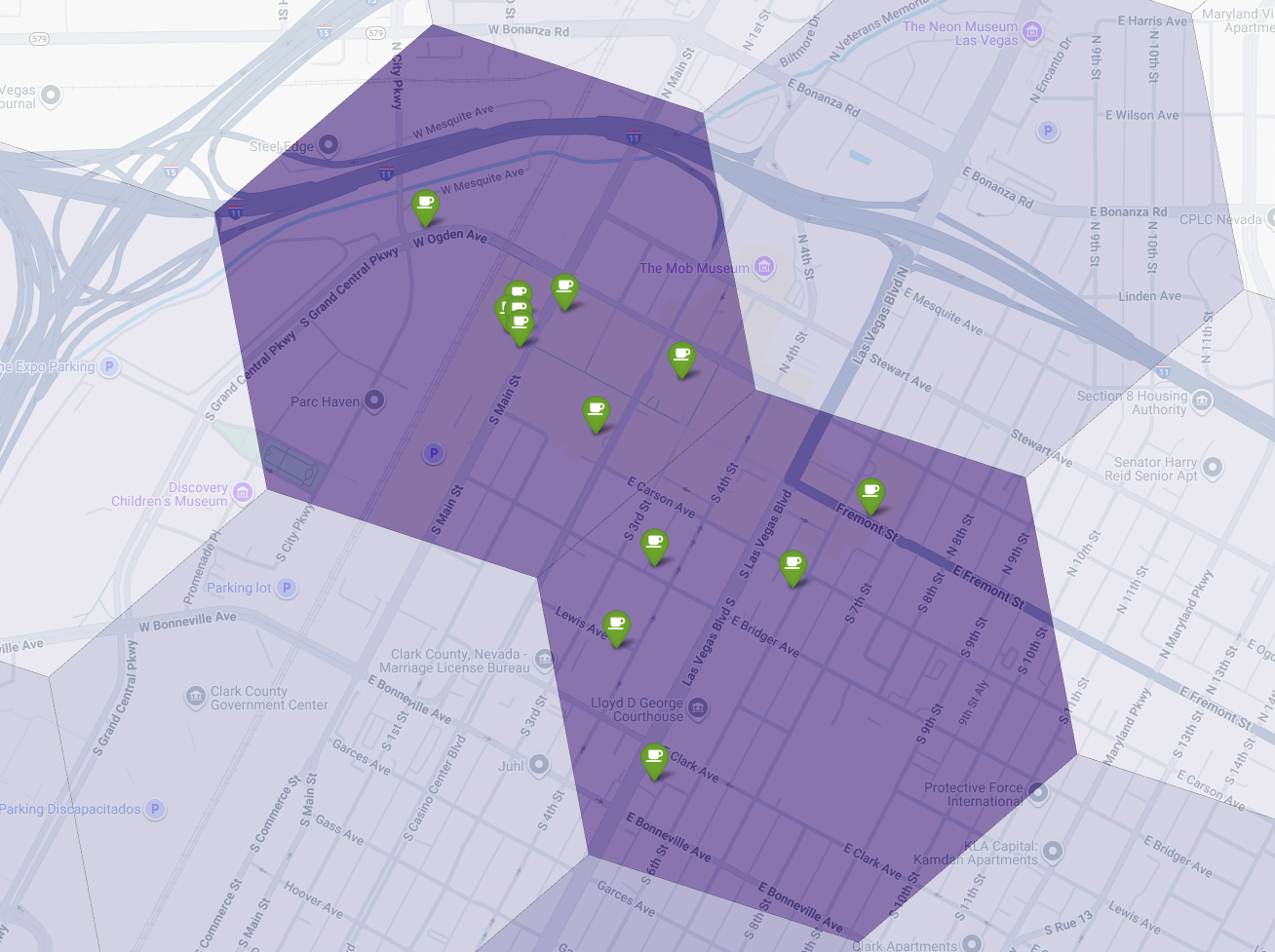
Hai ô trên có điểm phù hợp cao, nhưng có một số khoảng trống rõ ràng có thể là vị trí tiềm năng cho quán cà phê mới của chúng ta.
Kết luận
Trong tài liệu này, chúng tôi đã chuyển từ câu hỏi trên toàn tiểu bang là nên mở rộng ở đâu? sang câu trả lời dựa trên dữ liệu ở địa phương. Bằng cách xếp lớp các tập dữ liệu khác nhau và áp dụng logic kinh doanh tuỳ chỉnh, bạn có thể giảm thiểu một cách có hệ thống rủi ro liên quan đến một quyết định kinh doanh quan trọng. Quy trình này, kết hợp quy mô của BigQuery, sự phong phú của Thông tin chi tiết về địa điểm và thông tin chi tiết theo thời gian thực của Places API, cung cấp một mẫu mạnh mẽ cho mọi tổ chức muốn sử dụng vị trí thông minh để tăng trưởng chiến lược.
Các bước tiếp theo
- Điều chỉnh quy trình này cho phù hợp với logic nghiệp vụ, các khu vực địa lý mục tiêu và tập dữ liệu độc quyền của bạn.
- Khám phá các trường dữ liệu khác trong tập dữ liệu Thông tin chi tiết về địa điểm, chẳng hạn như số lượng bài đánh giá, mức giá và điểm xếp hạng của người dùng, để làm phong phú thêm mô hình của bạn.
- Tự động hoá quy trình này để tạo một trang tổng quan lựa chọn trang web nội bộ có thể dùng để đánh giá các thị trường mới một cách linh hoạt.
Tìm hiểu kỹ hơn trong tài liệu:
- Tổng quan về Thông tin chi tiết về địa điểm
- Các hàm của Thông tin chi tiết về địa điểm
- Phân tích không gian địa lý trong BigQuery
- Places API
Người đóng góp
Henrik Valve | Kỹ sư DevX