
Введение
В этом документе описывается, как создать решение для выбора места размещения, объединив набор данных Places Insights , общедоступные геопространственные данные в BigQuery и API Place Details .
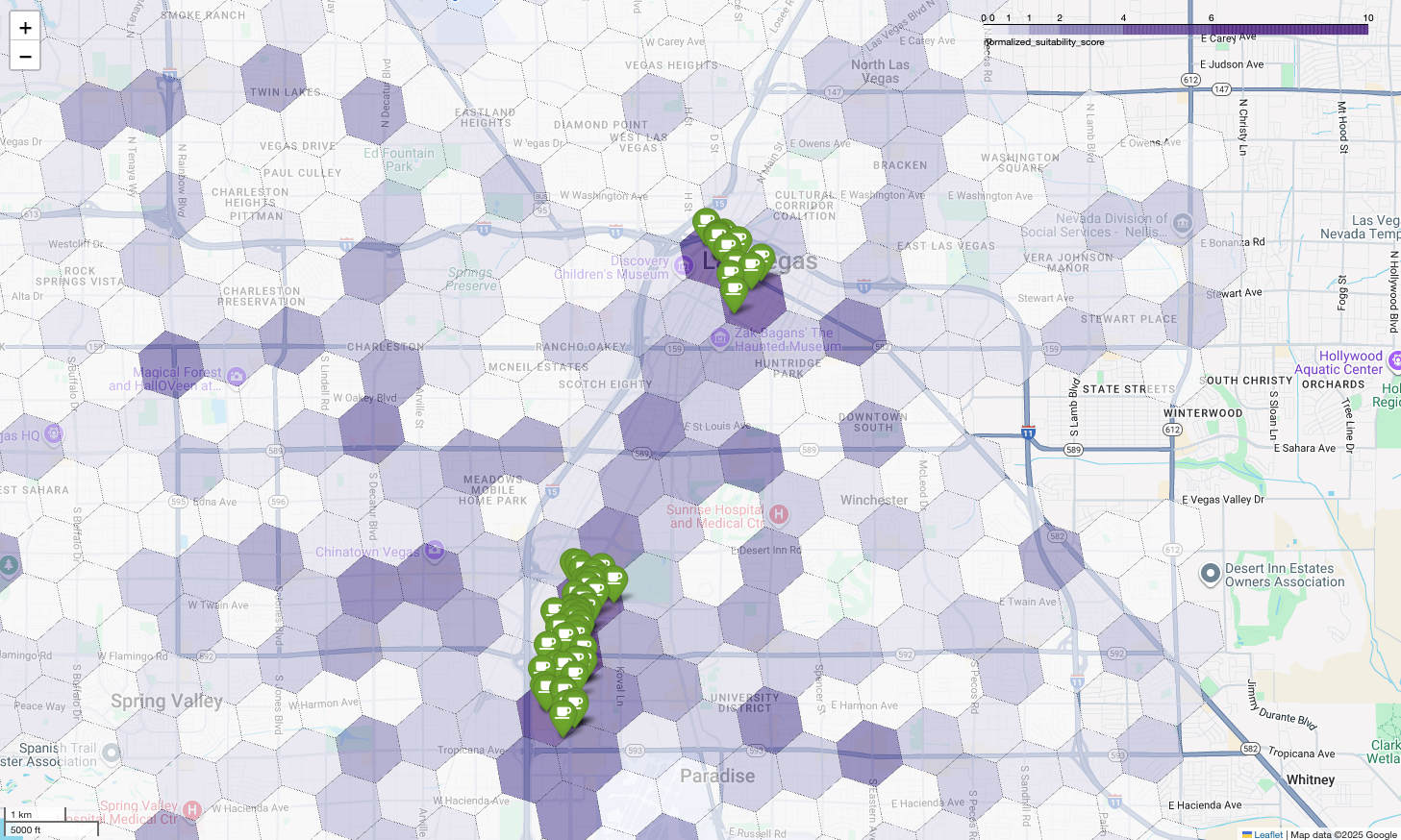
Приведенная выше карта иллюстрирует результаты демонстрации, представленной на конференции Google Cloud Next 2025, которую можно посмотреть на YouTube . Вы можете запустить код, использованный для получения этих результатов, с помощью примера в блокноте.
 Посмотреть исходный код на GitHub
Посмотреть исходный код на GitHubБизнес-вызов
Представьте, что вы владеете успешной сетью кофеен и хотите расшириться в новый штат, например, в Неваду, где у вас нет представительства. Открытие нового заведения — это значительные инвестиции, и принятие решения на основе данных имеет решающее значение для успеха. С чего же начать?
В этом руководстве вы найдете многоуровневый анализ, который поможет определить оптимальное место для новой кофейни. Мы начнем с обзора ситуации в масштабах штата, постепенно сузим поиск до конкретного округа и коммерческой зоны, и, наконец, проведем гиперлокальный анализ, чтобы оценить отдельные районы и выявить рыночные ниши, составив карту конкурентов.
Рабочий процесс решения
Этот процесс следует логической воронке, начиная с широкого поиска и постепенно переходя к более детальному определению области поиска для повышения уверенности в окончательном выборе места.
Предварительные условия и настройка среды
Прежде чем приступить к анализу, вам потребуется среда с несколькими ключевыми возможностями. Хотя в этом руководстве будет рассмотрена реализация с использованием SQL и Python, общие принципы могут быть применены и к другим технологическим стекам.
В качестве предварительного условия убедитесь, что ваша среда может:
- Выполняйте запросы в BigQuery.
- Для доступа к Places Insights см. раздел «Настройка Places Insights» для получения дополнительной информации.
- Подпишитесь на общедоступные наборы данных из
bigquery-public-dataи базы данных Бюро переписи населения США по численности населения округов.
Также необходимо уметь визуализировать геопространственные данные на карте, что крайне важно для интерпретации результатов каждого этапа анализа. Существует множество способов это сделать. Можно использовать инструменты бизнес-аналитики, такие как Looker Studio , которые напрямую подключаются к BigQuery, или языки программирования для анализа данных, например Python.
Анализ на уровне штата: найдите лучший округ
Наш первый шаг — это всесторонний анализ для выявления наиболее перспективного округа в Неваде. Под перспективностью мы будем понимать сочетание высокой численности населения и высокой плотности существующих ресторанов, что свидетельствует о развитой культуре общественного питания.
Наш запрос BigQuery достигает этого, используя встроенные компоненты адресов, доступные в наборе данных Places Insights. Запрос подсчитывает рестораны, сначала фильтруя данные, чтобы включить только заведения в штате Невада, используя поле administrative_area_level_1_name . Затем он дополнительно уточняет этот набор, чтобы включить только те заведения, где массив types содержит « restaurant ». Наконец, он группирует эти результаты по названию округа ( administrative_area_level_2_name ), чтобы получить количество для каждого округа. Этот подход использует встроенную, предварительно индексированную структуру адресов набора данных.
В этом фрагменте показано, как мы объединяем геометрические данные по округам с данными Places Insights и фильтруем данные по определенному типу места, например, restaurant :
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Одного лишь подсчета количества ресторанов недостаточно; нам необходимо сбалансировать его с данными о населении, чтобы получить истинное представление о насыщенности рынка и возможностях. Мы будем использовать данные о населении из базы данных Бюро переписи населения США (County Population Totals) .
Для сравнения этих двух совершенно разных показателей (количество мест и большое число жителей) мы используем нормализацию методом минимакса. Этот метод масштабирует оба показателя до общего диапазона (от 0 до 1). Затем мы объединяем их в один normalized_score , присваивая каждому показателю 50% веса для сбалансированного сравнения.
Этот фрагмент демонстрирует основную логику расчета показателя. Он объединяет нормализованные данные о численности населения и количестве ресторанов:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
После выполнения полного запроса возвращается список округов, количество ресторанов, численность населения и нормализованный балл. Сортировка по параметру normalized_score DESC показывает, что округ Кларк является явным победителем и заслуживает дальнейшего изучения в качестве главного претендента.
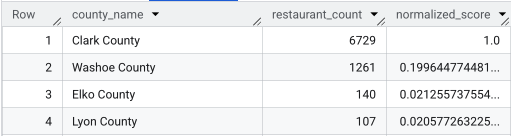
На этом скриншоте показаны 4 округа с наивысшим нормализованным баллом. Исходные данные о численности населения намеренно опущены в этом примере.
Анализ на уровне округов: определение самых оживленных коммерческих зон.
Теперь, когда мы определили округ Кларк, следующим шагом будет поиск почтовых индексов с наибольшей коммерческой активностью. На основе данных по существующим кофейням мы знаем, что показатели лучше, когда кофейни расположены рядом с большим количеством крупных брендов, поэтому мы будем использовать это как показатель высокой посещаемости.
Этот запрос использует таблицу brands в Places Insights, которая содержит информацию о конкретных брендах. С помощью запроса к этой таблице можно получить список поддерживаемых брендов. Сначала мы определяем список целевых брендов, а затем объединяем его с основным набором данных Places Insights, чтобы подсчитать, сколько таких магазинов находится в каждом почтовом индексе округа Кларк.
Наиболее эффективный способ достижения этой цели — двухэтапный подход:
- Сначала мы выполним быструю негеопространственную агрегацию, чтобы подсчитать количество брендов в каждом почтовом индексе.
- Во-вторых, мы объединим эти результаты с общедоступным набором данных , чтобы получить границы карты для визуализации.
Подсчет брендов с использованием поля postal_code_names
Первый запрос выполняет основную логику подсчета. Он фильтрует населенные пункты в округе Кларк, а затем разворачивает массив postal_code_names , чтобы сгруппировать количество брендов по почтовому индексу.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
В результате получается таблица почтовых индексов и соответствующих им данных о количестве брендов.
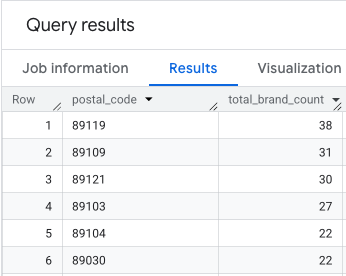
Прикрепите геометрические данные почтовых индексов для отображения на карте.
Теперь, когда у нас есть данные о количестве, мы можем получить необходимые для визуализации формы полигонов. Этот второй запрос берет наш первый запрос, оборачивает его в общее табличное выражение (CTE) с именем brand_counts_by_zip и объединяет его результаты с общедоступной geo_us_boundaries.zip_codes table . Это позволяет эффективно связать геометрию с нашими предварительно рассчитанными данными о количестве.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
В результате получается таблица почтовых индексов, количества соответствующих им брендов и геометрических данных почтового индекса.
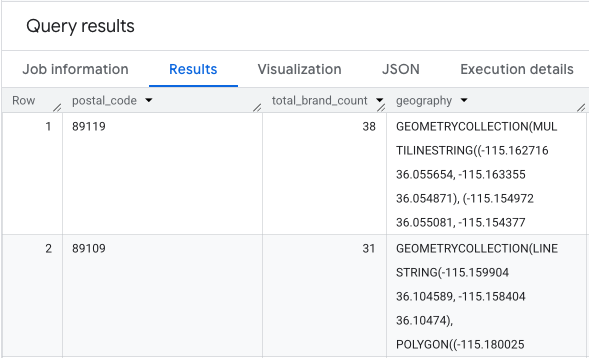
Эти данные можно визуализировать в виде тепловой карты. Более темные красные области указывают на более высокую концентрацию целевых брендов, что говорит о наиболее насыщенных коммерческой деятельностью районах Лас-Вегаса.
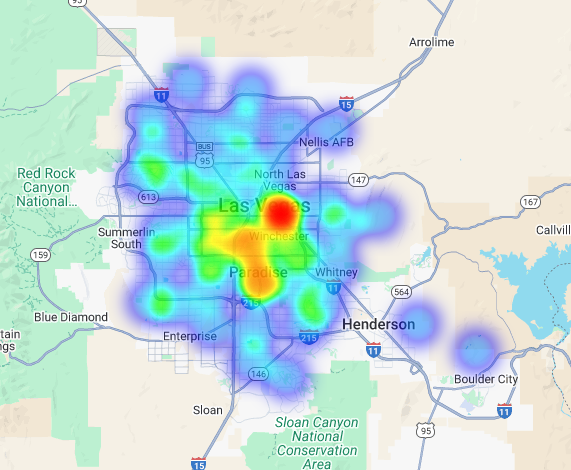
Гиперлокальный анализ: оценка отдельных участков сетки.
Определив общий район Лас-Вегаса, пришло время для детального анализа. Здесь мы используем наши специфические знания в области бизнеса. Мы знаем, что отличная кофейня процветает рядом с другими заведениями, которые загружены в часы пик, например, в конце утра и в обеденное время.
Следующий наш запрос становится действительно специфическим. Он начинается с создания мелкозернистой гексагональной сетки над агломерацией Лас-Вегаса с использованием стандартного геопространственного индекса H3 (с разрешением 8) для анализа территории на микроуровне. Запрос сначала определяет все дополнительные предприятия, работающие в пиковый период (понедельник, с 10:00 до 14:00).
Затем мы применяем взвешенный балл к каждому типу мест. Расположенный поблизости ресторан для нас ценнее, чем магазин товаров повседневного спроса, поэтому он получает более высокий множитель. Это позволяет нам получить индивидуальный suitability_score для каждого небольшого района.
В этом фрагменте показана логика взвешенного подсчета баллов, которая использует предварительно рассчитанный флаг ( is_open_monday_window ) для проверки часов работы:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Разверните для просмотра полного запроса.
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
Визуализация этих результатов на карте позволяет выявить очевидные выигрышные места. Самые тёмно-фиолетовые участки, расположенные в основном вблизи Лас-Вегас-Стрип и центра города, — это районы с наибольшим потенциалом для нашей новой кофейни.
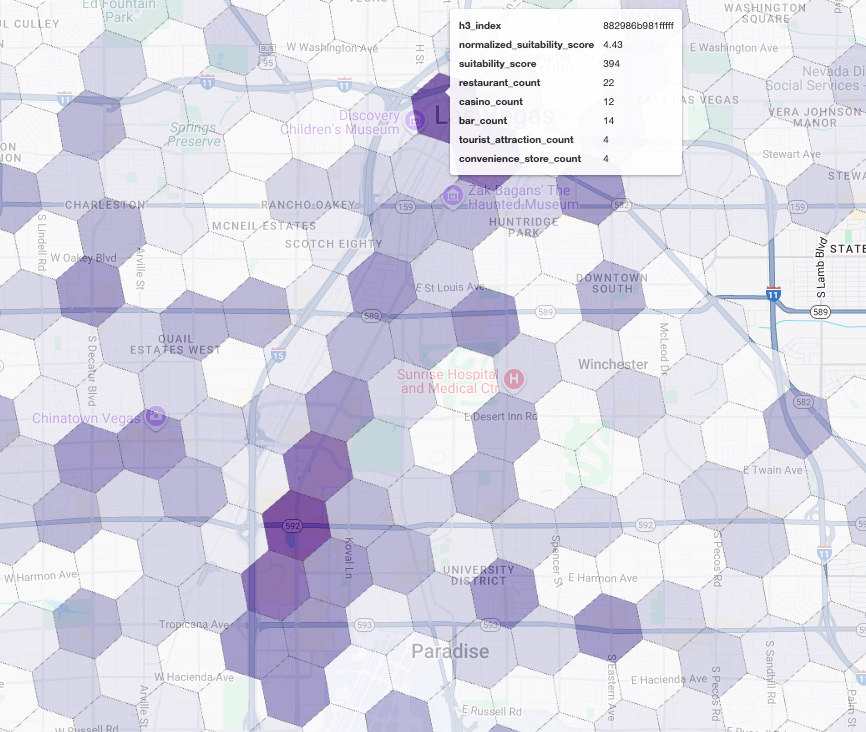
Анализ конкурентов: выявление существующих кофеен
Наша модель оценки пригодности успешно определила наиболее перспективные зоны, но одного высокого балла недостаточно для гарантии успеха. Теперь нам необходимо сопоставить эти данные с информацией о конкурентах. Идеальное место — это перспективный район с низкой плотностью существующих кофеен, поскольку мы ищем четкую рыночную нишу.
Для этого мы используем функцию PLACES_COUNT_PER_H3 . Эта функция предназначена для эффективного получения количества мест в указанном географическом регионе по ячейкам H3.
Во-первых, мы динамически определяем географию всей агломерации Лас-Вегаса. Вместо того чтобы полагаться на один конкретный населенный пункт, мы запрашиваем общедоступный набор данных Overture Maps, чтобы получить границы Лас-Вегаса и его ключевых окрестностей, объединяя их в один полигон с помощью ST_UNION_AGG . Затем мы передаем эту область в функцию, запрашивая подсчет всех действующих кофеен.
Этот запрос определяет область метрополии и вызывает функцию для получения количества кофеен в ячейках H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
Функция возвращает таблицу, содержащую индекс ячейки H3, её геометрию, общее количество кофеен и пример их идентификаторов мест (Place ID):
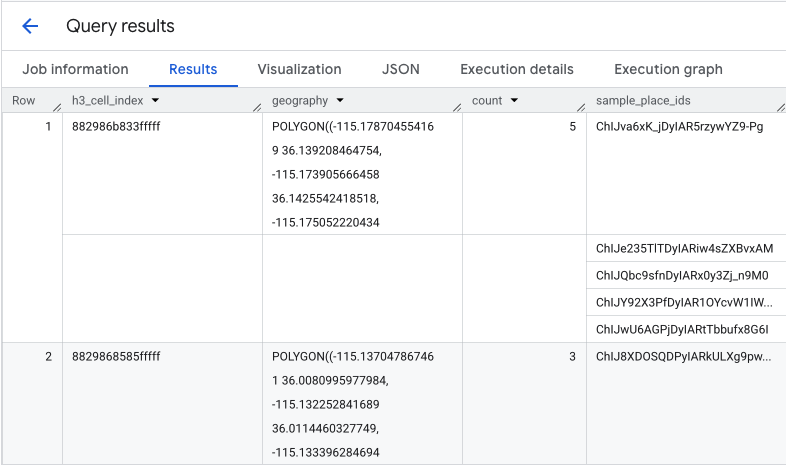
Хотя общий подсчет полезен, крайне важно видеть реальных конкурентов. Именно здесь мы переходим от набора данных Places Insights к Places API . Извлекая sample_place_ids из ячеек с наивысшим нормализованным показателем пригодности, мы можем вызвать Place Details API для получения подробной информации о каждом конкуренте, такой как его название, адрес, рейтинг и местоположение.
Для этого необходимо сравнить результаты предыдущего запроса, в котором был сгенерирован показатель пригодности, и запрос PLACES_COUNT_PER_H3 . Индекс ячейки H3 можно использовать для получения количества кофеен и их идентификаторов из ячеек с наивысшим нормализованным показателем пригодности.
Этот код на Python демонстрирует, как можно выполнить такое сравнение.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Теперь, когда у нас есть список идентификаторов мест (Place ID) для кофеен, которые уже существуют в ячейках H3 с наивысшим баллом соответствия, можно запросить более подробную информацию о каждом месте.
Это можно сделать либо отправив запрос непосредственно к API сведений о местах для каждого идентификатора места, либо используя клиентскую библиотеку для выполнения вызова. Не забудьте установить параметр FieldMask таким образом, чтобы запрашивались только необходимые данные.
Наконец, мы объединяем все данные в единую, эффективную визуализацию. В качестве базового слоя мы используем нашу фиолетовую хорплетную карту пригодности, а затем добавляем метки для каждой отдельной кофейни, полученные из Places API. Эта итоговая карта дает наглядное представление о результатах всего нашего анализа: темно-фиолетовые области показывают потенциал, а зеленые метки — реальное положение дел на рынке.
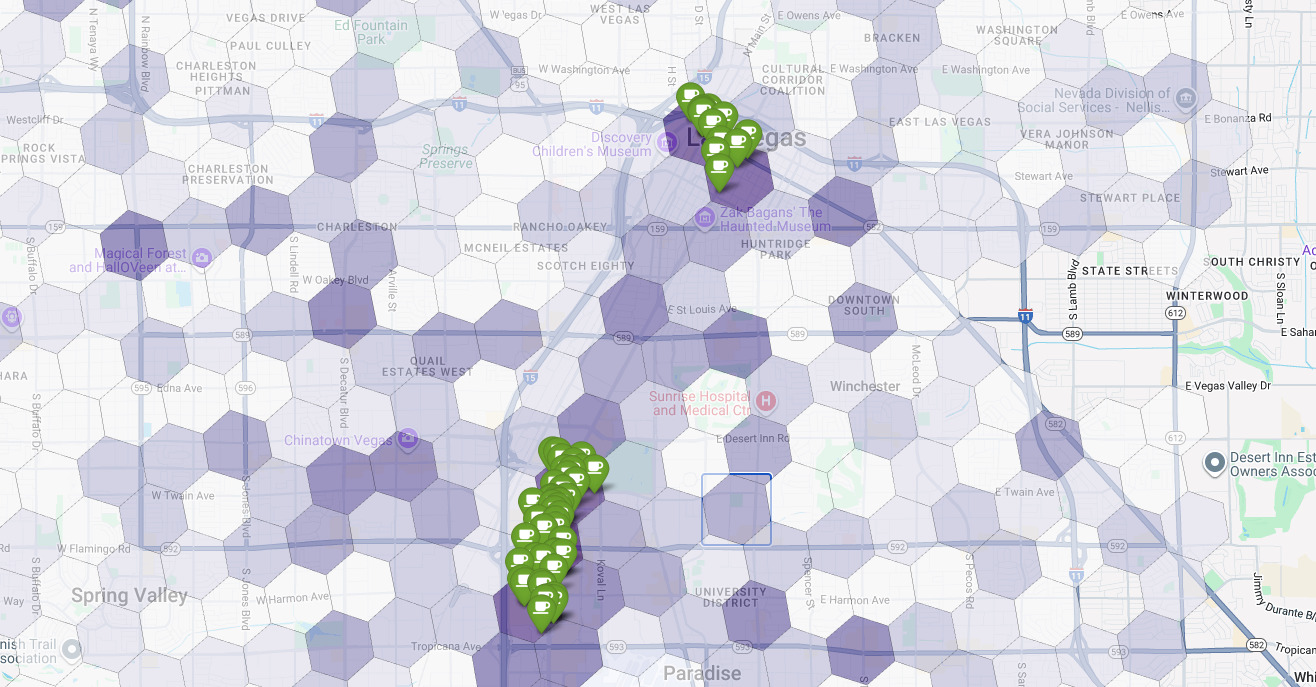
Ища темно-фиолетовые ячейки с небольшим количеством меток или без них, мы можем с уверенностью определить точные участки, представляющие наилучшие возможности для нашего нового местоположения.
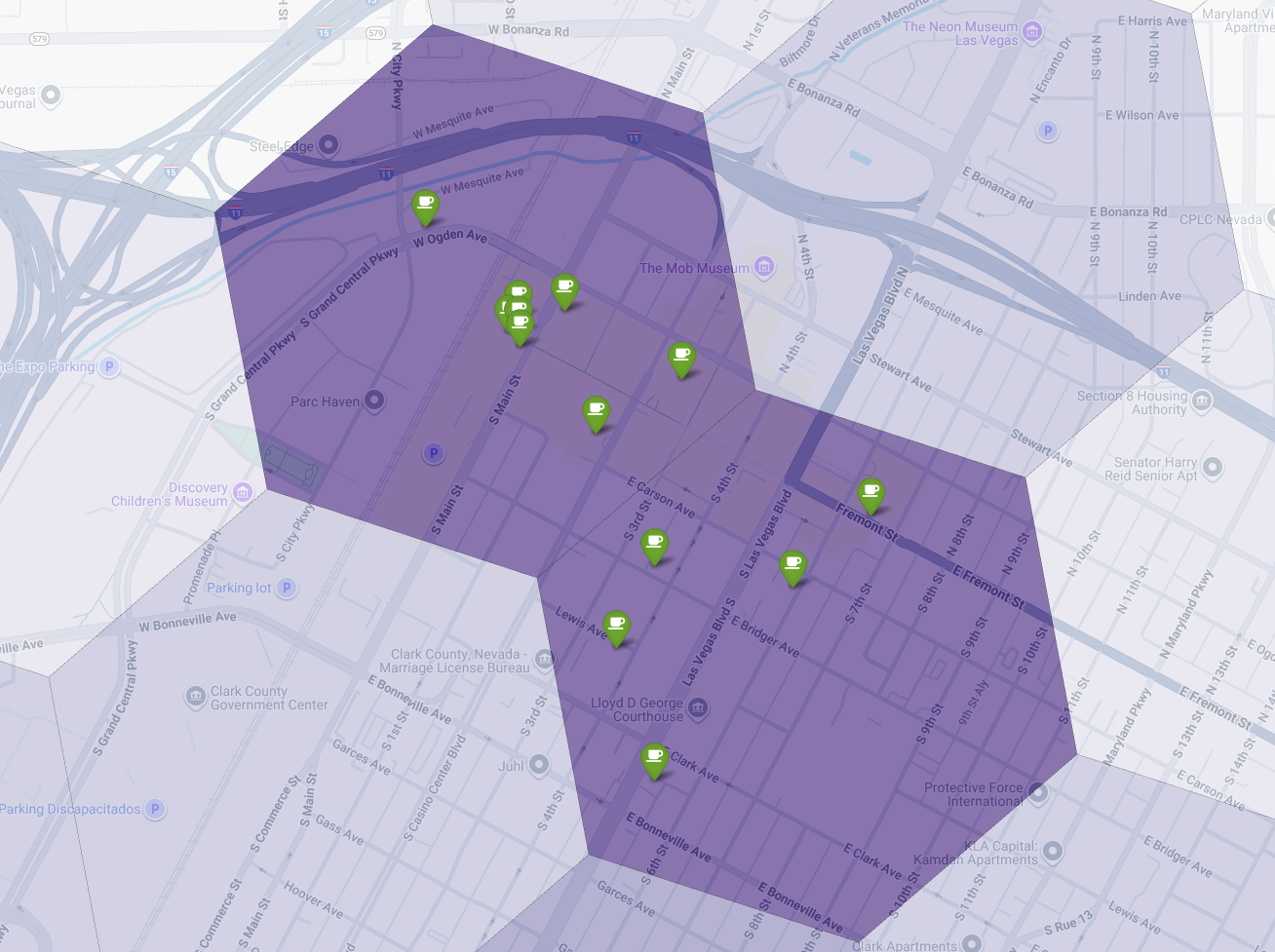
Указанные выше две ячейки имеют высокий показатель пригодности, но в них есть явные пробелы, которые могут стать потенциальными местами для нашей новой кофейни.
Заключение
В этом документе мы перешли от общенационального вопроса « где расширяться?» к основанному на данных локальному ответу. Наслаивая различные наборы данных и применяя собственную бизнес-логику, вы можете систематически снижать риски, связанные с принятием важных бизнес-решений. Этот рабочий процесс, сочетающий масштаб BigQuery, богатство Places Insights и детализацию в реальном времени от Places API, представляет собой мощный шаблон для любой организации, стремящейся использовать геолокационную аналитику для стратегического роста.
Следующие шаги
- Адаптируйте этот рабочий процесс под свою бизнес-логику, целевые географические регионы и собственные наборы данных.
- Изучите другие поля данных в наборе данных Places Insights, такие как количество отзывов, уровни цен и пользовательские рейтинги, чтобы еще больше обогатить вашу модель.
- Автоматизируйте этот процесс, чтобы создать внутреннюю панель мониторинга для выбора площадки, которую можно использовать для динамической оценки новых рынков.
Подробнее изучите документацию:
- Обзор аналитических данных о местах
- Функции анализа данных о местах
- Геопространственная аналитика BigQuery
- API мест
Авторы
Хенрик Вэлв | Инженер DevX