
Introduzione
Questo documento descrive come creare una soluzione di selezione del sito combinando il set di dati di Places Insights, dati geospaziali pubblici in BigQuery, e l'API Place Details.
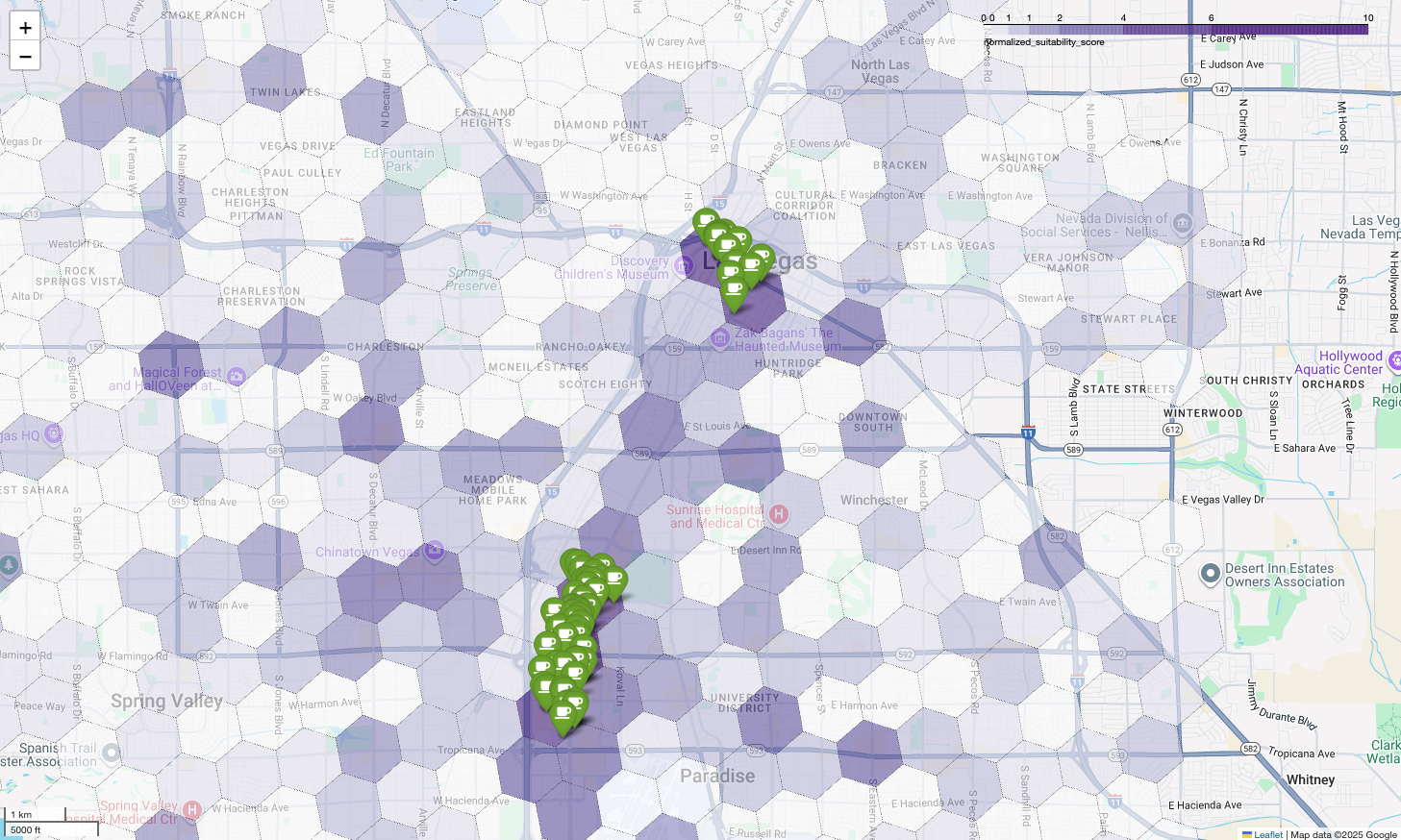
La mappa sopra illustra l'output di una demo presentata al Google Cloud Next 2025, che è disponibile per la visione su YouTube. Puoi eseguire il codice utilizzato per generare questi risultati utilizzando il notebook di esempio.
 Visualizza il codice sorgente su GitHub
Visualizza il codice sorgente su GitHub
La sfida aziendale
Immagina di possedere una catena di caffetterie di successo e di voler espanderti in un nuovo stato, come il Nevada, dove non hai una presenza. L'apertura di una nuova sede è un investimento significativo e prendere una decisione basata sui dati è fondamentale per il successo. Da dove si comincia?
Questa guida ti illustra un'analisi a più livelli per individuare la posizione ottimale per una nuova caffetteria. Inizieremo con una visualizzazione a livello statale, restringendo progressivamente la ricerca a una contea e a una zona commerciale specifiche e, infine, eseguiremo un'analisi iperlocale per valutare le singole aree e identificare le lacune del mercato mappando i concorrenti.
Flusso di lavoro della soluzione
Questo processo segue un funnel logico, partendo da un'analisi ampia e diventando progressivamente più granulare per perfezionare l'area di ricerca e aumentare la fiducia nella selezione finale del sito.
Prerequisiti e configurazione dell'ambiente
Prima di approfondire l'analisi, hai bisogno di un ambiente con alcune funzionalità chiave. Sebbene questa guida illustri un'implementazione utilizzando SQL e Python, i principi generali possono essere applicati ad altri stack tecnologici.
Come prerequisito, assicurati che il tuo ambiente possa:
- Eseguire query in BigQuery.
- Accedere a Places Insights. Per saperne di più, consulta Configurare Places Insights.
- Eseguire l'abbonamento ai set di dati pubblici di
bigquery-public-datae ai totali della popolazione della contea dell' Ufficio censimenti degli Stati Uniti.
Devi anche essere in grado di visualizzare i dati geospaziali su una mappa, il che è fondamentale per interpretare i risultati di ogni passaggio analitico. Esistono molti metodi per farlo. Puoi utilizzare strumenti di BI come Looker Studio che si connettono direttamente a BigQuery oppure puoi utilizzare linguaggi di data science come Python.
Analisi a livello statale: trovare la contea migliore
Il primo passaggio consiste in un'analisi ampia per identificare la contea più promettente del Nevada. Definiremo promettente una combinazione di popolazione elevata e un'alta densità di ristoranti esistenti, il che indica una forte cultura del settore alimentare e delle bevande.
La nostra query BigQuery esegue questa operazione sfruttando i componenti di indirizzo integrati disponibili nel set di dati di Places Insights. La query conta i ristoranti filtrando prima i dati in modo da includere solo i luoghi all'interno dello stato del Nevada, utilizzando il campo administrative_area_level_1_name. Poi, perfeziona ulteriormente questo set in modo da includere solo i luoghi in cui l'array dei tipi contiene "restaurant". Infine, raggruppa questi risultati per nome della contea (administrative_area_level_2_name) per produrre un conteggio per ogni contea. Questo approccio utilizza la struttura di indirizzi integrata e preindicizzata del set di dati.
Questo estratto mostra come unire le geometrie delle contee con Places Insights e filtrare per un tipo di luogo specifico, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Un conteggio grezzo dei ristoranti non è sufficiente. Dobbiamo bilanciarlo con i dati sulla popolazione per avere una vera idea della saturazione e delle opportunità del mercato. Utilizzeremo i dati sulla popolazione dei totali della popolazione della contea dell'Ufficio censimenti degli Stati Uniti.
Per confrontare queste due metriche molto diverse (un conteggio dei luoghi rispetto a un numero elevato di abitanti), utilizziamo la normalizzazione min-max. Questa tecnica ridimensiona entrambe le metriche a un intervallo comune (da 0 a 1). Poi, le combiniamo in un unico normalized_score, assegnando a ogni metrica una ponderazione del 50% per un confronto bilanciato.
Questo estratto mostra la logica principale per il calcolo del punteggio. Combina il conteggio normalizzato della popolazione e dei ristoranti:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Dopo aver eseguito la query completa, viene restituito un elenco delle contee, del conteggio dei ristoranti, della popolazione e del punteggio normalizzato. L'ordinamento per normalized_score
DESC rivela che la contea di Clark è la vincitrice indiscussa per ulteriori indagini come
principale contendente.
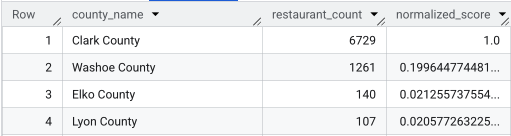
Questo screenshot mostra le prime quattro contee in base al punteggio normalizzato. Il conteggio grezzo della popolazione è stato volutamente omesso da questo esempio.
Analisi a livello di contea: trovare le zone commerciali più trafficate
Ora che abbiamo identificato la contea di Clark, il passaggio successivo consiste nell'ingrandire per trovare i codici postali con la maggiore attività commerciale. In base ai dati delle nostre caffetterie esistenti, sappiamo che il rendimento è migliore quando si trovano vicino a un'alta densità di brand importanti, quindi lo utilizzeremo come proxy per le visite nei punti vendita.
Questa query utilizza la tabella brands all'interno di Places Insights, che contiene informazioni su brand specifici. È possibile eseguire query su questa tabella per
scoprire l'elenco dei
brand supportati. Innanzitutto definiamo un elenco dei nostri brand target e poi lo uniamo al set di dati principale di Places Insights per contare quanti di questi negozi specifici rientrano in ogni codice postale della contea di Clark.
Il modo più efficiente per raggiungere questo obiettivo è un approccio in due passaggi:
- Innanzitutto, eseguiremo un'aggregazione rapida e non geospaziale per contare i brand all'interno di ogni codice postale.
- Poi, uniremo questi risultati a un set di dati pubblici per ottenere i limiti della mappa per la visualizzazione.
Contare i brand utilizzando il campo postal_code_names
Questa prima query esegue la logica di conteggio principale. Filtra i luoghi nella contea di Clark e poi annida l'array postal_code_names per raggruppare i conteggi dei brand per codice postale.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
L'output è una tabella di codici postali e i relativi conteggi dei brand.
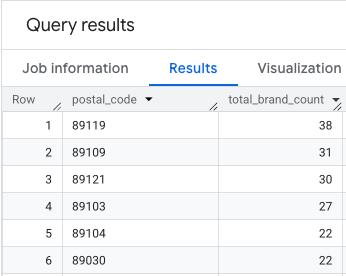
Allegare le geometrie dei codici postali per la mappatura
Ora che abbiamo i conteggi, possiamo ottenere le forme poligonali necessarie per la visualizzazione. Questa seconda query prende la prima query, la racchiude in un'espressione di tabella comune (CTE) denominata brand_counts_by_zip e unisce i risultati alla
tabella pubblica geo_us_boundaries.zip_codes table. In questo modo, la geometria viene allegata in modo efficiente ai conteggi precalcolati.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
L'output è una tabella di codici postali, i relativi conteggi dei brand e la geometria del codice postale.
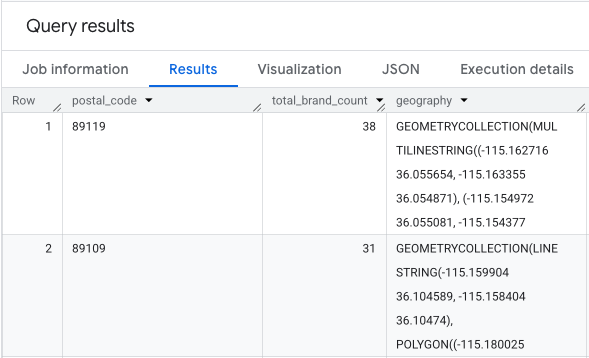
Possiamo visualizzare questi dati come una mappa termica. Le aree rosse più scure indicano una maggiore concentrazione dei nostri brand target, indirizzandoci verso le zone commerciali più dense di Las Vegas.
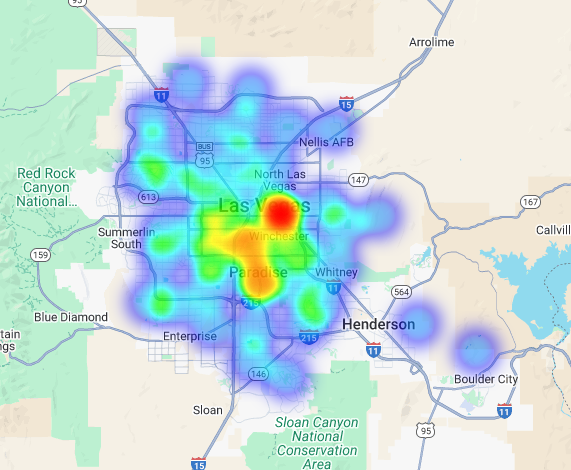
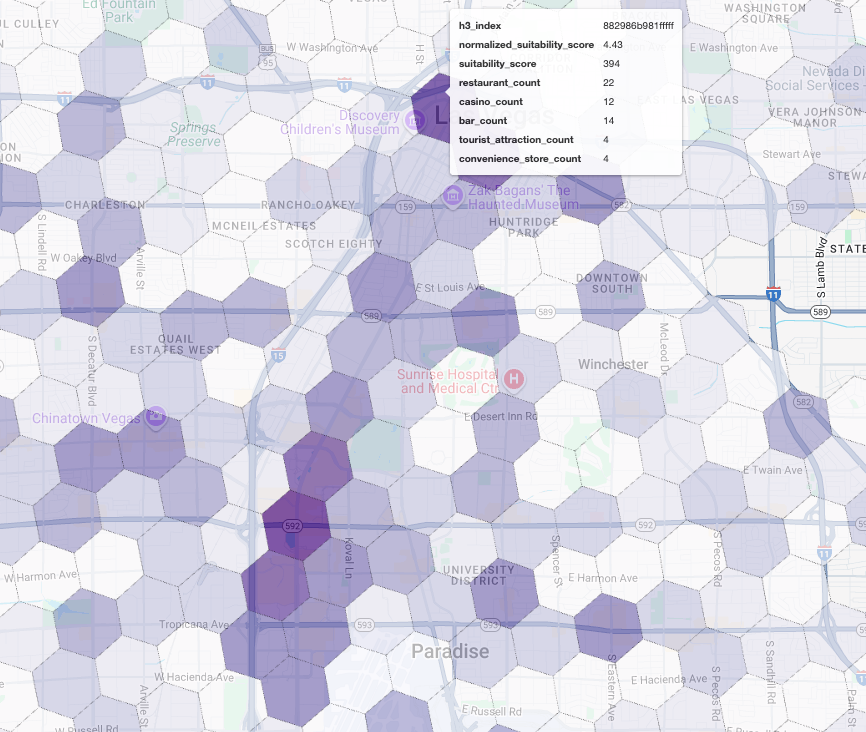
Analisi iperlocale: valutare le singole aree della griglia
Dopo aver identificato l'area generale di Las Vegas, è il momento di un'analisi granulare. È qui che inseriamo la nostra conoscenza aziendale specifica. Sappiamo che una buona caffetteria prospera vicino ad altre attività che sono trafficate durante le ore di punta, come la tarda mattinata e la pausa pranzo.
La query successiva è molto specifica. Inizia creando una griglia esagonale a grana fine sull'area metropolitana di Las Vegas utilizzando l'indice geospaziale H3 standard (con risoluzione 8) per analizzare l'area a livello micro. La query identifica innanzitutto tutte le attività complementari aperte durante la nostra finestra di punta (lunedì, dalle 10:00 alle 14:00).
Poi, applichiamo un punteggio ponderato a ogni tipo di luogo. Un ristorante nelle vicinanze è più prezioso per noi di un minimarket, quindi riceve un moltiplicatore più alto. In questo modo otteniamo un suitability_score personalizzato per ogni piccola area.
Questo estratto evidenzia la logica di punteggio ponderato, che fa riferimento a un flag precalcolato (is_open_monday_window) per il controllo degli orari di apertura:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Espandi per visualizzare la query completa
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
La visualizzazione di questi punteggi su una mappa rivela chiaramente le sedi vincenti. Le tessere viola più scure, principalmente vicino alla Las Vegas Strip e al centro città, sono le aree con il potenziale più elevato per la nostra nuova caffetteria.
Analisi della concorrenza: identificare le caffetterie esistenti
Il nostro modello di idoneità ha identificato correttamente le zone più promettenti, ma un punteggio elevato da solo non garantisce il successo. Ora dobbiamo sovrapporre questi dati con i dati dei concorrenti. La posizione ideale è un'area ad alto potenziale con una bassa densità di caffetterie esistenti, poiché stiamo cercando una chiara lacuna del mercato.
Per farlo, utilizziamo la
PLACES_COUNT_PER_H3
funzione. Questa funzione è progettata per restituire in modo efficiente i conteggi dei luoghi all'interno di una geografia specificata, per cella H3.
Innanzitutto, definiamo dinamicamente la geografia per l'intera area metropolitana di Las Vegas.
Anziché fare affidamento su una singola località, eseguiamo query sul set di dati pubblici di Overture Maps per ottenere i limiti di Las Vegas e delle principali località circostanti, unendoli in un unico poligono con ST_UNION_AGG. Poi, passiamo questa area alla funzione, chiedendole di contare tutte le caffetterie operative.
Questa query definisce l'area metropolitana e chiama la funzione per ottenere i conteggi delle caffetterie nelle celle H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
La funzione restituisce una tabella che include l'indice della cella H3, la relativa geometria, il conteggio totale delle caffetterie e un campione dei relativi ID luogo:
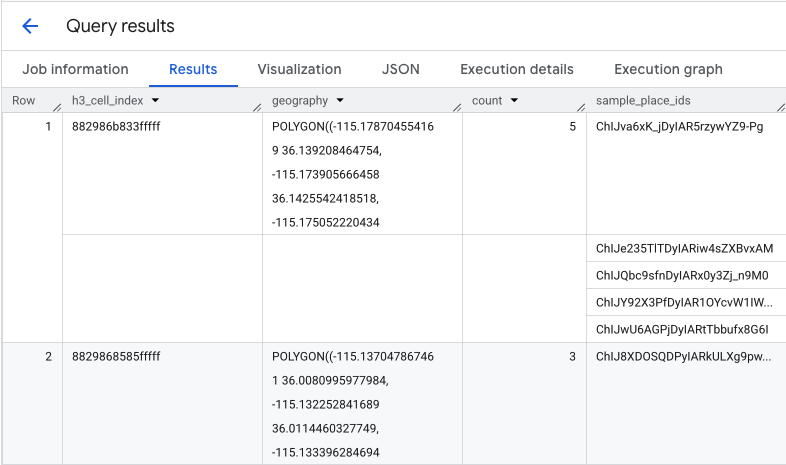
Sebbene il conteggio aggregato sia utile, è essenziale vedere i concorrenti effettivi.
È qui che passiamo dal set di dati di Places Insights all'API
Places. Estraendo i
sample_place_ids dalle celle con il punteggio di idoneità normalizzato più alto,
possiamo chiamare l'API
Place Details per recuperare dettagli completi per ogni concorrente, come nome, indirizzo, valutazione e posizione.
Per farlo, è necessario confrontare i risultati della query precedente, in cui è stato generato il punteggio di idoneità, e la query PLACES_COUNT_PER_H3. L'indice della cella H3 può essere utilizzato per ottenere i conteggi e gli ID delle caffetterie dalle celle con il punteggio di idoneità normalizzato più alto.
Questo codice Python mostra come eseguire questo confronto.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Ora che abbiamo l'elenco degli ID luogo delle caffetterie già esistenti all'interno delle celle H3 con il punteggio di idoneità più alto, è possibile richiedere ulteriori dettagli su ogni luogo.
Puoi farlo inviando una richiesta direttamente all'API Place Details
per ogni
ID luogo oppure utilizzando una libreria
client per eseguire la
chiamata. Ricorda di impostare il
FieldMask
parametro in modo da richiedere solo i dati di cui hai bisogno.
Infine, combiniamo tutto in un'unica e potente visualizzazione. Tracciamo la nostra mappa coropletica di idoneità viola come livello di base e poi aggiungiamo segnaposto per ogni singola caffetteria recuperata dall'API Places. Questa mappa finale fornisce una visualizzazione immediata che sintetizza l'intera analisi: le aree viola scuro mostrano il potenziale e i segnaposto verdi mostrano la realtà del mercato attuale.
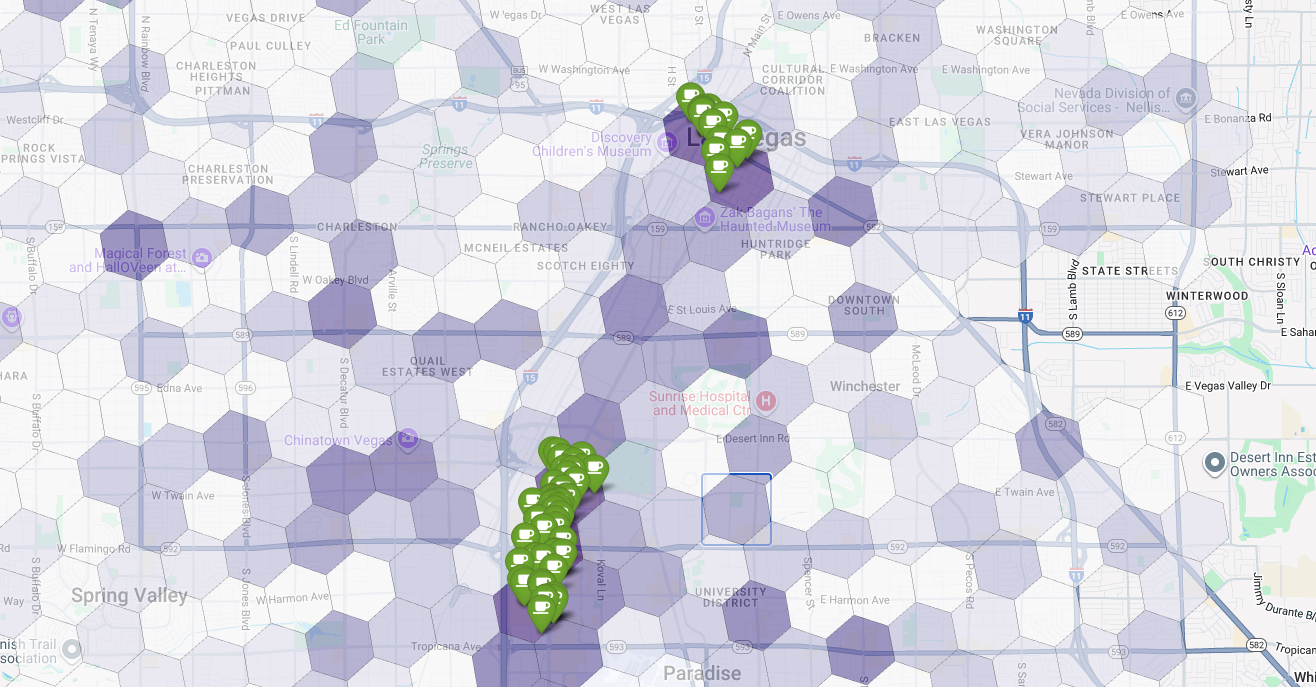
Cercando le celle viola scuro con pochi o nessun segnaposto, possiamo individuare con sicurezza le aree esatte che rappresentano la migliore opportunità per la nostra nuova sede.
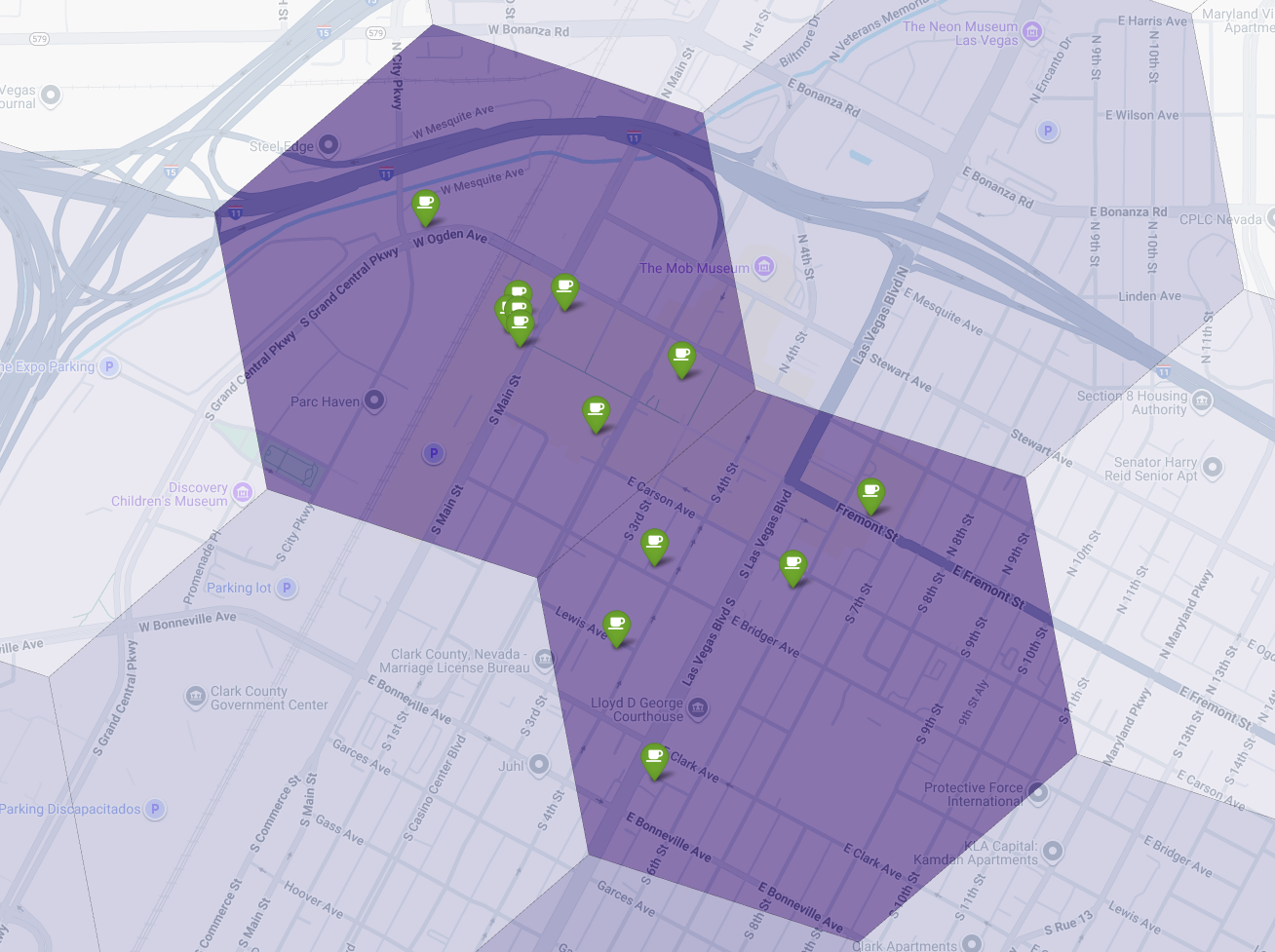
Le due celle sopra hanno un punteggio di idoneità elevato, ma alcune lacune evidenti che potrebbero essere potenziali sedi per la nostra nuova caffetteria.
Conclusione
In questo documento, siamo passati da una domanda a livello statale dove espandersi? a una risposta locale basata sui dati. Combinando diversi set di dati e applicando una logica di business personalizzata, puoi ridurre sistematicamente il rischio associato a una decisione aziendale importante. Questo workflow, che combina la scalabilità di BigQuery, la ricchezza di Places Insights e i dettagli in tempo reale dell'API Places, fornisce un modello efficace per qualsiasi organizzazione che voglia utilizzare la location intelligence per la crescita strategica.
Passaggi successivi
- Adatta questo workflow con la tua logica di business, le aree geografiche target e i set di dati proprietari.
- Esplora altri campi di dati nel set di dati di Places Insights, come i conteggi delle recensioni, i livelli di prezzo e le valutazioni degli utenti, per arricchire ulteriormente il modello.
- Automatizza questo processo per creare una dashboard interna di selezione del sito che possa essere utilizzata per valutare dinamicamente i nuovi mercati.
Approfondisci la documentazione:
- Panoramica di Places Insights
- Funzioni di Places Insights
- Analisi geospaziale di BigQuery
- API Places
Collaboratori
Henrik Valve | Ingegnere DevX